Préface
Vous vous demandez peut-être qui nous sommes et pourquoi nous avons écrit ce livre.
À la fin du dernier livre de Harry, Test-Driven Development with Python (O’Reilly), il s’est retrouvé à se poser un tas de questions sur l’architecture, telles que : Quelle est la meilleure façon de structurer votre application pour qu’elle soit facile à tester ? Plus précisément, pour que votre logique métier centrale soit couverte par des tests unitaires, et pour que vous minimisiez le nombre de tests d’intégration et de bout en bout dont vous avez besoin ? Il a fait de vagues références à "Hexagonal Architecture" (Architecture Hexagonale) et "Ports and Adapters" (Ports et Adaptateurs) et "Functional Core, Imperative Shell" (Noyau Fonctionnel, Enveloppe Impérative), mais pour être honnête, il devrait admettre que ce n’étaient pas des choses qu’il comprenait vraiment ou qu’il avait pratiquées.
Et puis il a eu la chance de rencontrer Bob, qui a les réponses à toutes ces questions.
Bob est devenu architecte logiciel parce que personne d’autre dans son équipe ne le faisait. Il s’est avéré qu’il était plutôt mauvais dans ce domaine, mais lui a eu la chance de rencontrer Ian Cooper, qui lui a enseigné de nouvelles façons d’écrire et de penser le code.
Gérer la Complexité, Résoudre les Problèmes Métier
Nous travaillons tous deux pour MADE.com, une entreprise de commerce électronique européenne qui vend des meubles en ligne ; là-bas, nous appliquons les techniques de ce livre pour construire des systèmes distribués qui modélisent les problèmes métier du monde réel. Notre domaine d’exemple est le premier système que Bob a construit pour MADE, et ce livre est une tentative de mettre par écrit tout ce truc que nous devons enseigner aux nouveaux programmeurs lorsqu’ils rejoignent l’une de nos équipes.
MADE.com gère une chaîne d’approvisionnement mondiale de partenaires de fret et de fabricants. Pour maintenir les coûts bas, nous essayons d’optimiser la livraison de stock vers nos entrepôts afin de ne pas avoir de marchandises invendues qui traînent.
Idéalement, le canapé que vous voulez acheter arrivera au port le jour même où vous décidez de l’acheter, et nous le livrerons directement chez vous sans jamais le stocker. Avoir le bon timing est un exercice d’équilibre délicat lorsque les marchandises prennent trois mois pour arriver par porte-conteneurs. En chemin, les choses se cassent ou sont endommagées par l’eau, les tempêtes causent des retards inattendus, les partenaires logistiques manipulent mal les marchandises, la paperasse disparaît, les clients changent d’avis et modifient leurs commandes, et ainsi de suite.
Nous résolvons ces problèmes en construisant des logiciels intelligents représentant les types d’opérations qui se déroulent dans le monde réel afin de pouvoir automatiser autant que possible l’activité.
Pourquoi Python ?
Si vous lisez ce livre, nous n’avons probablement pas besoin de vous convaincre que Python est génial, donc la vraie question est "Pourquoi la communauté Python a-t-elle besoin d’un livre comme celui-ci ?" La réponse concerne la popularité et la maturité de Python : bien que Python soit probablement le langage de programmation à la croissance la plus rapide au monde et s’approche du sommet des tableaux de popularité absolue, il ne fait que commencer à prendre en charge les types de problèmes sur lesquels le monde C# et Java travaille depuis des années. Les startups deviennent de vraies entreprises ; les applications web et les automatisations scriptées deviennent (chuchotons-le) des logiciels d’entreprise.
Dans le monde Python, nous citons souvent le Zen de Python : "Il devrait y avoir une—et de préférence une seule—manière évidente de le faire."[1] Malheureusement, à mesure que la taille du projet augmente, la manière la plus évidente de faire les choses n’est pas toujours celle qui vous aide à gérer la complexité et l’évolution des exigences.
Aucune des techniques et patterns dont nous discutons dans ce livre n’est nouvelle, mais elles sont pour la plupart nouvelles dans le monde Python. Et ce livre n’est pas un remplacement des classiques du domaine tels que le Domain-Driven Design d’Eric Evans ou les Patterns of Enterprise Application Architecture de Martin Fowler (tous deux publiés par Addison-Wesley Professional)—que nous référençons souvent et vous encourageons à aller lire.
Mais tous les exemples de code classiques de la littérature ont tendance à être écrits en Java ou C++/#, et si vous êtes une personne Python et n’avez pas utilisé l’un de ces langages depuis longtemps (ou même jamais), ces listings de code peuvent être assez…éprouvants. Il y a une raison pour laquelle la dernière édition de cet autre texte classique, le Refactoring de Fowler (Addison-Wesley Professional), est en JavaScript.
TDD, DDD, et Architecture Événementielle
Par ordre de notoriété, nous connaissons trois outils pour gérer la complexité :
-
Le Développement Piloté par les Tests (Test-driven development - TDD) nous aide à construire du code correct et nous permet de refactoriser ou d’ajouter de nouvelles fonctionnalités, sans crainte de régression. Mais il peut être difficile de tirer le meilleur parti de nos tests : Comment nous assurer qu’ils s’exécutent aussi rapidement que possible ? Que nous obtenons autant de couverture et de retour de tests unitaires rapides et sans dépendances et avons le minimum de tests de bout en bout plus lents et instables ?
-
La Conception Pilotée par le Domaine (Domain-driven design - DDD) nous demande de concentrer nos efforts sur la construction d’un bon modèle du domaine métier, mais comment nous assurer que nos modèles ne sont pas encombrés de préoccupations d’infrastructure et ne deviennent pas difficiles à modifier ?
-
Les (micro)services faiblement couplés intégrés via des messages (parfois appelés microservices réactifs) sont une réponse bien établie à la gestion de la complexité à travers plusieurs applications ou domaines métier. Mais il n’est pas toujours évident de les faire fonctionner avec les outils établis du monde Python—Flask, Django, Celery, et ainsi de suite.
| Ne soyez pas découragé si vous ne travaillez pas avec (ou n’êtes pas intéressé par) les microservices. La grande majorité des patterns dont nous discutons, y compris une grande partie du matériel sur l’architecture événementielle, est absolument applicable dans une architecture monolithique. |
Notre objectif avec ce livre est d’introduire plusieurs patterns architecturaux classiques et de montrer comment ils soutiennent TDD, DDD, et les services événementiels. Nous espérons qu’il servira de référence pour les implémenter de manière Pythonique, et que les gens pourront l’utiliser comme première étape vers des recherches plus approfondies dans ce domaine.
Qui Devrait Lire Ce Livre
Voici quelques éléments que nous supposons vous concernant, cher lecteur :
-
Vous avez côtoyé des applications Python raisonnablement complexes.
-
Vous avez vu une partie de la douleur qui vient avec la tentative de gérer cette complexité.
-
Vous ne connaissez pas nécessairement quoi que ce soit sur DDD ou l’un des patterns d’architecture d’application classiques.
Nous structurons nos explorations des patterns architecturaux autour d’une application d’exemple, en la construisant chapitre par chapitre. Nous utilisons le TDD au travail, donc nous avons tendance à montrer d’abord les listings de tests, suivis de l’implémentation. Si vous n’êtes pas habitué à travailler en test-first, cela peut sembler un peu étrange au début, mais nous espérons que vous vous habituerez bientôt à voir le code "être utilisé" (c’est-à-dire, de l’extérieur) avant de voir comment il est construit à l’intérieur.
Nous utilisons certains frameworks et technologies Python spécifiques, notamment Flask, SQLAlchemy, et pytest, ainsi que Docker et Redis. Si vous êtes déjà familier avec eux, cela n’entravera pas, mais nous ne pensons pas que ce soit requis. L’un de nos principaux objectifs avec ce livre est de construire une architecture pour laquelle les choix technologiques spécifiques deviennent des détails d’implémentation mineurs.
Un Bref Aperçu de Ce Que Vous Apprendrez
Le livre est divisé en deux parties ; voici un aperçu des sujets que nous couvrirons et des chapitres dans lesquels ils se trouvent.
#part1
- Modélisation de domaine et DDD (Chapitres 1, 2 et 7)
-
À un certain niveau, tout le monde a appris la leçon que les problèmes métier complexes doivent être reflétés dans le code, sous la forme d’un modèle du domaine. Mais pourquoi semble-t-il toujours si difficile de le faire sans s’emmêler avec des préoccupations d’infrastructure, nos frameworks web, ou quoi que ce soit d’autre ? Dans le premier chapitre, nous donnons un aperçu large de la modélisation de domaine et du DDD, et nous montrons comment démarrer avec un modèle qui n’a pas de dépendances externes, et des tests unitaires rapides. Plus tard, nous revenons aux patterns DDD pour discuter de comment choisir le bon agrégat (aggregate), et comment ce choix se rapporte aux questions d’intégrité des données.
- Patterns Dépôt (Repository), Couche de Service (Service Layer), et Unité de Travail (Unit of Work) (Chapitres 2, 4, et 5)
-
Dans ces trois chapitres, nous présentons trois patterns étroitement liés et mutuellement renforçants qui soutiennent notre ambition de garder le modèle libre de dépendances superflues. Nous construisons une couche d’abstraction autour du stockage persistant, et nous construisons une couche de service pour définir les points d’entrée de notre système et capturer les cas d’usage principaux. Nous montrons comment cette couche facilite la construction de points d’entrée fins à notre système, que ce soit une API Flask ou un CLI.
- Quelques réflexions sur les tests et les abstractions (Chapitre 3 et 5)
-
Après avoir présenté la première abstraction (le pattern Dépôt - Repository), nous saisissons l’opportunité d’une discussion générale sur comment choisir les abstractions, et quel est leur rôle dans le choix de la manière dont notre logiciel est couplé. Après avoir introduit le pattern Couche de Service (Service Layer), nous parlons un peu d’atteindre une pyramide de tests et d’écrire des tests unitaires au niveau d’abstraction le plus élevé possible.
#part2
- Architecture événementielle (Chapitres 8-11)
-
Nous introduisons trois patterns supplémentaires mutuellement renforçants : les patterns Événements de Domaine (Domain Events), Bus de Messages (Message Bus), et Gestionnaire (Handler). Les événements de domaine sont un véhicule pour capturer l’idée que certaines interactions avec un système sont des déclencheurs pour d’autres. Nous utilisons un bus de messages pour permettre aux actions de déclencher des événements et d’appeler les gestionnaires appropriés. Nous poursuivons en discutant comment les événements peuvent être utilisés comme un pattern d’intégration entre services dans une architecture de microservices. Enfin, nous distinguons entre commandes et événements. Notre application est maintenant fondamentalement un système de traitement de messages.
- Ségrégation des responsabilités commande-requête (CQRS (Command Query Responsibility Segregation/Ségrégation des Responsabilités Commande-Requête))
-
Nous présentons un exemple de ségrégation des responsabilités commande-requête (command-query responsibility segregation), avec et sans événements.
- Injection de dépendances (Injection de Dépendances (Dependency Injection) (et Amorçage))
-
Nous rangeons nos dépendances explicites et implicites et implémentons un simple framework d’injection de dépendances.
Contenu Additionnel
- Comment y arriver à partir d’ici ? (Épilogue)
-
Implémenter des patterns architecturaux semble toujours facile lorsque vous montrez un exemple simple, en partant de zéro, mais beaucoup d’entre vous se demanderont probablement comment appliquer ces principes aux logiciels existants. Nous fournirons quelques pointeurs dans l’épilogue et quelques liens vers des lectures complémentaires.
Exemple de Code et Coder en Suivant
Vous lisez un livre, mais vous serez probablement d’accord avec nous lorsque nous disons que la meilleure façon d’apprendre sur le code est de coder. Nous avons appris la majeure partie de ce que nous savons en faisant du pair programming avec des gens, en écrivant du code avec eux, et en apprenant en faisant, et nous aimerions recréer cette expérience autant que possible pour vous dans ce livre.
En conséquence, nous avons structuré le livre autour d’un seul projet d’exemple (bien que nous lancions parfois d’autres exemples). Nous construirons ce projet au fur et à mesure de la progression des chapitres, comme si vous aviez fait du pair programming avec nous et que nous expliquions ce que nous faisons et pourquoi à chaque étape.
Mais pour vraiment saisir ces patterns, vous devez manipuler le code et avoir une idée de comment il fonctionne. Vous trouverez tout le code sur GitHub ; chaque chapitre a sa propre branche. Vous pouvez trouver une liste des branches sur GitHub également.
Voici trois façons dont vous pourriez coder en suivant le livre :
-
Démarrer votre propre dépôt et essayer de construire l’application comme nous le faisons, en suivant les exemples des listings du livre, et en regardant occasionnellement notre dépôt pour des indices. Un avertissement cependant : si vous avez lu le livre précédent de Harry et codé en suivant, vous constaterez que ce livre vous demande de comprendre davantage par vous-même ; vous devrez peut-être vous appuyer assez lourdement sur les versions fonctionnelles sur GitHub.
-
Essayer d’appliquer chaque pattern, chapitre par chapitre, à votre propre projet (de préférence petit/jouet), et voir si vous pouvez le faire fonctionner pour votre cas d’usage. C’est à haut risque/haute récompense (et beaucoup d’efforts en plus !). Cela peut prendre pas mal de travail pour faire fonctionner les choses pour les spécificités de votre projet, mais d’un autre côté, vous êtes susceptible d’apprendre le plus.
-
Pour moins d’effort, dans chaque chapitre nous décrivons un "Exercice pour le Lecteur," et vous pointons vers un emplacement GitHub où vous pouvez télécharger du code partiellement terminé pour le chapitre avec quelques parties manquantes à écrire vous-même.
Particulièrement si vous avez l’intention d’appliquer certains de ces patterns dans vos propres projets, travailler sur un exemple simple est un excellent moyen de pratiquer en toute sécurité.
Au strict minimum, faites un git checkout du code depuis notre dépôt pendant que vous
lisez chaque chapitre. Pouvoir plonger et voir le code dans le contexte d’une
application réellement fonctionnelle aidera à répondre à beaucoup de questions au fur et à mesure, et
rend tout plus réel. Vous trouverez des instructions sur comment faire cela
au début de chaque chapitre.
|
Licence
Le code (et la version en ligne du livre) est sous licence Creative Commons CC BY-NC-ND, ce qui signifie que vous êtes libre de le copier et de le partager avec qui vous voulez, à des fins non commerciales, tant que vous donnez l’attribution. Si vous voulez réutiliser une partie du contenu de ce livre et que vous avez des inquiétudes concernant la licence, contactez O’Reilly à permissions@oreilly.com.
L’édition imprimée est sous une licence différente ; veuillez consulter la page de copyright.
Conventions Utilisées dans Ce Livre
Les conventions typographiques suivantes sont utilisées dans ce livre :
- Italique
-
Indique de nouveaux termes, URL, adresses email, noms de fichiers et extensions de fichiers.
- Largeur constante
-
Utilisé pour les listings de programme, ainsi qu’à l’intérieur des paragraphes pour faire référence à des éléments de programme tels que des noms de variables ou de fonctions, bases de données, types de données, variables d’environnement, instructions et mots-clés.
Largeur constante gras-
Montre les commandes ou autre texte qui devrait être tapé littéralement par l’utilisateur.
- Largeur constante italique
-
Montre le texte qui devrait être remplacé par des valeurs fournies par l’utilisateur ou par des valeurs déterminées par le contexte.
|
Cet élément signifie un conseil ou une suggestion. |
|
Cet élément signifie une note générale. |
|
Cet élément indique un avertissement ou une mise en garde. |
O’Reilly Online Learning
|
Depuis plus de 40 ans, O'Reilly Media fournit des formations technologiques et commerciales, des connaissances et des insights pour aider les entreprises à réussir. |
Notre réseau unique d’experts et d’innovateurs partagent leurs connaissances et leur expertise à travers des livres, des articles, des conférences et notre plateforme d’apprentissage en ligne. La plateforme d’apprentissage en ligne d’O’Reilly vous donne un accès à la demande à des cours de formation en direct, des parcours d’apprentissage approfondis, des environnements de codage interactifs, et une vaste collection de textes et vidéos d’O’Reilly et de plus de 200 autres éditeurs. Pour plus d’informations, veuillez visiter http://oreilly.com.
Comment Contacter O’Reilly
Veuillez adresser les commentaires et questions concernant ce livre à l’éditeur :
- O'Reilly Media, Inc.
- 1005 Gravenstein Highway North
- Sebastopol, CA 95472
- 800-998-9938 (aux États-Unis ou au Canada)
- 707-829-0515 (international ou local)
- 707-829-0104 (fax)
Nous avons une page web pour ce livre, où nous listons les errata, exemples et toute information additionnelle. Vous pouvez accéder à cette page à https://oreil.ly/architecture-patterns-python.
Envoyez un email à bookquestions@oreilly.com pour commenter ou poser des questions techniques sur ce livre.
Pour plus d’informations sur nos livres, cours, conférences et actualités, consultez notre site web à http://www.oreilly.com.
Trouvez-nous sur Facebook : http://facebook.com/oreilly
Suivez-nous sur Twitter : http://twitter.com/oreillymedia
Regardez-nous sur YouTube : http://www.youtube.com/oreillymedia
Remerciements
À nos relecteurs techniques, David Seddon, Ed Jung, et Hynek Schlawack : nous ne vous méritons absolument pas. Vous êtes tous incroyablement dévoués, consciencieux, et rigoureux. Chacun de vous est immensément intelligent, et vos différents points de vue ont été à la fois utiles et complémentaires les uns aux autres. Merci du fond de nos cœurs.
Gigantesques remerciements également à tous nos lecteurs jusqu’à présent pour leurs commentaires et suggestions : Ian Cooper, Abdullah Ariff, Jonathan Meier, Gil Gonçalves, Matthieu Choplin, Ben Judson, James Gregory, Łukasz Lechowicz, Clinton Roy, Vitorino Araújo, Susan Goodbody, Josh Harwood, Daniel Butler, Liu Haibin, Jimmy Davies, Ignacio Vergara Kausel, Gaia Canestrani, Renne Rocha, pedroabi, Ashia Zawaduk, Jostein Leira, Brandon Rhodes, Jazeps Basko, simkimsia, Adrien Brunet, Sergey Nosko, et bien d’autres ; nos excuses si nous vous avons oublié sur cette liste.
Super-méga-merci à notre éditeur Corbin Collins pour ses encouragements gentils, et pour être un défenseur infatigable du lecteur. Remerciements tout aussi superlatifs au personnel de production, Katherine Tozer, Sharon Wilkey, Ellen Troutman-Zaig, et Rebecca Demarest, pour votre dévouement, professionnalisme, et attention au détail. Ce livre est incommensurablement amélioré grâce à vous.
Toutes erreurs restant dans le livre sont les nôtres, naturellement.
Introduction
Pourquoi Nos Conceptions Tournent-elles Mal ?
Qu’est-ce qui vous vient à l’esprit lorsque vous entendez le mot chaos ? Peut-être pensez-vous à une bourse bruyante, ou à votre cuisine le matin — tout est confus et en désordre. Lorsque vous pensez au mot ordre, peut-être imaginez-vous une pièce vide, sereine et calme. Pour les scientifiques, cependant, le chaos est caractérisé par l’homogénéité (uniformité), et l’ordre par la complexité (différence).
Par exemple, un jardin bien entretenu est un système hautement ordonné. Les jardiniers définissent des limites avec des chemins et des clôtures, et ils délimitent des plates-bandes ou des potagers. Au fil du temps, le jardin évolue, devenant plus riche et plus dense ; mais sans effort délibéré, le jardin deviendra sauvage. Les mauvaises herbes et les graminées étoufferont les autres plantes, recouvrant les chemins, jusqu’à ce que finalement chaque partie se ressemble à nouveau — sauvage et non gérée.
Les systèmes logiciels, eux aussi, tendent vers le chaos. Lorsque nous commençons à construire un nouveau système, nous avons de grandes idées selon lesquelles notre code sera propre et bien ordonné, mais au fil du temps, nous constatons qu’il accumule des scories et des cas particuliers et finit en un fouillis confus de classes gestionnaires et de modules utilitaires. Nous constatons que notre architecture en couches sensée s’est effondrée sur elle-même comme un diplomate trop imbibé. Les systèmes logiciels chaotiques sont caractérisés par une uniformité de fonction : des gestionnaires d’API qui ont des connaissances du domaine et envoient des emails et effectuent de la journalisation ; des classes de "logique métier" qui n’effectuent aucun calcul mais effectuent des E/S ; et tout est couplé à tout le reste de sorte que changer n’importe quelle partie du système devient périlleux. C’est si courant que les ingénieurs logiciels ont leur propre terme pour le chaos : l’anti-pattern Big Ball of Mud (Un diagramme de dépendances réel (source: "Enterprise Dependency: Big Ball of Yarn" par Alex Papadimoulis)).

| Une big ball of mud est l’état naturel du logiciel de la même manière que la nature sauvage est l’état naturel de votre jardin. Il faut de l’énergie et de la direction pour prévenir l’effondrement. |
Heureusement, les techniques pour éviter de créer une big ball of mud ne sont pas complexes.
Encapsulation et Abstractions
L’encapsulation et l’abstraction sont des outils que nous utilisons tous instinctivement en tant que programmeurs, même si nous n’utilisons pas tous ces mots exacts. Permettez-nous de nous y attarder un instant, car ils sont un thème récurrent du livre.
Le terme encapsulation couvre deux idées étroitement liées : simplifier le comportement et cacher les données. Dans cette discussion, nous utilisons le premier sens. Nous encapsulons le comportement en identifiant une tâche qui doit être effectuée dans notre code et en confiant cette tâche à un objet ou une fonction bien défini. Nous appelons cet objet ou cette fonction une abstraction.
Jetez un œil aux deux extraits de code Python suivants :
import json
from urllib.request import urlopen
from urllib.parse import urlencode
params = dict(q='Sausages', format='json')
handle = urlopen('http://api.duckduckgo.com' + '?' + urlencode(params))
raw_text = handle.read().decode('utf8')
parsed = json.loads(raw_text)
results = parsed['RelatedTopics']
for r in results:
if 'Text' in r:
print(r['FirstURL'] + ' - ' + r['Text'])import requests
params = dict(q='Sausages', format='json')
parsed = requests.get('http://api.duckduckgo.com/', params=params).json()
results = parsed['RelatedTopics']
for r in results:
if 'Text' in r:
print(r['FirstURL'] + ' - ' + r['Text'])Les deux listes de code font la même chose : elles soumettent des valeurs encodées sous forme de formulaire à une URL afin d’utiliser une API de moteur de recherche. Mais la seconde est plus simple à lire et à comprendre car elle opère à un niveau d’abstraction plus élevé.
Nous pouvons aller encore plus loin en identifiant et en nommant la tâche que nous voulons que le code effectue pour nous et en utilisant une abstraction de niveau encore plus élevé pour la rendre explicite :
import duckduckpy
for r in duckduckpy.query('Sausages').related_topics:
print(r.first_url, ' - ', r.text)Encapsuler le comportement en utilisant des abstractions est un outil puissant pour rendre le code plus expressif, plus testable et plus facile à maintenir.
| Dans la littérature du monde orienté objet (OO), l’une des caractérisations classiques de cette approche est appelée conception pilotée par les responsabilités ; elle utilise les mots rôles et responsabilités plutôt que tâches. Le point principal est de penser au code en termes de comportement, plutôt qu’en termes de données ou d’algorithmes.[2] |
La plupart des patterns de ce livre impliquent de choisir une abstraction, vous verrez donc de nombreux exemples dans chaque chapitre. De plus, Une Brève Digression : Sur le Couplage et les Abstractions discute spécifiquement de quelques heuristiques générales pour choisir des abstractions.
Stratification en Couches
L’encapsulation et l’abstraction nous aident en cachant les détails et en protégeant la cohérence de nos données, mais nous devons également prêter attention aux interactions entre nos objets et fonctions. Lorsqu’une fonction, un module ou un objet en utilise un autre, nous disons que l’un dépend de l’autre. Ces dépendances forment une sorte de réseau ou de graphe.
Dans une big ball of mud, les dépendances sont hors de contrôle (comme vous l’avez vu dans Un diagramme de dépendances réel (source: "Enterprise Dependency: Big Ball of Yarn" par Alex Papadimoulis)). Modifier un nœud du graphe devient difficile car cela a le potentiel d’affecter de nombreuses autres parties du système. Les architectures en couches sont une façon de s’attaquer à ce problème. Dans une architecture en couches, nous divisons notre code en catégories ou rôles discrets, et nous introduisons des règles sur les catégories de code qui peuvent s’appeler les unes les autres.
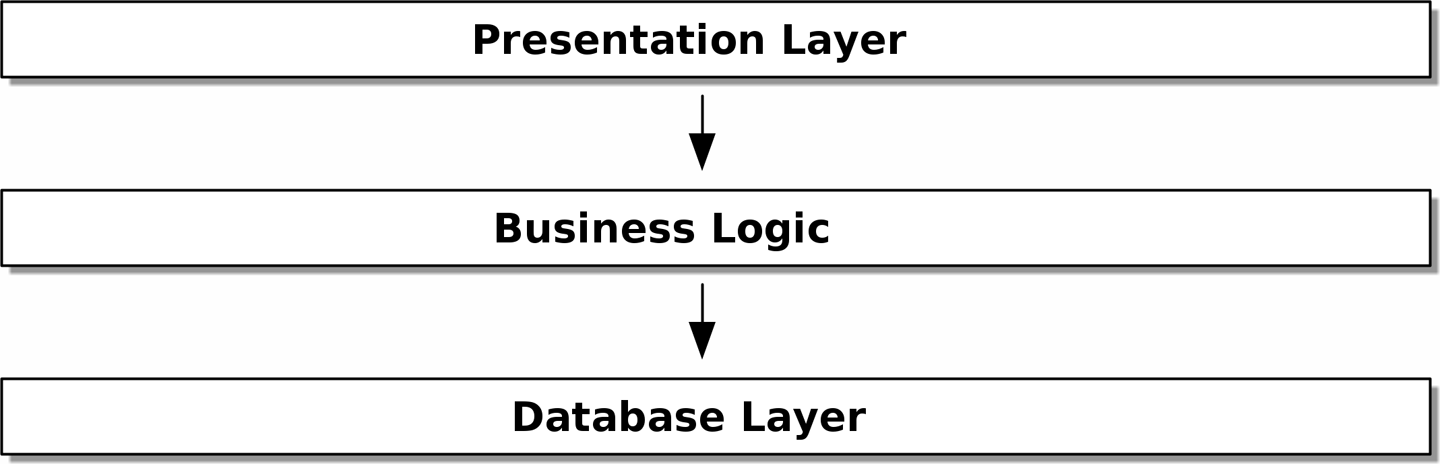
L’un des exemples les plus courants est l'architecture à trois couches illustrée dans Architecture en couches.
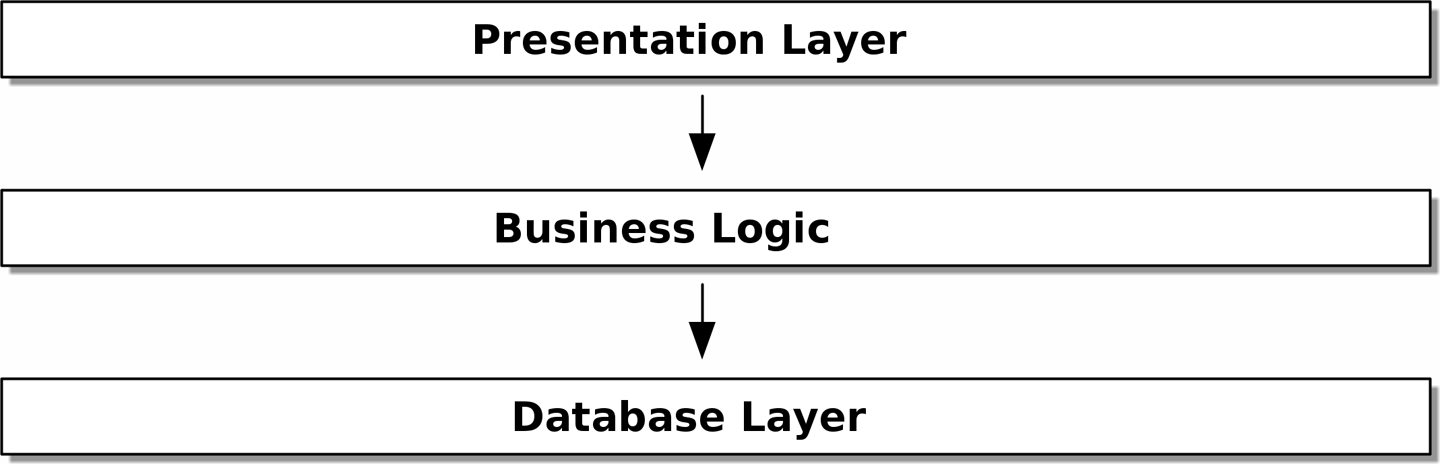
[ditaa, apwp_0002]
+----------------------------------------------------+
| Presentation Layer |
+----------------------------------------------------+
|
V
+----------------------------------------------------+
| Business Logic |
+----------------------------------------------------+
|
V
+----------------------------------------------------+
| Database Layer |
+----------------------------------------------------+
L’architecture en couches est peut-être le pattern le plus courant pour construire des logiciels d’entreprise. Dans ce modèle, nous avons des composants d’interface utilisateur, qui peuvent être une page web, une API ou une ligne de commande ; ces composants d’interface utilisateur communiquent avec une couche de logique métier qui contient nos règles métier et nos flux de travail ; et enfin, nous avons une couche de base de données qui est responsable du stockage et de la récupération des données.
Pour le reste de ce livre, nous allons systématiquement retourner ce modèle en obéissant à un principe simple.
Le Principe d’Inversion de Dépendance
Vous connaissez peut-être déjà le principe d’inversion de dépendance (Dependency Inversion Principle, DIP), car c’est le D de SOLID.[3]
Malheureusement, nous ne pouvons pas illustrer le DIP en utilisant trois petites listes de code comme nous l’avons fait pour l’encapsulation. Cependant, l’ensemble de la Construire une Architecture pour Supporter la Modélisation de Domaine est essentiellement un exemple détaillé d’implémentation du DIP dans une application, vous aurez donc votre dose d’exemples concrets.
En attendant, nous pouvons parler de la définition formelle du DIP :
-
Les modules de haut niveau ne devraient pas dépendre des modules de bas niveau. Les deux devraient dépendre d’abstractions.
-
Les abstractions ne devraient pas dépendre des détails. Au contraire, les détails devraient dépendre des abstractions.
Mais qu’est-ce que cela signifie ? Prenons-le morceau par morceau.
Les modules de haut niveau sont le code qui intéresse vraiment votre organisation. Peut-être travaillez-vous pour une société pharmaceutique, et vos modules de haut niveau traitent des patients et des essais. Peut-être travaillez-vous pour une banque, et vos modules de haut niveau gèrent des transactions et des échanges. Les modules de haut niveau d’un système logiciel sont les fonctions, classes et packages qui traitent de nos concepts du monde réel.
Par contraste, les modules de bas niveau sont le code qui n’intéresse pas votre organisation. Il est peu probable que votre département des ressources humaines soit enthousiaste à propos des systèmes de fichiers ou des sockets réseau. Ce n’est pas souvent que vous discutez de SMTP, HTTP ou AMQP avec votre équipe financière. Pour nos parties prenantes non techniques, ces concepts de bas niveau ne sont ni intéressants ni pertinents. Tout ce qui les intéresse, c’est de savoir si les concepts de haut niveau fonctionnent correctement. Si la paie fonctionne à temps, votre entreprise ne se soucie probablement pas de savoir s’il s’agit d’une tâche cron ou d’une fonction transitoire s’exécutant sur Kubernetes.
Dépend de ne signifie pas nécessairement importe ou appelle, mais plutôt une idée plus générale qu’un module connaît ou a besoin d’un autre module.
Et nous avons déjà mentionné les abstractions : ce sont des interfaces simplifiées qui encapsulent le comportement, de la façon dont notre module duckduckgo encapsulait l’API d’un moteur de recherche.
Tous les problèmes en informatique peuvent être résolus en ajoutant un autre niveau d’indirection.
Ainsi, la première partie du DIP dit que notre code métier ne devrait pas dépendre de détails techniques ; au lieu de cela, les deux devraient utiliser des abstractions.
Pourquoi ? Globalement, parce que nous voulons pouvoir les changer indépendamment l’un de l’autre. Les modules de haut niveau devraient être faciles à changer en réponse aux besoins métier. Les modules de bas niveau (détails) sont souvent, en pratique, plus difficiles à changer : pensez au refactoring pour changer un nom de fonction versus définir, tester et déployer une migration de base de données pour changer un nom de colonne. Nous ne voulons pas que les changements de logique métier ralentissent parce qu’ils sont étroitement couplés aux détails d’infrastructure de bas niveau. Mais, de même, il est important de pouvoir changer vos détails d’infrastructure quand vous en avez besoin (pensez au sharding d’une base de données, par exemple), sans avoir besoin d’apporter des modifications à votre couche métier. Ajouter une abstraction entre eux (le fameux niveau supplémentaire d’indirection) permet aux deux de changer (plus) indépendamment l’un de l’autre.
La deuxième partie est encore plus mystérieuse. "Les abstractions ne devraient pas dépendre des détails" semble assez clair, mais "Les détails devraient dépendre des abstractions" est difficile à imaginer. Comment pouvons-nous avoir une abstraction qui ne dépend pas des détails qu’elle abstrait ? Au moment où nous arrivons au Notre Premier Cas d’Usage (Use Case) : API Flask et Couche de Service (Service Layer), nous aurons un exemple concret qui devrait rendre tout cela un peu plus clair.
Un Endroit pour Toute Notre Logique Métier : Le Modèle de Domaine
Mais avant de pouvoir retourner notre architecture à trois couches, nous devons parler davantage de cette couche intermédiaire : les modules de haut niveau ou la logique métier. L’une des raisons les plus courantes pour lesquelles nos conceptions tournent mal est que la logique métier se retrouve dispersée dans les couches de notre application, ce qui rend difficile son identification, sa compréhension et sa modification.
Le Modélisation du Domaine montre comment construire une couche métier avec un pattern de Modèle de Domaine (Domain Model). Le reste des patterns de la Construire une Architecture pour Supporter la Modélisation de Domaine montre comment nous pouvons garder le Modèle de Domaine facile à changer et libre de préoccupations de bas niveau en choisissant les bonnes abstractions et en appliquant continuellement le DIP.
Construire une Architecture pour Supporter la Modélisation de Domaine
La plupart des développeurs n’ont jamais vu un modèle de domaine, seulement un modèle de données.
DDD EU 2017
La plupart des développeurs à qui nous parlons d’architecture ont le sentiment tenace que les choses pourraient être meilleures. Ils essaient souvent de sauver un système qui a mal tourné d’une manière ou d’une autre, et tentent de remettre de la structure dans une boule de boue. Ils savent que leur logique métier ne devrait pas être éparpillée partout, mais ils n’ont aucune idée de comment la corriger.
Nous avons constaté que de nombreux développeurs, lorsqu’on leur demande de concevoir un nouveau système, commenceront immédiatement à construire un schéma de base de données, avec le modèle objet traité comme une réflexion après coup. C’est là que tout commence à mal tourner. Au lieu de cela, le comportement devrait venir en premier et piloter nos exigences de stockage. Après tout, nos clients ne se soucient pas du modèle de données. Ils se soucient de ce que le système fait ; sinon ils utiliseraient simplement un tableur.
La première partie du livre examine comment construire un modèle objet riche à travers le TDD (dans le Modélisation du Domaine), puis nous montrerons comment garder ce modèle découplé des préoccupations techniques. Nous montrons comment construire du code ignorant la persistance et comment créer des APIs stables autour de notre domaine afin que nous puissions refactoriser de manière agressive.
Pour ce faire, nous présentons quatre patterns de conception clés :
-
Le pattern Dépôt (Repository), une abstraction sur l’idée de stockage persistant
-
Le pattern Couche de Service (Service Layer) pour définir clairement où nos cas d’usage commencent et se terminent
-
Le pattern Unité de Travail (Unit of Work) pour fournir des opérations atomiques
-
Le pattern Agrégat (Aggregate) pour faire respecter l’intégrité de nos données
Si vous aimeriez avoir une image de où nous allons, jetez un œil à Un diagramme de composants pour notre application à la fin de [part1], mais ne vous inquiétez pas si rien n’a de sens encore ! Nous introduisons chaque boîte dans la figure, une par une, tout au long de cette partie du livre.
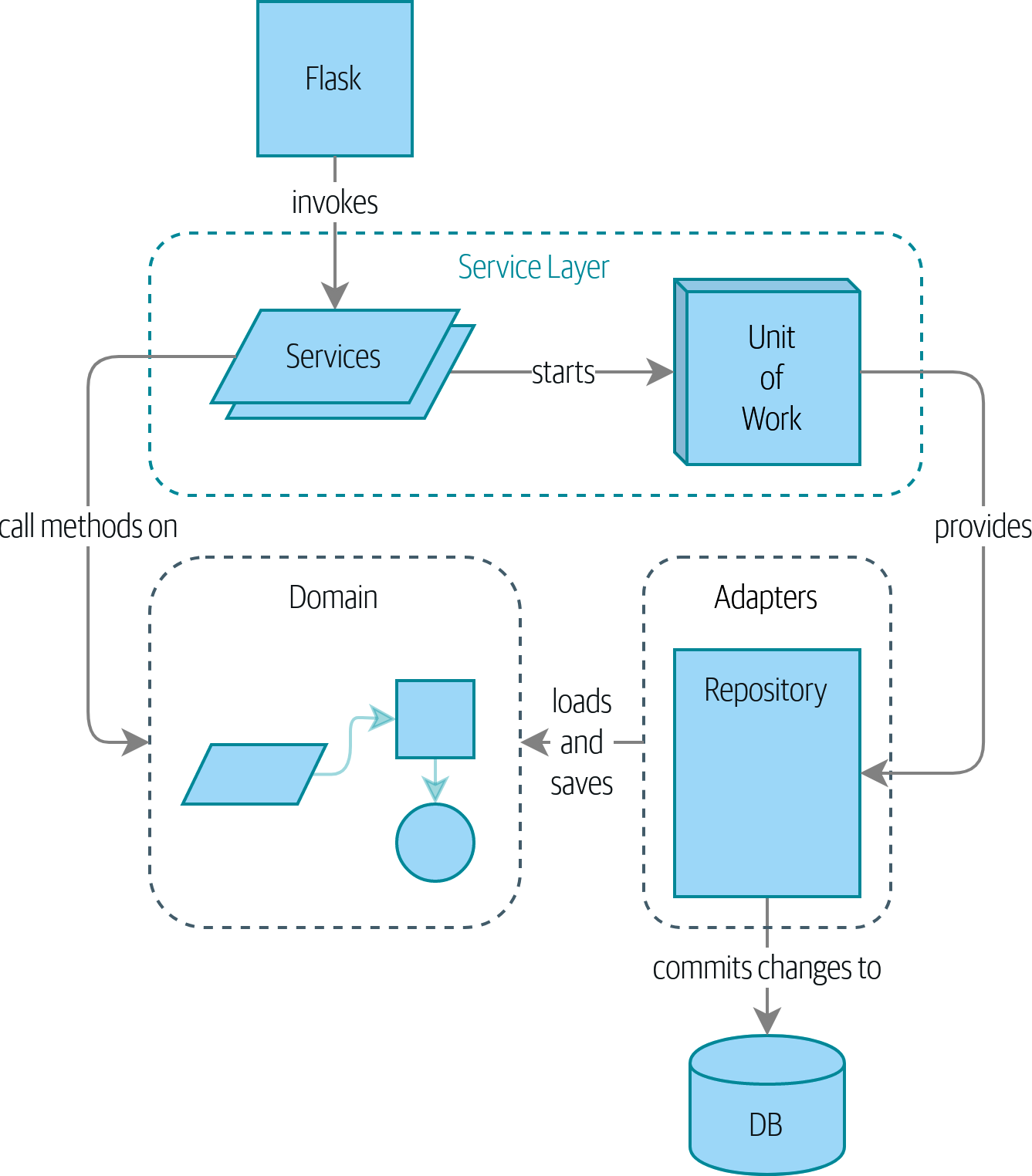
Nous prenons également un peu de temps pour parler du couplage et des abstractions, en l’illustrant avec un exemple simple qui montre comment et pourquoi nous choisissons nos abstractions.
Trois annexes sont des explorations supplémentaires du contenu de la Partie I :
-
Une Structure de Projet Modèle est une description de l’infrastructure pour notre code d’exemple : comment nous construisons et exécutons les images Docker, où nous gérons les informations de configuration, et comment nous exécutons différents types de tests.
-
Remplacer l’Infrastructure : Tout Faire avec des CSVs est un contenu du genre "la preuve est dans le pudding", montrant combien il est facile de remplacer toute notre infrastructure—l’API Flask, l' ORM, et Postgres—par un modèle d’E/S totalement différent impliquant un CLI et des CSVs.
-
Enfin, Motifs Dépôt (Repository) et Unité de Travail (Unit of Work) avec Django peut être intéressant si vous vous demandez à quoi ces patterns pourraient ressembler en utilisant Django au lieu de Flask et SQLAlchemy.
1. Modélisation du Domaine
Ce chapitre examine comment nous pouvons modéliser des processus métier avec du code, d’une manière hautement compatible avec le TDD. Nous discuterons pourquoi la modélisation du domaine est importante, et nous examinerons quelques patterns clés pour modéliser les domaines : Entité (Entity), Objet Valeur (Value Object), et Service de Domaine (Domain Service).
Une illustration temporaire de notre modèle de domaine est un simple support visuel pour notre pattern de Modèle de Domaine (Domain Model). Nous ajouterons quelques détails dans ce chapitre, et au fur et à mesure que nous avancerons vers d’autres chapitres, nous construirons des éléments autour du modèle de domaine, mais vous devriez toujours être capable de retrouver ces petites formes au cœur.
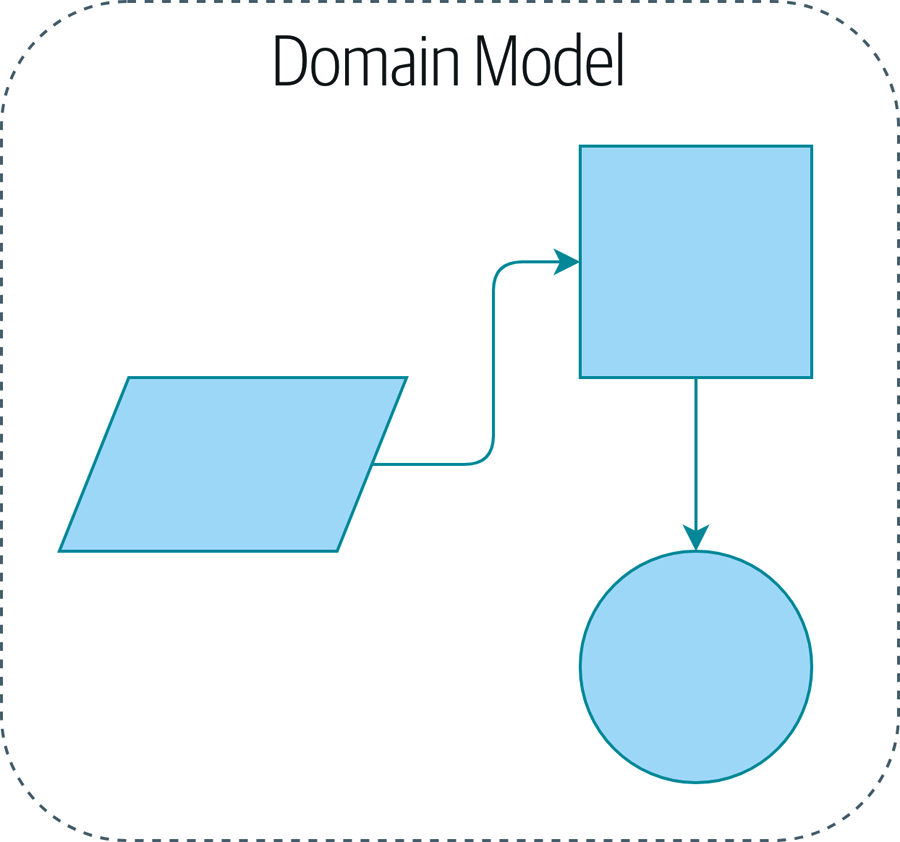
1.1. Qu’est-ce qu’un Modèle de Domaine ?
Dans l'introduction, nous avons utilisé le terme couche de logique métier pour décrire la couche centrale d’une architecture à trois couches. Pour le reste du livre, nous allons utiliser le terme modèle de domaine à la place. C’est un terme de la communauté DDD qui exprime mieux notre intention (voir l’encadré suivant pour plus d’informations sur le DDD).
Le domaine est une façon élégante de dire le problème que vous essayez de résoudre. Vos auteurs travaillent actuellement pour un détaillant en ligne de meubles. Selon le système dont vous parlez, le domaine peut être les achats et l’approvisionnement, ou la conception de produits, ou la logistique et la livraison. La plupart des programmeurs passent leurs journées à essayer d’améliorer ou d’automatiser des processus métier ; le domaine est l’ensemble des activités que ces processus supportent.
Un modèle est une carte d’un processus ou d’un phénomène qui capture une propriété utile. Les humains sont exceptionnellement doués pour produire des modèles de choses dans leur tête. Par exemple, quand quelqu’un vous lance une balle, vous êtes capable de prédire son mouvement presque inconsciemment, parce que vous avez un modèle de la façon dont les objets se déplacent dans l’espace. Votre modèle n’est en aucun cas parfait. Les humains ont de terribles intuitions sur la façon dont les objets se comportent à des vitesses proches de la lumière ou dans le vide parce que notre modèle n’a jamais été conçu pour couvrir ces cas. Cela ne signifie pas que le modèle est faux, mais cela signifie que certaines prédictions tombent en dehors de son domaine.
Le modèle de domaine est la carte mentale que les propriétaires d’entreprises ont de leurs entreprises. Tous les gens d’affaires ont ces cartes mentales—c’est ainsi que les humains pensent aux processus complexes.
Vous pouvez dire quand ils naviguent dans ces cartes parce qu’ils utilisent le jargon métier. Le jargon apparaît naturellement parmi les personnes qui collaborent sur des systèmes complexes.
Imaginez que vous, notre malheureux lecteur, soyez soudainement transporté à des années-lumière de la Terre à bord d’un vaisseau spatial alien avec vos amis et votre famille et deviez comprendre, à partir de premiers principes, comment naviguer pour rentrer chez vous.
Dans vos premiers jours, vous pourriez simplement appuyer sur des boutons au hasard, mais bientôt vous apprendriez quels boutons font quoi, afin que vous puissiez vous donner des instructions les uns aux autres. "Appuyez sur le bouton rouge près du machin clignotant et ensuite tirez ce gros levier là-bas près du truc radar," pourriez-vous dire.
En quelques semaines, vous deviendriez plus précis en adoptant des mots pour décrire les fonctions du vaisseau : "Augmentez les niveaux d’oxygène dans la soute trois" ou "allumez les petits propulseurs." Après quelques mois, vous auriez adopté un langage pour des processus complexes entiers : "Commencer la séquence d’atterrissage" ou "préparer pour la distorsion." Ce processus se produirait de manière tout à fait naturelle, sans aucun effort formel pour construire un glossaire partagé.
Il en va de même dans le monde banal des affaires. La terminologie utilisée par les parties prenantes métier représente une compréhension distillée du modèle de domaine, où des idées et des processus complexes sont réduits à un seul mot ou phrase.
Quand nous entendons nos parties prenantes métier utiliser des mots inconnus, ou utiliser des termes d’une manière spécifique, nous devrions écouter pour comprendre le sens plus profond et encoder leur expérience durement acquise dans notre logiciel.
Nous allons utiliser un modèle de domaine du monde réel tout au long de ce livre, spécifiquement un modèle de notre emploi actuel. MADE.com est un détaillant de meubles prospère. Nous nous approvisionnons en meubles auprès de fabricants du monde entier et les vendons à travers l’Europe.
Quand vous achetez un canapé ou une table basse, nous devons déterminer comment amener vos biens de Pologne ou de Chine ou du Vietnam dans votre salon.
À un haut niveau, nous avons des systèmes séparés qui sont responsables de l’achat de stock, de la vente de stock aux clients, et de l’expédition de biens aux clients. Un système au milieu doit coordonner le processus en allouant le stock aux commandes des clients ; voir Diagramme de contexte pour le service d’allocation.
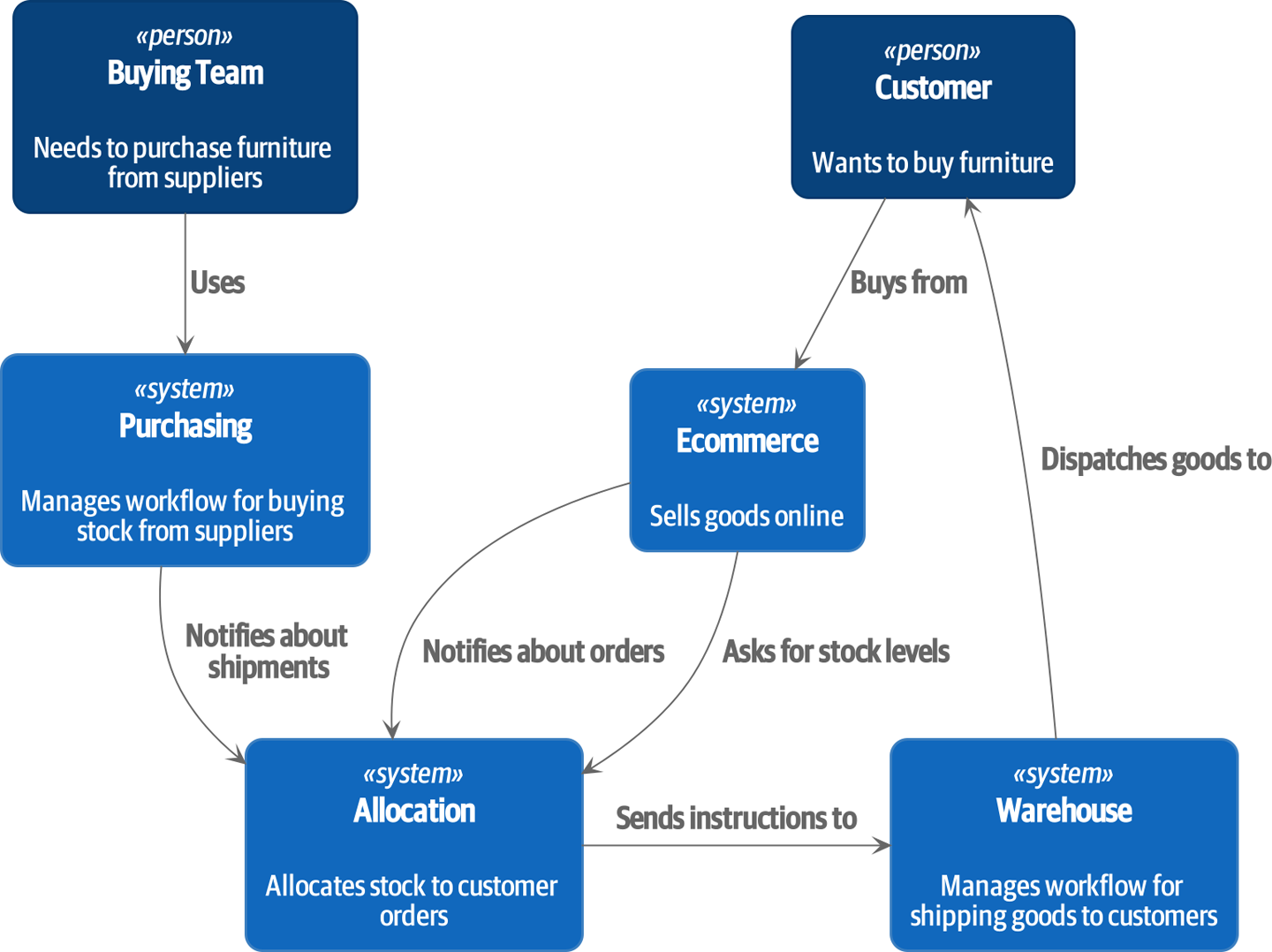
[plantuml, apwp_0102] @startuml Allocation Context Diagram !include images/C4_Context.puml scale 2 System(systema, "Allocation", "Allocates stock to customer orders") Person(customer, "Customer", "Wants to buy furniture") Person(buyer, "Buying Team", "Needs to purchase furniture from suppliers") System(procurement, "Purchasing", "Manages workflow for buying stock from suppliers") System(ecom, "Ecommerce", "Sells goods online") System(warehouse, "Warehouse", "Manages workflow for shipping goods to customers") Rel(buyer, procurement, "Uses") Rel(procurement, systema, "Notifies about shipments") Rel(customer, ecom, "Buys from") Rel(ecom, systema, "Asks for stock levels") Rel(ecom, systema, "Notifies about orders") Rel_R(systema, warehouse, "Sends instructions to") Rel_U(warehouse, customer, "Dispatches goods to") @enduml
Pour les besoins de ce livre, nous imaginons que l’entreprise décide de mettre en œuvre une nouvelle façon passionnante d’allouer le stock. Jusqu’à présent, l' entreprise a présenté le stock et les délais de livraison en fonction de ce qui est physiquement disponible dans l’entrepôt. Si et quand l’entrepôt est en rupture de stock, un produit est listé comme "en rupture de stock" jusqu’à la prochaine livraison du fabricant.
Voici l’innovation : si nous avons un système qui peut suivre toutes nos livraisons et quand elles sont censées arriver, nous pouvons traiter les biens sur ces navires comme du stock réel et une partie de notre inventaire, juste avec des délais de livraison légèrement plus longs. Moins de biens apparaîtront comme étant en rupture de stock, nous vendrons plus, et l’entreprise peut économiser de l’argent en gardant un inventaire plus faible dans l’entrepôt domestique.
Mais allouer des commandes n’est plus une question triviale de décrémenter une seule quantité dans le système de l’entrepôt. Nous avons besoin d’un mécanisme d’allocation plus complexe. Il est temps de faire de la modélisation du domaine.
1.2. Explorer le Langage du Domaine
Comprendre le modèle de domaine prend du temps, de la patience et des Post-it. Nous avons une conversation initiale avec nos experts métier et nous nous mettons d’accord sur un glossaire et quelques règles pour la première version minimale du modèle de domaine. Dans la mesure du possible, nous demandons des exemples concrets pour illustrer chaque règle.
Nous nous assurons d’exprimer ces règles dans le jargon métier (le langage omniprésent dans la terminologie DDD). Nous choisissons des identifiants mémorables pour nos objets afin que les exemples soient plus faciles à discuter.
L’encadré suivant montre quelques notes que nous aurions pu prendre en ayant une conversation avec nos experts du domaine sur l’allocation.
1.3. Tests Unitaires des Modèles de Domaine
Nous n’allons pas vous montrer comment fonctionne le TDD dans ce livre, mais nous voulons vous montrer comment nous construirions un modèle à partir de cette conversation métier.
Voici à quoi pourrait ressembler l’un de nos premiers tests :
def test_allocating_to_a_batch_reduces_the_available_quantity():
batch = Batch("batch-001", "SMALL-TABLE", qty=20, eta=date.today())
line = OrderLine("order-ref", "SMALL-TABLE", 2)
batch.allocate(line)
assert batch.available_quantity == 18Le nom de notre test unitaire décrit le comportement que nous voulons voir du système, et les noms des classes et variables que nous utilisons sont tirés du jargon métier. Nous pourrions montrer ce code à nos collègues non techniques, et ils seraient d’accord que cela décrit correctement le comportement du système.
Et voici un modèle de domaine qui répond à nos exigences :
@dataclass(frozen=True) (1) (2)
class OrderLine:
orderid: str
sku: str
qty: int
class Batch:
def __init__(self, ref: str, sku: str, qty: int, eta: Optional[date]): (2)
self.reference = ref
self.sku = sku
self.eta = eta
self.available_quantity = qty
def allocate(self, line: OrderLine): (3)
self.available_quantity -= line.qty| 1 | OrderLine est une dataclass immuable
sans comportement.[5] |
| 2 | Nous ne montrons pas les imports dans la plupart des listings de code, dans une tentative de les garder
propres. Nous espérons que vous pouvez deviner
que cela vient via from dataclasses import dataclass ; de même,
typing.Optional et datetime.date. Si vous voulez vérifier
quoi que ce soit, vous pouvez voir le code complet fonctionnel pour chaque chapitre dans
sa branche (par exemple,
chapter_01_domain_model). |
| 3 | Les annotations de type sont encore une question de controverse dans le monde Python. Pour les modèles de domaine, elles peuvent parfois aider à clarifier ou documenter quels sont les arguments attendus, et les personnes avec des IDE sont souvent reconnaissantes pour elles. Vous pouvez décider que le prix payé en termes de lisibilité est trop élevé. |
Notre implémentation ici est triviale :
un Batch enveloppe simplement un entier available_quantity,
et nous décrémentons cette valeur lors de l’allocation.
Nous avons écrit beaucoup de code juste pour soustraire un nombre d’un autre,
mais nous pensons que modéliser notre domaine avec précision sera payant.[6]
Écrivons quelques nouveaux tests qui échouent :
def make_batch_and_line(sku, batch_qty, line_qty):
return (
Batch("batch-001", sku, batch_qty, eta=date.today()),
OrderLine("order-123", sku, line_qty),
)
def test_can_allocate_if_available_greater_than_required():
large_batch, small_line = make_batch_and_line("ELEGANT-LAMP", 20, 2)
assert large_batch.can_allocate(small_line)
def test_cannot_allocate_if_available_smaller_than_required():
small_batch, large_line = make_batch_and_line("ELEGANT-LAMP", 2, 20)
assert small_batch.can_allocate(large_line) is False
def test_can_allocate_if_available_equal_to_required():
batch, line = make_batch_and_line("ELEGANT-LAMP", 2, 2)
assert batch.can_allocate(line)
def test_cannot_allocate_if_skus_do_not_match():
batch = Batch("batch-001", "UNCOMFORTABLE-CHAIR", 100, eta=None)
different_sku_line = OrderLine("order-123", "EXPENSIVE-TOASTER", 10)
assert batch.can_allocate(different_sku_line) is FalseIl n’y a rien de trop inattendu ici. Nous avons refactorisé notre suite de tests pour que nous
ne répétions pas les mêmes lignes de code pour créer un lot et une ligne pour
le même SKU ; et nous avons écrit quatre tests simples pour une nouvelle méthode
can_allocate. Encore une fois, remarquez que les noms que nous utilisons reflètent le langage de nos
experts du domaine, et les exemples sur lesquels nous nous sommes mis d’accord sont directement écrits dans le code.
Nous pouvons implémenter cela de manière simple, aussi, en écrivant la méthode can_allocate
de Batch :
def can_allocate(self, line: OrderLine) -> bool:
return self.sku == line.sku and self.available_quantity >= line.qtyJusqu’à présent, nous pouvons gérer l’implémentation en incrémentant et décrémentant simplement
Batch.available_quantity, mais au fur et à mesure que nous entrons dans les tests deallocate(), nous serons
forcés vers une solution plus intelligente :
def test_can_only_deallocate_allocated_lines():
batch, unallocated_line = make_batch_and_line("DECORATIVE-TRINKET", 20, 2)
batch.deallocate(unallocated_line)
assert batch.available_quantity == 20Dans ce test, nous affirmons que désallouer une ligne d’un lot n’a aucun effet
à moins que le lot n’ait précédemment alloué la ligne. Pour que cela fonctionne, notre Batch
doit comprendre quelles lignes ont été allouées. Regardons l'
implémentation :
class Batch:
def __init__(self, ref: str, sku: str, qty: int, eta: Optional[date]):
self.reference = ref
self.sku = sku
self.eta = eta
self._purchased_quantity = qty
self._allocations = set() # type: Set[OrderLine]
def allocate(self, line: OrderLine):
if self.can_allocate(line):
self._allocations.add(line)
def deallocate(self, line: OrderLine):
if line in self._allocations:
self._allocations.remove(line)
@property
def allocated_quantity(self) -> int:
return sum(line.qty for line in self._allocations)
@property
def available_quantity(self) -> int:
return self._purchased_quantity - self.allocated_quantity
def can_allocate(self, line: OrderLine) -> bool:
return self.sku == line.sku and self.available_quantity >= line.qtyNotre modèle en UML montre le modèle en UML.
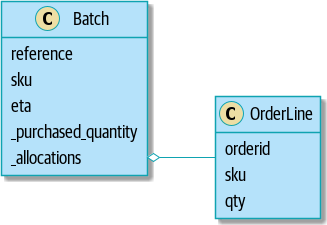
[plantuml, apwp_0103, config=plantuml.cfg]
@startuml
scale 4
left to right direction
hide empty members
class Batch {
reference
sku
eta
_purchased_quantity
_allocations
}
class OrderLine {
orderid
sku
qty
}
Batch::_allocations o-- OrderLine
Maintenant nous progressons ! Un lot garde maintenant la trace d’un ensemble d’objets
OrderLine alloués. Quand nous allouons, si nous avons assez de quantité disponible, nous
ajoutons simplement à l’ensemble. Notre available_quantity est maintenant une propriété calculée :
quantité achetée moins quantité allouée.
Oui, il y a beaucoup plus que nous pourrions faire. C’est un peu déconcertant que
allocate() et deallocate() puissent échouer silencieusement, mais nous avons les
bases.
Incidemment, utiliser un ensemble pour ._allocations nous facilite la tâche pour
gérer le dernier test, parce que les éléments dans un ensemble sont uniques :
def test_allocation_is_idempotent():
batch, line = make_batch_and_line("ANGULAR-DESK", 20, 2)
batch.allocate(line)
batch.allocate(line)
assert batch.available_quantity == 18Pour le moment, c’est probablement une critique valable de dire que le modèle de domaine est trop trivial pour s’embêter avec le DDD (ou même l’orientation objet !). Dans la vraie vie, un nombre quelconque de règles métier et de cas particuliers apparaissent : les clients peuvent demander une livraison à des dates futures spécifiques, ce qui signifie que nous ne voudrons peut-être pas les allouer au lot le plus tôt. Certains SKU ne sont pas dans des lots, mais commandés sur demande directement auprès des fournisseurs, donc ils ont une logique différente. Selon l’emplacement du client, nous ne pouvons allouer qu’à un sous-ensemble d’entrepôts et de livraisons qui sont dans leur région—sauf pour certains SKU que nous sommes heureux de livrer depuis un entrepôt dans une région différente si nous sommes en rupture de stock dans la région d’origine. Et ainsi de suite. Une vraie entreprise dans le monde réel sait comment empiler la complexité plus rapidement que nous ne pouvons le montrer sur la page !
Mais en prenant ce modèle de domaine simple comme un espace réservé pour quelque chose de plus complexe, nous allons étendre notre modèle de domaine simple dans le reste du livre et le connecter au monde réel des API, des bases de données et des feuilles de calcul. Nous verrons comment s’en tenir rigoureusement à nos principes d’encapsulation et de découpage soigneux nous aidera à éviter une boule de boue.
1.3.1. Les Dataclasses sont idéales pour les Objets Valeur
Nous avons utilisé line libéralement dans les listings de code précédents, mais qu’est-ce qu’une
ligne ? Dans notre langage métier, une commande a plusieurs lignes d’articles, où
chaque ligne a un SKU et une quantité. Nous pouvons imaginer qu’un simple fichier YAML
contenant des informations de commande pourrait ressembler à ceci :
Order_reference: 12345
Lines:
- sku: RED-CHAIR
qty: 25
- sku: BLU-CHAIR
qty: 25
- sku: GRN-CHAIR
qty: 25Remarquez que bien qu’une commande ait une référence qui l’identifie de manière unique, une
ligne n’en a pas. (Même si nous ajoutons la référence de commande à la classe OrderLine,
ce n’est pas quelque chose qui identifie de manière unique la ligne elle-même.)
Chaque fois que nous avons un concept métier qui a des données mais pas d’identité, nous choisissons souvent de le représenter en utilisant le pattern Objet Valeur (Value Object). Un objet valeur est tout objet du domaine qui est uniquement identifié par les données qu’il contient ; nous les rendons généralement immuables :
@dataclass(frozen=True)
class OrderLine:
orderid: OrderReference
sku: ProductReference
qty: Quantity
L’une des belles choses que les dataclasses (ou namedtuples) nous donnent est l'égalité
de valeur, qui est la façon élégante de dire : "Deux lignes avec le même orderid,
sku et qty sont égales."
from dataclasses import dataclass
from typing import NamedTuple
from collections import namedtuple
@dataclass(frozen=True)
class Name:
first_name: str
surname: str
class Money(NamedTuple):
currency: str
value: int
Line = namedtuple('Line', ['sku', 'qty'])
def test_equality():
assert Money('gbp', 10) == Money('gbp', 10)
assert Name('Harry', 'Percival') != Name('Bob', 'Gregory')
assert Line('RED-CHAIR', 5) == Line('RED-CHAIR', 5)Ces objets valeur correspondent à notre intuition du monde réel sur la façon dont leurs valeurs fonctionnent. Peu importe quel billet de 10 £ dont nous parlons, parce qu’ils ont tous la même valeur. De même, deux noms sont égaux si les prénoms et les noms de famille correspondent ; et deux lignes sont équivalentes si elles ont la même commande client, code produit et quantité. Nous pouvons toujours avoir un comportement complexe sur un objet valeur, cependant. En fait, il est courant de supporter des opérations sur les valeurs ; par exemple, les opérateurs mathématiques :
fiver = Money('gbp', 5)
tenner = Money('gbp', 10)
def can_add_money_values_for_the_same_currency():
assert fiver + fiver == tenner
def can_subtract_money_values():
assert tenner - fiver == fiver
def adding_different_currencies_fails():
with pytest.raises(ValueError):
Money('usd', 10) + Money('gbp', 10)
def can_multiply_money_by_a_number():
assert fiver * 5 == Money('gbp', 25)
def multiplying_two_money_values_is_an_error():
with pytest.raises(TypeError):
tenner * fiver
Pour que ces tests passent réellement, vous devrez commencer à implémenter quelques
méthodes magiques sur notre classe Money :
@dataclass(frozen=True)
class Money:
currency: str
value: int
def __add__(self, other) -> Money:
if other.currency != self.currency:
raise ValueError(f"Cannot add {self.currency} to {other.currency}")
return Money(self.currency, self.value + other.value)1.3.2. Objets Valeur et Entités
Une ligne de commande est uniquement identifiée par son ID de commande, son SKU et sa quantité ; si nous changeons l’une de ces valeurs, nous avons maintenant une nouvelle ligne. C’est la définition d’un objet valeur : tout objet qui n’est identifié que par ses données et n’a pas une identité de longue durée. Qu’en est-il d’un lot, cependant ? Il est identifié par une référence.
Nous utilisons le terme entité pour décrire un objet du domaine qui a une
identité de longue durée. Sur la page précédente, nous avons introduit une classe Name comme objet valeur.
Si nous prenons le nom Harry Percival et changeons une lettre, nous avons le nouvel
objet Name Barry Percival.
Il devrait être clair que Harry Percival n’est pas égal à Barry Percival :
def test_name_equality():
assert Name("Harry", "Percival") != Name("Barry", "Percival")Mais qu’en est-il de Harry en tant que personne ? Les gens changent effectivement leurs noms, et leur statut matrimonial, et même leur genre, mais nous continuons à les reconnaître comme le même individu. C’est parce que les humains, contrairement aux noms, ont une identité persistante :
class Person:
def __init__(self, name: Name):
self.name = name
def test_barry_is_harry():
harry = Person(Name("Harry", "Percival"))
barry = harry
barry.name = Name("Barry", "Percival")
assert harry is barry and barry is harryLes entités, contrairement aux valeurs, ont une égalité d’identité. Nous pouvons changer leurs valeurs, et elles sont toujours reconnaissables comme étant la même chose. Les lots, dans notre exemple, sont des entités. Nous pouvons allouer des lignes à un lot, ou changer la date à laquelle nous nous attendons à ce qu’il arrive, et ce sera toujours la même entité.
Nous rendons généralement cela explicite dans le code en implémentant des opérateurs d’égalité sur les entités :
class Batch:
...
def __eq__(self, other):
if not isinstance(other, Batch):
return False
return other.reference == self.reference
def __hash__(self):
return hash(self.reference)
La méthode magique __eq__ de Python
définit le comportement de la classe pour l’opérateur ==.[7]
Pour les objets entités et objets valeur, il vaut également la peine de réfléchir à comment
__hash__ fonctionnera. C’est la méthode magique que Python utilise pour contrôler le
comportement des objets quand vous les ajoutez à des ensembles ou les utilisez comme clés de dictionnaire ;
vous pouvez trouver plus d’informations dans la documentation Python.
Pour les objets valeur, le hash devrait être basé sur tous les attributs de valeur,
et nous devrions nous assurer que les objets sont immuables. Nous obtenons cela gratuitement
en spécifiant @frozen=True sur la dataclass.
Pour les entités, l’option la plus simple est de dire que le hash est None, ce qui signifie
que l’objet n’est pas hashable et ne peut pas, par exemple, être utilisé dans un ensemble.
Si pour une raison quelconque vous décidez que vous voulez vraiment utiliser des opérations d’ensemble ou de dictionnaire
avec des entités, le hash devrait être basé sur l’attribut (ou les attributs), tel que
.reference, qui définit l’identité unique de l’entité dans le temps. Vous devriez
également essayer de rendre cet attribut en lecture seule d’une manière ou d’une autre.
C’est un territoire délicat ; vous ne devriez pas modifier __hash__
sans également modifier __eq__. Si vous n’êtes pas sûr de ce
que vous faites, une lecture supplémentaire est suggérée.
"Python Hashes and Equality" par notre réviseur technique
Hynek Schlawack est un bon point de départ.
|
1.4. Tout ne doit pas être un objet : une fonction de Service de Domaine
Nous avons créé un modèle pour représenter les lots, mais ce que nous devons réellement faire est d’allouer des lignes de commande contre un ensemble spécifique de lots qui représentent tout notre stock.
Parfois, ce n’est tout simplement pas une chose.
Domain-Driven Design
Evans discute de l’idée d’opérations de Service de Domaine qui n’ont pas de place naturelle dans une entité ou un objet valeur.[8] Une chose qui alloue une ligne de commande, étant donné un ensemble de lots, ressemble beaucoup à une fonction, et nous pouvons profiter du fait que Python est un langage multiparadigme et simplement en faire une fonction.
Voyons comment nous pourrions tester une telle fonction :
def test_prefers_current_stock_batches_to_shipments():
in_stock_batch = Batch("in-stock-batch", "RETRO-CLOCK", 100, eta=None)
shipment_batch = Batch("shipment-batch", "RETRO-CLOCK", 100, eta=tomorrow)
line = OrderLine("oref", "RETRO-CLOCK", 10)
allocate(line, [in_stock_batch, shipment_batch])
assert in_stock_batch.available_quantity == 90
assert shipment_batch.available_quantity == 100
def test_prefers_earlier_batches():
earliest = Batch("speedy-batch", "MINIMALIST-SPOON", 100, eta=today)
medium = Batch("normal-batch", "MINIMALIST-SPOON", 100, eta=tomorrow)
latest = Batch("slow-batch", "MINIMALIST-SPOON", 100, eta=later)
line = OrderLine("order1", "MINIMALIST-SPOON", 10)
allocate(line, [medium, earliest, latest])
assert earliest.available_quantity == 90
assert medium.available_quantity == 100
assert latest.available_quantity == 100
def test_returns_allocated_batch_ref():
in_stock_batch = Batch("in-stock-batch-ref", "HIGHBROW-POSTER", 100, eta=None)
shipment_batch = Batch("shipment-batch-ref", "HIGHBROW-POSTER", 100, eta=tomorrow)
line = OrderLine("oref", "HIGHBROW-POSTER", 10)
allocation = allocate(line, [in_stock_batch, shipment_batch])
assert allocation == in_stock_batch.referenceEt notre service pourrait ressembler à ceci :
def allocate(line: OrderLine, batches: List[Batch]) -> str:
batch = next(b for b in sorted(batches) if b.can_allocate(line))
batch.allocate(line)
return batch.reference1.4.1. Les méthodes magiques de Python nous permettent d’utiliser nos modèles avec un Python idiomatique
Vous pouvez aimer ou non l’utilisation de next() dans le code précédent, mais nous sommes assez
sûrs que vous serez d’accord que pouvoir utiliser sorted() sur notre liste de
lots est agréable, un Python idiomatique.
Pour que cela fonctionne, nous implémentons __gt__ sur notre modèle de domaine :
class Batch:
...
def __gt__(self, other):
if self.eta is None:
return False
if other.eta is None:
return True
return self.eta > other.etaC’est charmant.
1.4.2. Les exceptions peuvent aussi exprimer des concepts du domaine
Nous avons un dernier concept à couvrir : les exceptions peuvent être utilisées pour exprimer des concepts du domaine aussi. Dans nos conversations avec les experts du domaine, nous avons appris la possibilité qu’une commande ne puisse pas être allouée parce que nous sommes en rupture de stock, et nous pouvons capturer cela en utilisant une exception de domaine :
def test_raises_out_of_stock_exception_if_cannot_allocate():
batch = Batch("batch1", "SMALL-FORK", 10, eta=today)
allocate(OrderLine("order1", "SMALL-FORK", 10), [batch])
with pytest.raises(OutOfStock, match="SMALL-FORK"):
allocate(OrderLine("order2", "SMALL-FORK", 1), [batch])Nous ne vous ennuierons pas trop avec l’implémentation, mais la principale chose à noter est que nous prenons soin de nommer nos exceptions dans le langage omniprésent, tout comme nous le faisons pour nos entités, objets valeur et services :
class OutOfStock(Exception):
pass
def allocate(line: OrderLine, batches: List[Batch]) -> str:
try:
batch = next(
...
except StopIteration:
raise OutOfStock(f"Out of stock for sku {line.sku}")Notre modèle de domaine à la fin du chapitre est une représentation visuelle de où nous en sommes arrivés.
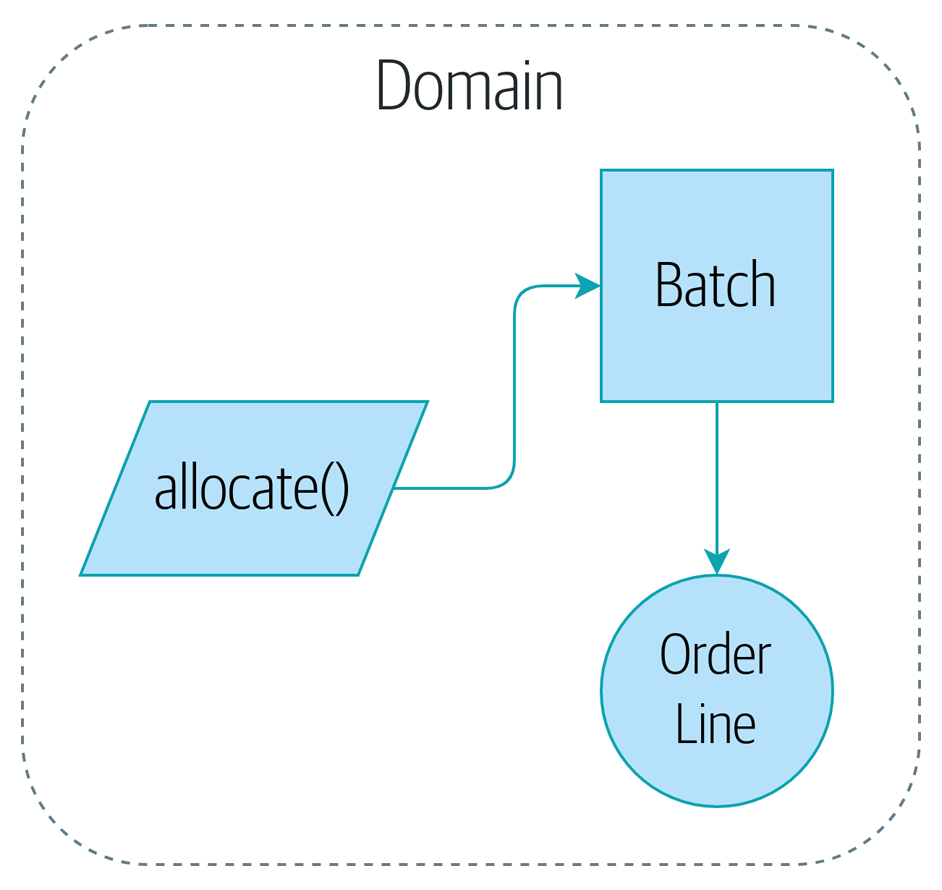
Cela suffira probablement pour l’instant ! Nous avons un service de domaine que nous pouvons utiliser pour notre premier cas d’utilisation. Mais d’abord nous aurons besoin d’une base de données…
2. Pattern Repository (Dépôt)
Il est temps de tenir notre promesse d’utiliser le principe d’inversion des dépendances comme moyen de découpler notre logique métier des préoccupations d’infrastructure.
Nous allons introduire le pattern Repository (Dépôt), une abstraction simplificatrice du stockage de données, nous permettant de découpler notre couche modèle de la couche de données. Nous présenterons un exemple concret de la façon dont cette abstraction simplificatrice rend notre système plus testable en cachant les complexités de la base de données.
Avant et après le pattern Repository montre un petit aperçu de ce que nous allons construire : un objet Repository qui se situe entre notre modèle de domaine et la base de données.
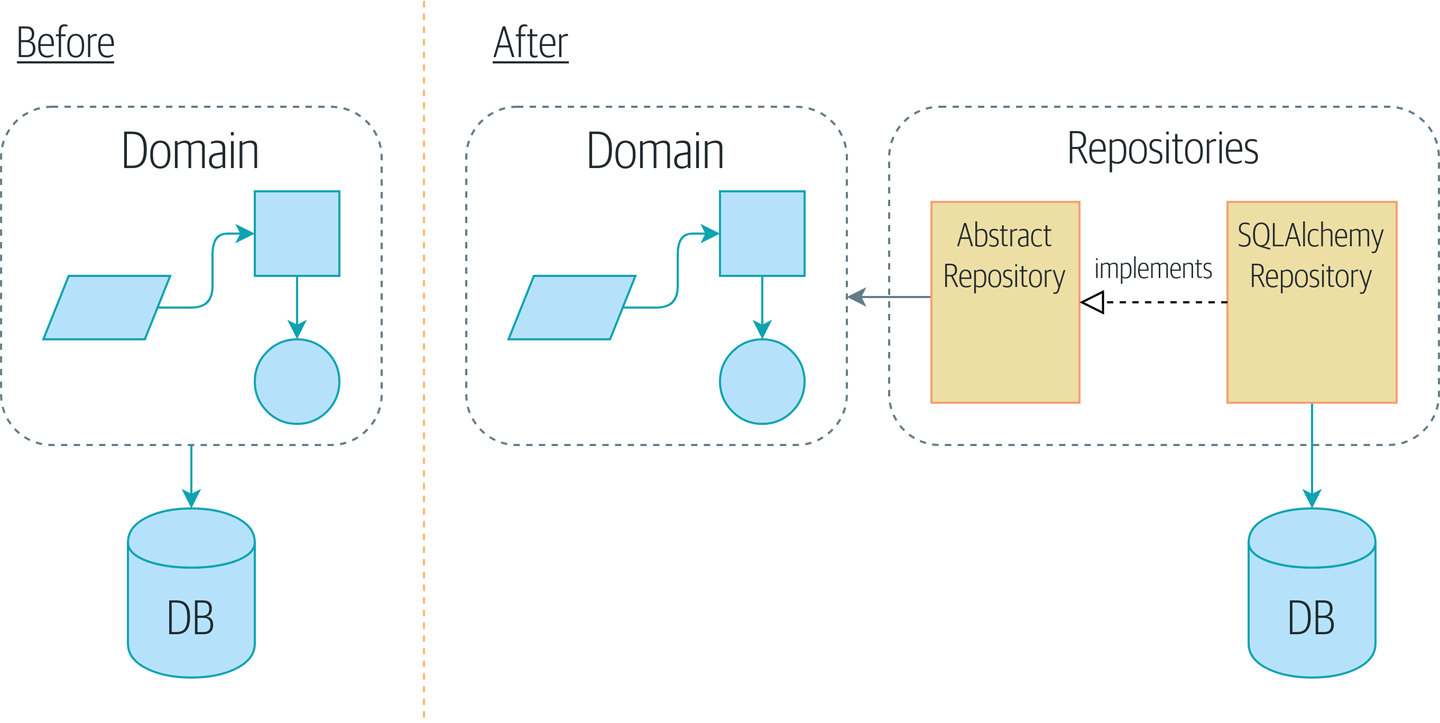
|
Le code de ce chapitre se trouve dans la branche chapter_02_repository sur GitHub. git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_02_repository # ou pour coder en suivant, récupérez le chapitre précédent : git checkout chapter_01_domain_model |
2.1. Rendre Persistant Notre Modèle de Domaine
Dans Modélisation du Domaine nous avons construit un simple modèle de domaine qui peut allouer des commandes à des lots de stock. Il est facile pour nous d’écrire des tests contre ce code car il n’y a aucune dépendance ou infrastructure à mettre en place. Si nous devions exécuter une base de données ou une API et créer des données de test, nos tests seraient plus difficiles à écrire et à maintenir.
Malheureusement, à un moment donné, nous devrons mettre notre petit modèle parfait entre les mains des utilisateurs et composer avec le monde réel des feuilles de calcul, des navigateurs web et des conditions de concurrence. Pour les prochains chapitres, nous allons examiner comment nous pouvons connecter notre modèle de domaine idéalisé à un état externe.
Nous nous attendons à travailler de manière agile, donc notre priorité est d’arriver à un produit minimum viable le plus rapidement possible. Dans notre cas, ce sera une API web. Dans un projet réel, vous pourriez vous lancer directement avec des tests de bout en bout et commencer à brancher un framework web, en développant de l’extérieur vers l’intérieur par les tests.
Mais nous savons que, quoi qu’il arrive, nous allons avoir besoin d’une forme de stockage persistant, et ceci est un manuel, donc nous pouvons nous permettre un peu plus de développement ascendant et commencer à réfléchir au stockage et aux bases de données.
2.2. Un Peu de Pseudo-Code : De Quoi Allons-Nous Avoir Besoin ?
Quand nous construirons notre premier point de terminaison API, nous savons que nous allons avoir du code qui ressemble plus ou moins à ceci.
@flask.route.gubbins
def allocate_endpoint():
# extraire la ligne de commande de la requête
line = OrderLine(request.params, ...)
# charger tous les lots depuis la BD
batches = ...
# appeler notre service de domaine
allocate(line, batches)
# puis sauvegarder l'allocation dans la base de données d'une manière ou d'une autre
return 201| Nous avons utilisé Flask car c’est léger, mais vous n’avez pas besoin d’être un utilisateur de Flask pour comprendre ce livre. En fait, nous vous montrerons comment faire de votre choix de framework un détail mineur. |
Nous aurons besoin d’un moyen de récupérer les informations sur les lots depuis la base de données et d’instancier nos objets du modèle de domaine à partir de celles-ci, et nous aurons également besoin d’un moyen de les sauvegarder dans la base de données.
Quoi ? Oh, "gubbins" est un mot britannique pour "trucs". Vous pouvez simplement l’ignorer. C’est du pseudo-code, OK ?
2.3. Appliquer le DIP à l’Accès aux Données
Comme mentionné dans l’introduction, une architecture en couches (layered architecture) est une approche courante pour structurer un système qui a une interface utilisateur, de la logique et une base de données (voir Architecture en couches).
La structure Modèle-Vue-Template de Django est étroitement liée, tout comme le Modèle-Vue-Contrôleur (MVC). Dans tous les cas, l’objectif est de garder les couches séparées (ce qui est une bonne chose), et de faire en sorte que chaque couche ne dépende que de celle en dessous.
Mais nous voulons que notre modèle de domaine n’ait aucune dépendance quelle qu’elle soit.[9] Nous ne voulons pas que les préoccupations d’infrastructure contaminent notre modèle de domaine et ralentissent nos tests unitaires ou notre capacité à apporter des modifications.
Au lieu de cela, comme discuté dans l’introduction, nous considérerons notre modèle comme étant à "l’intérieur", et les dépendances affluant vers lui ; c’est ce que les gens appellent parfois architecture en oignon (onion architecture) (voir Architecture en oignon).
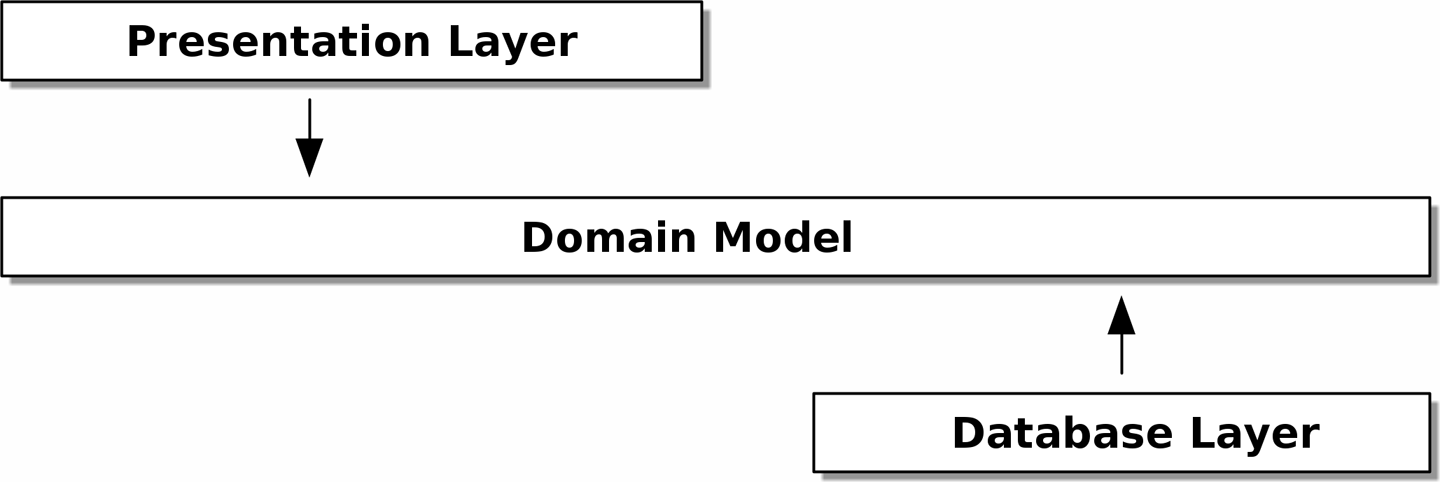
[ditaa, apwp_0203]
+------------------------+
| Presentation Layer |
+------------------------+
|
V
+--------------------------------------------------+
| Domain Model |
+--------------------------------------------------+
^
|
+---------------------+
| Database Layer |
+---------------------+
2.4. Rappel : Notre Modèle
Rappelons-nous notre modèle de domaine (voir Notre modèle) : une allocation est le concept de lier une OrderLine à un Batch. Nous stockons les allocations comme une collection sur notre objet Batch.
Voyons comment nous pourrions traduire cela en une base de données relationnelle.
2.4.1. La Méthode ORM "Normale" : Le Modèle Dépend de l’ORM
De nos jours, il est peu probable que les membres de votre équipe écrivent leurs propres requêtes SQL à la main. Au lieu de cela, vous utilisez presque certainement une sorte de framework pour générer du SQL pour vous en fonction de vos objets modèle.
Ces frameworks sont appelés mappeurs objet-relationnel (object-relational mappers - ORMs) parce qu’ils existent pour combler le fossé conceptuel entre le monde des objets et de la modélisation de domaine et le monde des bases de données et de l’algèbre relationnelle.
La chose la plus importante qu’un ORM nous apporte est l’ignorance de la persistance (persistence ignorance) : l’idée que notre modèle de domaine sophistiqué n’a pas besoin de savoir quoi que ce soit sur la façon dont les données sont chargées ou rendues persistantes. Cela aide à garder notre domaine exempt de dépendances directes sur des technologies de base de données particulières.[11]
Mais si vous suivez le tutoriel SQLAlchemy typique, vous vous retrouverez avec quelque chose comme ceci :
from sqlalchemy import Column, ForeignKey, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship
Base = declarative_base()
class Order(Base):
id = Column(Integer, primary_key=True)
class OrderLine(Base):
id = Column(Integer, primary_key=True)
sku = Column(String(250))
qty = Integer(String(250))
order_id = Column(Integer, ForeignKey('order.id'))
order = relationship(Order)
class Allocation(Base):
...Vous n’avez pas besoin de comprendre SQLAlchemy pour voir que notre modèle immaculé est maintenant plein de dépendances sur l’ORM et commence à avoir l’air sacrément laid en plus. Pouvons-nous vraiment dire que ce modèle est ignorant de la base de données ? Comment peut-il être séparé des préoccupations de stockage quand les propriétés de notre modèle sont directement couplées aux colonnes de la base de données ?
2.4.2. Inverser la Dépendance : L’ORM Dépend du Modèle
Eh bien, heureusement, ce n’est pas la seule façon d’utiliser SQLAlchemy. L’alternative est de définir votre schéma séparément, et de définir un mapper explicite pour comment convertir entre le schéma et notre modèle de domaine, ce que SQLAlchemy appelle un mappage classique (classical mapping) :
from sqlalchemy.orm import mapper, relationship
import model (1)
metadata = MetaData()
order_lines = Table( (2)
"order_lines",
metadata,
Column("id", Integer, primary_key=True, autoincrement=True),
Column("sku", String(255)),
Column("qty", Integer, nullable=False),
Column("orderid", String(255)),
)
...
def start_mappers():
lines_mapper = mapper(model.OrderLine, order_lines) (3)| 1 | L’ORM importe (ou "dépend de" ou "connaît") le modèle de domaine, et non l’inverse. |
| 2 | Nous définissons nos tables et colonnes de base de données en utilisant les abstractions de SQLAlchemy.[12] |
| 3 | Quand nous appelons la fonction mapper, SQLAlchemy fait sa magie pour lier nos classes du modèle de domaine aux différentes tables que nous avons définies. |
Le résultat final sera que, si nous appelons start_mappers, nous pourrons facilement charger et sauvegarder des instances du modèle de domaine depuis et vers la base de données. Mais si nous n’appelons jamais cette fonction, nos classes du modèle de domaine restent heureusement inconscientes de la base de données.
Cela nous donne tous les avantages de SQLAlchemy, y compris la capacité d’utiliser alembic pour les migrations, et la capacité d’interroger de manière transparente en utilisant nos classes de domaine, comme nous le verrons.
Quand vous essayez pour la première fois de construire votre configuration ORM, il peut être utile d’écrire des tests pour celle-ci, comme dans l’exemple suivant :
def test_orderline_mapper_can_load_lines(session): (1)
session.execute(
"INSERT INTO order_lines (orderid, sku, qty) VALUES "
'("order1", "RED-CHAIR", 12),'
'("order1", "RED-TABLE", 13),'
'("order2", "BLUE-LIPSTICK", 14)'
)
expected = [
model.OrderLine("order1", "RED-CHAIR", 12),
model.OrderLine("order1", "RED-TABLE", 13),
model.OrderLine("order2", "BLUE-LIPSTICK", 14),
]
assert session.query(model.OrderLine).all() == expected
def test_orderline_mapper_can_save_lines(session):
new_line = model.OrderLine("order1", "DECORATIVE-WIDGET", 12)
session.add(new_line)
session.commit()
rows = list(session.execute('SELECT orderid, sku, qty FROM "order_lines"'))
assert rows == [("order1", "DECORATIVE-WIDGET", 12)]| 1 | Si vous n’avez pas utilisé pytest, l’argument session de ce test nécessite une explication. Vous n’avez pas besoin de vous soucier des détails de pytest ou de ses fixtures pour les besoins de ce livre, mais l’explication courte est que vous pouvez définir des dépendances communes pour vos tests comme des "fixtures", et pytest les injectera aux tests qui en ont besoin en regardant leurs arguments de fonction. Dans ce cas, c’est une session de base de données SQLAlchemy.
|
Vous ne garderiez probablement pas ces tests à long terme — comme vous le verrez bientôt, une fois que vous aurez franchi l’étape d’inverser la dépendance de l’ORM et du modèle de domaine, ce n’est qu’une petite étape supplémentaire pour implémenter une autre abstraction appelée le pattern Repository, contre laquelle il sera plus facile d’écrire des tests et qui fournira une interface simple à simuler plus tard dans les tests.
Mais nous avons déjà atteint notre objectif d’inverser la dépendance traditionnelle : le modèle de domaine reste "pur" et libre de préoccupations d’infrastructure. Nous pourrions jeter SQLAlchemy et utiliser un ORM différent, ou un système de persistance totalement différent, et le modèle de domaine n’a pas besoin de changer du tout.
En fonction de ce que vous faites dans votre modèle de domaine, et surtout si vous vous éloignez du paradigme orienté objet, vous pourriez trouver de plus en plus difficile d’obtenir de l’ORM le comportement exact dont vous avez besoin, et vous pourriez avoir besoin de modifier votre modèle de domaine.[13] Comme cela arrive souvent avec les décisions architecturales, vous devrez considérer un compromis. Comme le dit le Zen de Python, "L’aspect pratique bat la pureté !"
À ce stade, cependant, notre point de terminaison API pourrait ressembler à ce qui suit, et nous pourrions le faire fonctionner très bien :
@flask.route.gubbins
def allocate_endpoint():
session = start_session()
# extraire la ligne de commande de la requête
line = OrderLine(
request.json['orderid'],
request.json['sku'],
request.json['qty'],
)
# charger tous les lots depuis la BD
batches = session.query(Batch).all()
# appeler notre service de domaine
allocate(line, batches)
# sauvegarder l'allocation dans la base de données
session.commit()
return 2012.5. Introduction du Pattern Repository
Le pattern Repository (Dépôt) est une abstraction sur le stockage persistant. Il cache les détails ennuyeux de l’accès aux données en faisant semblant que toutes nos données sont en mémoire.
Si nous avions une mémoire infinie dans nos ordinateurs portables, nous n’aurions pas besoin de bases de données maladroites. Au lieu de cela, nous pourrions simplement utiliser nos objets quand nous le voulons. À quoi cela ressemblerait-il ?
import all_my_data
def create_a_batch():
batch = Batch(...)
all_my_data.batches.add(batch)
def modify_a_batch(batch_id, new_quantity):
batch = all_my_data.batches.get(batch_id)
batch.change_initial_quantity(new_quantity)Même si nos objets sont en mémoire, nous devons les mettre quelque part pour pouvoir les retrouver. Nos données en mémoire nous permettraient d’ajouter de nouveaux objets, tout comme une liste ou un ensemble. Parce que les objets sont en mémoire, nous n’avons jamais besoin d’appeler une méthode .save() ; nous récupérons simplement l’objet qui nous intéresse et le modifions en mémoire.
2.5.1. Le Repository dans l’Abstrait
Le dépôt le plus simple n’a que deux méthodes : add() pour mettre un nouvel élément dans le dépôt, et get() pour retourner un élément précédemment ajouté.[14]
Nous nous en tenons rigoureusement à l’utilisation de ces méthodes pour l’accès aux données dans notre domaine et notre couche de service. Cette simplicité auto-imposée nous empêche de coupler notre modèle de domaine à la base de données.
Voici à quoi ressemblerait une classe de base abstraite (ABC) pour notre dépôt :
class AbstractRepository(abc.ABC):
@abc.abstractmethod (1)
def add(self, batch: model.Batch):
raise NotImplementedError (2)
@abc.abstractmethod
def get(self, reference) -> model.Batch:
raise NotImplementedError| 1 | Astuce Python : @abc.abstractmethod est l’une des seules choses qui fait que les ABCs "fonctionnent" réellement en Python. Python refusera de vous laisser instancier une classe qui n’implémente pas toutes les abstractmethods définies dans sa classe parente.[15]
|
| 2 | raise NotImplementedError est bien, mais ce n’est ni nécessaire ni suffisant. En fait, vos méthodes abstraites peuvent avoir un comportement réel que les sous-classes peuvent appeler, si vous le voulez vraiment. |
2.5.2. Quel Est le Compromis ?
Vous savez qu’on dit que les économistes connaissent le prix de tout et la valeur de rien ? Eh bien, les programmeurs connaissent les avantages de tout et les compromis de rien.
Chaque fois que nous introduisons un pattern architectural dans ce livre, nous demanderons toujours, "Qu’obtenons-nous pour cela ? Et qu’est-ce que cela nous coûte ?"
Habituellement, au minimum, nous introduirons une couche supplémentaire d’abstraction, et bien que nous puissions espérer qu’elle réduise la complexité globale, elle ajoute de la complexité localement, et elle a un coût en termes de nombre brut de pièces mobiles et de maintenance continue.
Le pattern Repository est probablement l’un des choix les plus faciles du livre, cependant, si vous vous dirigez déjà vers la route du DDD et de l’inversion de dépendance. En ce qui concerne notre code, nous échangeons vraiment simplement l’abstraction SQLAlchemy (session.query(Batch)) contre une différente (batches_repo.get) que nous avons conçue.
Nous devrons écrire quelques lignes de code dans notre classe de dépôt chaque fois que nous ajoutons un nouvel objet de domaine que nous voulons récupérer, mais en retour nous obtenons une abstraction simple sur notre couche de stockage, que nous contrôlons. Le pattern Repository rendrait facile d’apporter des changements fondamentaux à la façon dont nous stockons les choses (voir Remplacer l’Infrastructure : Tout Faire avec des CSVs), et comme nous le verrons, il est facile à simuler pour les tests unitaires.
De plus, le pattern Repository est si courant dans le monde du DDD que, si vous collaborez avec des programmeurs qui sont venus à Python depuis les mondes Java et C#, ils sont susceptibles de le reconnaître. Pattern Repository illustre le pattern.
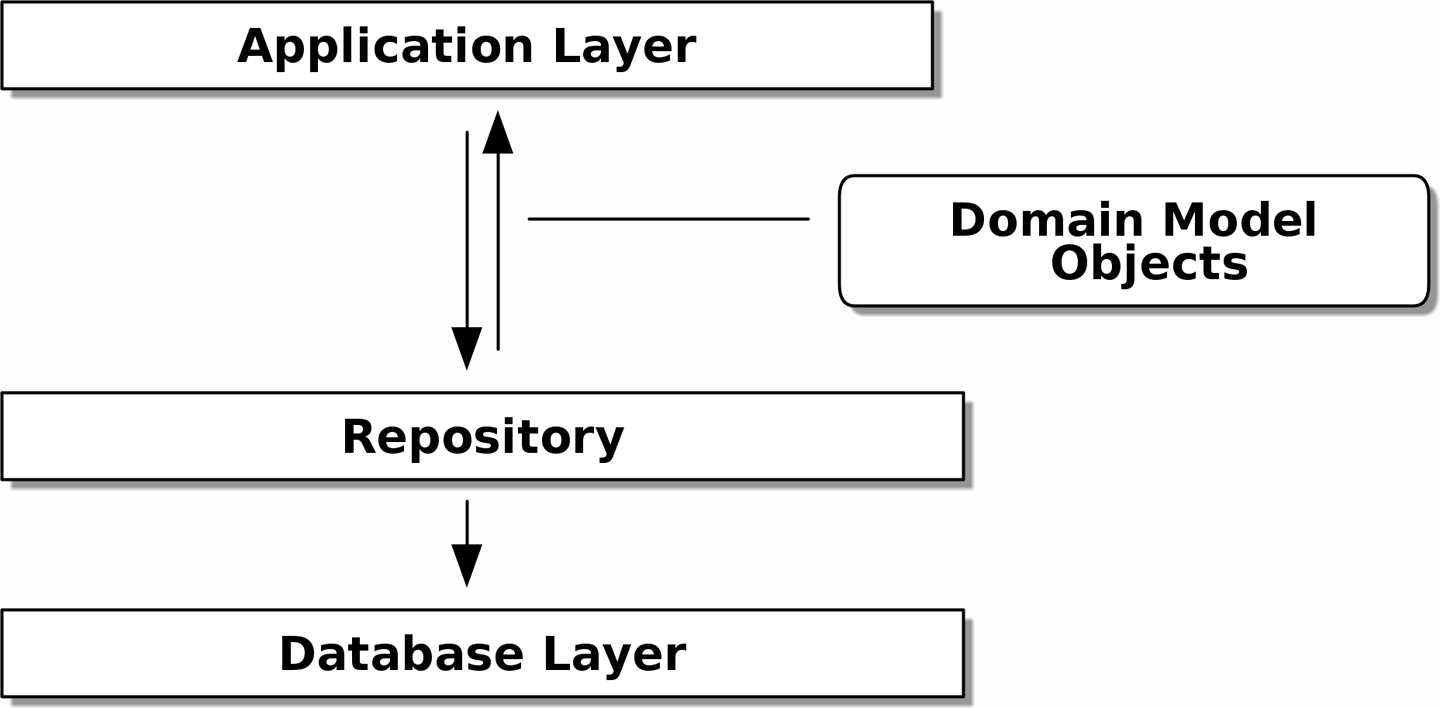
[ditaa, apwp_0205]
+-----------------------------+
| Application Layer |
+-----------------------------+
|^
|| /------------------\
||----------| Domain Model |
|| | Objects |
|| \------------------/
V|
+------------------------------+
| Repository |
+------------------------------+
|
V
+------------------------------+
| Database Layer |
+------------------------------+
Comme toujours, nous commençons par un test. Celui-ci serait probablement classé comme un test d’intégration, puisque nous vérifions que notre code (le dépôt) est correctement intégré à la base de données ; par conséquent, les tests ont tendance à mélanger du SQL brut avec des appels et des assertions sur notre propre code.
| Contrairement aux tests ORM d’avant, ces tests sont de bons candidats pour rester dans votre base de code à long terme, particulièrement si certaines parties de votre modèle de domaine signifient que la correspondance objet-relationnel n’est pas triviale. |
def test_repository_can_save_a_batch(session):
batch = model.Batch("batch1", "RUSTY-SOAPDISH", 100, eta=None)
repo = repository.SqlAlchemyRepository(session)
repo.add(batch) (1)
session.commit() (2)
rows = session.execute( (3)
'SELECT reference, sku, _purchased_quantity, eta FROM "batches"'
)
assert list(rows) == [("batch1", "RUSTY-SOAPDISH", 100, None)]| 1 | repo.add() est la méthode testée ici. |
| 2 | Nous gardons le .commit() en dehors du dépôt et en faisons la responsabilité de l’appelant. Il y a des avantages et des inconvénients à cela ; certaines de nos raisons deviendront plus claires quand nous arriverons à Motif Unité de Travail (Unit of Work Pattern). |
| 3 | Nous utilisons le SQL brut pour vérifier que les bonnes données ont été sauvegardées. |
Le test suivant implique de récupérer des lots et des allocations, il est donc plus complexe :
def insert_order_line(session):
session.execute( (1)
"INSERT INTO order_lines (orderid, sku, qty)"
' VALUES ("order1", "GENERIC-SOFA", 12)'
)
[[orderline_id]] = session.execute(
"SELECT id FROM order_lines WHERE orderid=:orderid AND sku=:sku",
dict(orderid="order1", sku="GENERIC-SOFA"),
)
return orderline_id
def insert_batch(session, batch_id): (2)
...
def test_repository_can_retrieve_a_batch_with_allocations(session):
orderline_id = insert_order_line(session)
batch1_id = insert_batch(session, "batch1")
insert_batch(session, "batch2")
insert_allocation(session, orderline_id, batch1_id) (2)
repo = repository.SqlAlchemyRepository(session)
retrieved = repo.get("batch1")
expected = model.Batch("batch1", "GENERIC-SOFA", 100, eta=None)
assert retrieved == expected # Batch.__eq__ compare seulement la référence (3)
assert retrieved.sku == expected.sku (4)
assert retrieved._purchased_quantity == expected._purchased_quantity
assert retrieved._allocations == { (4)
model.OrderLine("order1", "GENERIC-SOFA", 12),
}| 1 | Ce test concerne le côté lecture, donc le SQL brut prépare les données à lire par repo.get(). |
| 2 | Nous vous épargnerons les détails de insert_batch et insert_allocation ; le point est de créer quelques lots, et, pour le lot qui nous intéresse, d’avoir une ligne de commande existante qui lui est allouée. |
| 3 | Et c’est ce que nous vérifions ici. Le premier assert == vérifie que les types correspondent, et que la référence est la même (parce que, comme vous vous en souvenez, Batch est une entité, et nous avons un __eq__ personnalisé pour elle). |
| 4 | Donc nous vérifions également explicitement ses attributs majeurs, y compris ._allocations, qui est un ensemble Python d’objets valeur OrderLine. |
Que vous écriviez minutieusement des tests pour chaque modèle ou non est une question de jugement. Une fois que vous avez une classe testée pour créer/modifier/sauvegarder, vous pourriez être heureux de continuer et de faire les autres avec un test aller-retour minimal, ou même rien du tout, s’ils suivent tous un pattern similaire. Dans notre cas, la configuration ORM qui configure l’ensemble ._allocations est un peu complexe, donc elle méritait un test spécifique.
Vous vous retrouvez avec quelque chose comme ceci :
class SqlAlchemyRepository(AbstractRepository):
def __init__(self, session):
self.session = session
def add(self, batch):
self.session.add(batch)
def get(self, reference):
return self.session.query(model.Batch).filter_by(reference=reference).one()
def list(self):
return self.session.query(model.Batch).all()Et maintenant notre point de terminaison Flask pourrait ressembler à quelque chose comme ceci :
@flask.route.gubbins
def allocate_endpoint():
batches = SqlAlchemyRepository.list()
lines = [
OrderLine(l['orderid'], l['sku'], l['qty'])
for l in request.params...
]
allocate(lines, batches)
session.commit()
return 2012.6. Construire un Faux Dépôt pour les Tests Est Maintenant Trivial !
Voici l’un des plus grands avantages du pattern Repository :
class FakeRepository(AbstractRepository):
def __init__(self, batches):
self._batches = set(batches)
def add(self, batch):
self._batches.add(batch)
def get(self, reference):
return next(b for b in self._batches if b.reference == reference)
def list(self):
return list(self._batches)Parce que c’est un simple enrobage autour d’un set, toutes les méthodes tiennent en une ligne.
Utiliser un faux dépôt dans les tests est vraiment facile, et nous avons une abstraction simple qui est facile à utiliser et à raisonner :
fake_repo = FakeRepository([batch1, batch2, batch3])Vous verrez ce faux en action dans le prochain chapitre.
| Construire des faux pour vos abstractions est un excellent moyen d’obtenir des retours de conception : si c’est difficile à simuler, l’abstraction est probablement trop compliquée. |
2.7. Qu’est-ce qu’un Port et Qu’est-ce qu’un Adaptateur, en Python ?
Nous ne voulons pas nous attarder trop sur la terminologie ici parce que la chose principale sur laquelle nous voulons nous concentrer est l’inversion de dépendance, et les spécificités de la technique que vous utilisez n’ont pas trop d’importance. De plus, nous sommes conscients que différentes personnes utilisent des définitions légèrement différentes.
Les ports et adaptateurs sont sortis du monde orienté objet, et la définition à laquelle nous nous accrochons est que le port est l'interface entre notre application et tout ce que nous souhaitons abstraire, et l'adaptateur est l'implémentation derrière cette interface ou abstraction.
Maintenant, Python n’a pas d’interfaces en soi, donc bien qu’il soit généralement facile d’identifier un adaptateur, définir le port peut être plus difficile. Si vous utilisez une classe de base abstraite, c’est le port. Sinon, le port est juste le duck type auquel vos adaptateurs se conforment et que votre application principale attend — les noms de fonction et de méthode utilisés, et leurs noms et types d’arguments.
Concrètement, dans ce chapitre, AbstractRepository est le port, et SqlAlchemyRepository et FakeRepository sont les adaptateurs.
2.8. Récapitulatif
En gardant à l’esprit la citation de Rich Hickey, dans chaque chapitre nous résumons les coûts et les bénéfices de chaque pattern architectural que nous introduisons. Nous voulons être clairs que nous ne disons pas que chaque application doit être construite de cette façon ; seulement parfois la complexité de l’application et du domaine vaut-elle la peine d’investir le temps et l’effort pour ajouter ces couches supplémentaires d’indirection.
Avec cela à l’esprit, Pattern Repository et ignorance de la persistance : les compromis montre certains des avantages et inconvénients du pattern Repository et de notre modèle ignorant de la persistance.
| Avantages | Inconvénients |
|---|---|
|
|
Compromis du modèle de domaine sous forme de diagramme montre la thèse de base : oui, pour les cas simples, un modèle de domaine découplé est plus de travail qu’un simple pattern ORM/ActiveRecord.[16]
| Si votre application n’est qu’un simple wrapper CRUD (create-read-update-delete) autour d’une base de données, alors vous n’avez pas besoin d’un modèle de domaine ou d’un dépôt. |
Mais plus le domaine est complexe, plus un investissement pour vous libérer des préoccupations d’infrastructure sera payant en termes de facilité à apporter des changements.
Notre exemple de code n’est pas assez complexe pour donner plus qu’un indice de ce à quoi ressemble le côté droit du graphique, mais les indices sont là. Imaginez, par exemple, si nous décidons un jour que nous voulons changer les allocations pour qu’elles vivent sur l'`OrderLine` au lieu de sur l’objet Batch : si nous utilisions Django, par exemple, nous devrions définir et réfléchir à la migration de base de données avant de pouvoir exécuter des tests. Tel quel, parce que notre modèle est juste des objets Python ordinaires, nous pouvons changer un set() en un nouvel attribut, sans avoir besoin de penser à la base de données jusqu’à plus tard.
Vous vous demanderez comment nous instancions ces dépôts, faux ou réels ? À quoi ressemblera réellement notre application Flask ? Vous le découvrirez dans le prochain épisode passionnant, le pattern Couche de Service (Service Layer).
Mais d’abord, une brève digression.
3. Une Brève Digression : Sur le Couplage et les Abstractions
Permettez-nous une brève digression sur le sujet des abstractions, cher lecteur. Nous avons beaucoup parlé d'abstractions. Le pattern Dépôt (Repository) est une abstraction sur le stockage permanent, par exemple. Mais qu’est-ce qui fait une bonne abstraction ? Que voulons-nous des abstractions ? Et comment sont-elles liées aux tests ?
|
Le code de ce chapitre se trouve dans la branche chapter_03_abstractions sur GitHub : git clone https://github.com/cosmicpython/code.git git checkout chapter_03_abstractions |
Un thème clé de ce livre, caché parmi les patterns élégants, est que nous pouvons utiliser des abstractions simples pour masquer des détails désordonnés. Lorsque nous écrivons du code pour le plaisir, ou dans un kata,[17] nous pouvons jouer librement avec les idées, en martelant les choses et en refactorisant agressivement. Dans un système à grande échelle, cependant, nous devenons contraints par les décisions prises ailleurs dans le système.
Lorsque nous sommes incapables de changer le composant A par peur de casser le composant B, nous disons que les composants sont devenus couplés. Localement, le couplage (Coupling) est une bonne chose : c’est un signe que notre code fonctionne ensemble, chaque composant soutenant les autres, tous s’ajustant en place comme les engrenages d’une montre. Dans le jargon, nous disons que cela fonctionne lorsqu’il y a une haute cohésion entre les éléments couplés.
Globalement, le couplage est une nuisance : il augmente le risque et le coût de modification de notre code, parfois au point où nous nous sentons incapables de faire des changements du tout. C’est le problème avec le pattern Ball of Mud : à mesure que l’application grandit, si nous sommes incapables d’empêcher le couplage entre des éléments qui n’ont pas de cohésion, ce couplage augmente de manière superlinéaire jusqu’à ce que nous ne soyons plus capables de changer efficacement nos systèmes.
Nous pouvons réduire le degré de couplage au sein d’un système (Beaucoup de couplage) en abstrayant les détails (Moins de couplage).
[ditaa, apwp_0301] +--------+ +--------+ | System | ---> | System | | A | ---> | B | | | ---> | | | | ---> | | | | ---> | | +--------+ +--------+

[ditaa, apwp_0302] +--------+ +--------+ | System | /-------------\ | System | | A | ---> | | ---> | B | | | ---> | Abstraction | ---> | | | | | | ---> | | | | \-------------/ | | +--------+ +--------+
Dans les deux diagrammes, nous avons une paire de sous-systèmes, l’un dépendant de l’autre. Dans Beaucoup de couplage, il y a un haut degré de couplage entre les deux ; le nombre de flèches indique de nombreux types de dépendances entre les deux. Si nous devons changer le système B, il y a de bonnes chances que le changement se propage au système A.
Dans Moins de couplage, cependant, nous avons réduit le degré de couplage en insérant une nouvelle abstraction plus simple. Parce qu’elle est plus simple, le système A a moins de types de dépendances sur l’abstraction. L’abstraction sert à nous protéger du changement en cachant les détails complexes de ce que fait le système B —nous pouvons changer les flèches à droite sans changer celles à gauche.
3.1. Abstraire l’État Aide à la Testabilité
Voyons un exemple. Imaginons que nous voulons écrire du code pour synchroniser deux répertoires de fichiers, que nous appellerons la source et la destination :
-
Si un fichier existe dans la source mais pas dans la destination, copier le fichier.
-
Si un fichier existe dans la source, mais qu’il a un nom différent de celui dans la destination, renommer le fichier de destination pour qu’il corresponde.
-
Si un fichier existe dans la destination mais pas dans la source, le supprimer.
Nos première et troisième exigences sont assez simples : nous pouvons simplement comparer deux listes de chemins. Notre deuxième est plus délicate, cependant. Pour détecter les renommages, nous devrons inspecter le contenu des fichiers. Pour cela, nous pouvons utiliser une fonction de hachage comme MD5 ou SHA-1. Le code pour générer un hachage SHA-1 à partir d’un fichier est assez simple :
BLOCKSIZE = 65536
def hash_file(path):
hasher = hashlib.sha1()
with path.open("rb") as file:
buf = file.read(BLOCKSIZE)
while buf:
hasher.update(buf)
buf = file.read(BLOCKSIZE)
return hasher.hexdigest()Maintenant nous devons écrire la partie qui prend des décisions sur quoi faire—la logique métier, si vous voulez.
Lorsque nous devons aborder un problème à partir des premiers principes, nous essayons généralement d’écrire une implémentation simple puis de refactoriser vers une meilleure conception. Nous utiliserons cette approche tout au long du livre, parce que c’est comme ça que nous écrivons du code dans le monde réel : commencer par une solution à la plus petite partie du problème, puis itérativement rendre la solution plus riche et mieux conçue.
Notre première approche bricolée ressemble à quelque chose comme ceci :
import hashlib
import os
import shutil
from pathlib import Path
def sync(source, dest):
# Parcourir le dossier source et construire un dict de noms de fichiers et de leurs hachages
source_hashes = {}
for folder, _, files in os.walk(source):
for fn in files:
source_hashes[hash_file(Path(folder) / fn)] = fn
seen = set() # Garder une trace des fichiers que nous avons trouvés dans la cible
# Parcourir le dossier cible et obtenir les noms de fichiers et les hachages
for folder, _, files in os.walk(dest):
for fn in files:
dest_path = Path(folder) / fn
dest_hash = hash_file(dest_path)
seen.add(dest_hash)
# s'il y a un fichier dans la cible qui n'est pas dans la source, le supprimer
if dest_hash not in source_hashes:
dest_path.remove()
# s'il y a un fichier dans la cible qui a un chemin différent dans la source,
# le déplacer vers le bon chemin
elif dest_hash in source_hashes and fn != source_hashes[dest_hash]:
shutil.move(dest_path, Path(folder) / source_hashes[dest_hash])
# pour chaque fichier qui apparaît dans la source mais pas dans la cible, copier le fichier vers
# la cible
for source_hash, fn in source_hashes.items():
if source_hash not in seen:
shutil.copy(Path(source) / fn, Path(dest) / fn)Fantastique ! Nous avons du code et il semble OK, mais avant de l’exécuter sur notre disque dur, peut-être devrions-nous le tester. Comment peut-on tester ce genre de chose ?
def test_when_a_file_exists_in_the_source_but_not_the_destination():
try:
source = tempfile.mkdtemp()
dest = tempfile.mkdtemp()
content = "I am a very useful file"
(Path(source) / "my-file").write_text(content)
sync(source, dest)
expected_path = Path(dest) / "my-file"
assert expected_path.exists()
assert expected_path.read_text() == content
finally:
shutil.rmtree(source)
shutil.rmtree(dest)
def test_when_a_file_has_been_renamed_in_the_source():
try:
source = tempfile.mkdtemp()
dest = tempfile.mkdtemp()
content = "I am a file that was renamed"
source_path = Path(source) / "source-filename"
old_dest_path = Path(dest) / "dest-filename"
expected_dest_path = Path(dest) / "source-filename"
source_path.write_text(content)
old_dest_path.write_text(content)
sync(source, dest)
assert old_dest_path.exists() is False
assert expected_dest_path.read_text() == content
finally:
shutil.rmtree(source)
shutil.rmtree(dest)
Wow, c’est beaucoup de configuration pour deux cas simples ! Le problème est que
notre logique de domaine, "déterminer la différence entre deux répertoires", est étroitement
couplée au code d’I/O. Nous ne pouvons pas exécuter notre algorithme de différence sans appeler
les modules pathlib, shutil et hashlib.
Et le problème est que, même avec nos exigences actuelles, nous n’avons pas écrit
assez de tests : l’implémentation actuelle a plusieurs bugs (le
shutil.move() est incorrect, par exemple). Obtenir une couverture décente et révéler
ces bugs signifie écrire plus de tests, mais s’ils sont tous aussi lourds que les précédents,
cela va devenir vraiment pénible très rapidement.
En plus de cela, notre code n’est pas très extensible. Imaginez essayer d’implémenter
un flag --dry-run qui ferait que notre code imprime juste ce qu’il va
faire, plutôt que de le faire réellement. Ou que se passerait-il si nous voulions synchroniser vers un serveur distant,
ou vers le stockage cloud ?
Notre code de haut niveau est couplé aux détails de bas niveau, et cela rend la vie difficile. À mesure que les scénarios que nous considérons deviennent plus complexes, nos tests deviendront plus lourds. Nous pourrions certainement refactoriser ces tests (une partie du nettoyage pourrait aller dans des fixtures pytest, par exemple) mais tant que nous faisons des opérations sur le système de fichiers, ils vont rester lents et difficiles à lire et à écrire.
3.2. Choisir la ou les Bonnes Abstractions
Que pourrions-nous faire pour réécrire notre code afin de le rendre plus testable ?
D’abord, nous devons réfléchir à ce dont notre code a besoin du système de fichiers. En lisant le code, nous pouvons voir que trois choses distinctes se produisent. Nous pouvons les considérer comme trois responsabilités distinctes que le code a :
-
Nous interrogeons le système de fichiers en utilisant
os.walket déterminons les hachages pour une série de chemins. C’est similaire dans les cas source et destination. -
Nous décidons si un fichier est nouveau, renommé ou redondant.
-
Nous copions, déplaçons ou supprimons des fichiers pour correspondre à la source.
Rappelez-vous que nous voulons trouver des abstractions simplificatrices pour chacune de ces responsabilités. Cela nous permettra de cacher les détails désordonnés afin que nous puissions nous concentrer sur la logique intéressante.[18]
Dans ce chapitre, nous refactorisons du code compliqué en une structure plus testable
en identifiant les tâches séparées qui doivent être effectuées et en donnant
chaque tâche à un acteur clairement défini, dans des lignes similaires à l’exemple duckduckgo.
|
Pour les étapes 1 et 2, nous avons déjà intuitivement commencé à utiliser une abstraction, un dictionnaire de hachages vers des chemins. Vous pourriez déjà penser : "Pourquoi ne pas construire un dictionnaire pour le dossier de destination ainsi que pour la source, et ensuite nous comparons simplement deux dicts ?" Cela semble être une belle façon d’abstraire l' état actuel du système de fichiers :
source_files = {'hash1': 'path1', 'hash2': 'path2'}
dest_files = {'hash1': 'path1', 'hash2': 'pathX'}
Qu’en est-il du passage de l’étape 2 à l’étape 3 ? Comment pouvons-nous abstraire l' interaction réelle de déplacement/copie/suppression du système de fichiers ?
Nous allons appliquer une astuce ici que nous utiliserons à grande échelle plus tard dans le livre. Nous allons séparer ce que nous voulons faire de comment le faire. Nous allons faire en sorte que notre programme génère une liste de commandes qui ressemblent à ceci :
("COPY", "sourcepath", "destpath"),
("MOVE", "old", "new"),
Maintenant nous pourrions écrire des tests qui utilisent simplement deux dicts de système de fichiers comme entrées, et nous attendrions des listes de tuples de chaînes représentant des actions comme sorties.
Au lieu de dire : "Étant donné ce système de fichiers réel, quand j’exécute ma fonction, vérifier quelles actions se sont produites", nous disons : "Étant donné cette abstraction d’un système de fichiers, quelle abstraction d’actions du système de fichiers va se produire ?"
def test_when_a_file_exists_in_the_source_but_not_the_destination():
source_hashes = {'hash1': 'fn1'}
dest_hashes = {}
expected_actions = [('COPY', '/src/fn1', '/dst/fn1')]
...
def test_when_a_file_has_been_renamed_in_the_source():
source_hashes = {'hash1': 'fn1'}
dest_hashes = {'hash1': 'fn2'}
expected_actions == [('MOVE', '/dst/fn2', '/dst/fn1')]
...3.3. Implémenter Nos Abstractions Choisies
C’est bien beau tout ça, mais comment réellement écrire ces nouveaux tests, et comment changer notre implémentation pour que tout fonctionne ?
Notre objectif est d’isoler la partie intelligente de notre système, et de pouvoir la tester minutieusement sans avoir besoin de configurer un vrai système de fichiers. Nous créerons un "noyau" de code qui n’a pas de dépendances sur l’état externe et verrons ensuite comment il répond lorsque nous lui donnons des entrées du monde extérieur (ce type d’approche a été caractérisé par Gary Bernhardt comme Functional Core, Imperative Shell, ou FCIS).
Commençons par diviser le code pour séparer les parties avec état de la logique.
Et notre fonction de niveau supérieur ne contiendra presque aucune logique du tout ; c’est juste une série impérative d’étapes : rassembler les entrées, appeler notre logique, appliquer les sorties :
def sync(source, dest):
# étape 1 de la coquille impérative, rassembler les entrées
source_hashes = read_paths_and_hashes(source) (1)
dest_hashes = read_paths_and_hashes(dest) (1)
# étape 2 : appeler le noyau fonctionnel
actions = determine_actions(source_hashes, dest_hashes, source, dest) (2)
# étape 3 de la coquille impérative, appliquer les sorties
for action, *paths in actions:
if action == "COPY":
shutil.copyfile(*paths)
if action == "MOVE":
shutil.move(*paths)
if action == "DELETE":
os.remove(paths[0])| 1 | Voici la première fonction que nous extrayons, read_paths_and_hashes(), qui
isole la partie I/O de notre application. |
| 2 | Voici où nous découpons le noyau fonctionnel, la logique métier. |
Le code pour construire le dictionnaire de chemins et de hachages est maintenant trivialement facile à écrire :
def read_paths_and_hashes(root):
hashes = {}
for folder, _, files in os.walk(root):
for fn in files:
hashes[hash_file(Path(folder) / fn)] = fn
return hashesLa fonction determine_actions() sera le noyau de notre logique métier,
qui dit : "Étant donné ces deux ensembles de hachages et de noms de fichiers, que devrions-nous
copier/déplacer/supprimer ?". Elle prend des structures de données simples et retourne des structures de données simples :
def determine_actions(source_hashes, dest_hashes, source_folder, dest_folder):
for sha, filename in source_hashes.items():
if sha not in dest_hashes:
sourcepath = Path(source_folder) / filename
destpath = Path(dest_folder) / filename
yield "COPY", sourcepath, destpath
elif dest_hashes[sha] != filename:
olddestpath = Path(dest_folder) / dest_hashes[sha]
newdestpath = Path(dest_folder) / filename
yield "MOVE", olddestpath, newdestpath
for sha, filename in dest_hashes.items():
if sha not in source_hashes:
yield "DELETE", dest_folder / filenameNos tests agissent maintenant directement sur la fonction determine_actions() :
def test_when_a_file_exists_in_the_source_but_not_the_destination():
source_hashes = {"hash1": "fn1"}
dest_hashes = {}
actions = determine_actions(source_hashes, dest_hashes, Path("/src"), Path("/dst"))
assert list(actions) == [("COPY", Path("/src/fn1"), Path("/dst/fn1"))]
def test_when_a_file_has_been_renamed_in_the_source():
source_hashes = {"hash1": "fn1"}
dest_hashes = {"hash1": "fn2"}
actions = determine_actions(source_hashes, dest_hashes, Path("/src"), Path("/dst"))
assert list(actions) == [("MOVE", Path("/dst/fn2"), Path("/dst/fn1"))]Parce que nous avons démêlé la logique de notre programme—le code pour identifier les changements—des détails de bas niveau de l’I/O, nous pouvons facilement tester le cœur de notre code.
Avec cette approche, nous sommes passés du test de notre fonction de point d’entrée principale,
sync(), au test d’une fonction de niveau inférieur, determine_actions(). Vous pourriez
décider que c’est bien parce que sync() est maintenant si simple. Ou vous pourriez décider de
conserver quelques tests d’intégration/d’acceptation pour tester que sync(). Mais il y a
une autre option, qui est de modifier la fonction sync() pour qu’elle puisse
être testée en tant que test unitaire et test de bout en bout ; c’est une approche que Bob appelle
test de bout en bout (edge-to-edge testing).
3.3.1. Tester de Bout en Bout avec des Faux et l’Injection de Dépendances
Lorsque nous commençons à écrire un nouveau système, nous nous concentrons souvent d’abord sur la logique de base, en la pilotant avec des tests unitaires directs. À un moment donné, cependant, nous voulons tester de plus gros morceaux du système ensemble.
Nous pourrions retourner à nos tests de bout en bout, mais ceux-ci sont toujours aussi délicats à écrire et à maintenir qu’avant. Au lieu de cela, nous écrivons souvent des tests qui invoquent un système entier ensemble mais simulent l’I/O, en quelque sorte de bout en bout :
def sync(source, dest, filesystem=FileSystem()): (1)
source_hashes = filesystem.read(source) (2)
dest_hashes = filesystem.read(dest) (2)
for sha, filename in source_hashes.items():
if sha not in dest_hashes:
sourcepath = Path(source) / filename
destpath = Path(dest) / filename
filesystem.copy(sourcepath, destpath) (3)
elif dest_hashes[sha] != filename:
olddestpath = Path(dest) / dest_hashes[sha]
newdestpath = Path(dest) / filename
filesystem.move(olddestpath, newdestpath) (3)
for sha, filename in dest_hashes.items():
if sha not in source_hashes:
filesystem.delete(dest / filename) (3)| 1 | Notre fonction de niveau supérieur expose maintenant une nouvelle dépendance, un FileSystem. |
| 2 | Nous invoquons filesystem.read() pour produire notre dict de fichiers. |
| 3 | Nous invoquons les méthodes .copy(), .move() et .delete() du FileSystem
pour appliquer les changements que nous détectons. |
| Bien que nous utilisions l’injection de dépendances, il n’est pas nécessaire de définir une classe de base abstraite ou tout type d’interface explicite. Dans ce livre, nous montrons souvent des ABCs parce que nous espérons qu’ils vous aident à comprendre ce qu’est l’abstraction, mais ils ne sont pas nécessaires. La nature dynamique de Python signifie que nous pouvons toujours compter sur le duck typing. |
L’implémentation réelle (par défaut) de notre abstraction FileSystem fait de la vraie I/O :
class FileSystem:
def read(self, path):
return read_paths_and_hashes(path)
def copy(self, source, dest):
shutil.copyfile(source, dest)
def move(self, source, dest):
shutil.move(source, dest)
def delete(self, dest):
os.remove(dest)Mais la fausse est un wrapper autour de nos abstractions choisies, plutôt que de faire de la vraie I/O :
class FakeFilesystem:
def __init__(self, path_hashes): (1)
self.path_hashes = path_hashes
self.actions = [] (2)
def read(self, path):
return self.path_hashes[path] (1)
def copy(self, source, dest):
self.actions.append(('COPY', source, dest)) (2)
def move(self, source, dest):
self.actions.append(('MOVE', source, dest)) (2)
def delete(self, dest):
self.actions.append(('DELETE', dest)) (2)| 1 | Nous initialisons notre faux système de fichiers en utilisant l’abstraction que nous avons choisie pour représenter l’état du système de fichiers : des dictionnaires de hachages vers des chemins. |
| 2 | Les méthodes d’action dans notre FakeFileSystem ajoutent simplement un enregistrement à une liste
de .actions afin que nous puissions l’inspecter plus tard. Cela signifie que notre double de test est à la fois
un "faux" et un "espion".
|
Donc maintenant nos tests peuvent agir sur le vrai point d’entrée de niveau supérieur sync(),
mais ils le font en utilisant le FakeFilesystem(). En termes de leur
configuration et de leurs assertions, ils finissent par ressembler assez à ceux
que nous avons écrits lors du test direct de la fonction determine_actions()
du noyau fonctionnel :
def test_when_a_file_exists_in_the_source_but_not_the_destination():
fakefs = FakeFilesystem({
'/src': {"hash1": "fn1"},
'/dst': {},
})
sync('/src', '/dst', filesystem=fakefs)
assert fakefs.actions == [("COPY", Path("/src/fn1"), Path("/dst/fn1"))]
def test_when_a_file_has_been_renamed_in_the_source():
fakefs = FakeFilesystem({
'/src': {"hash1": "fn1"},
'/dst': {"hash1": "fn2"},
})
sync('/src', '/dst', filesystem=fakefs)
assert fakefs.actions == [("MOVE", Path("/dst/fn2"), Path("/dst/fn1"))]L’avantage de cette approche est que nos tests agissent sur exactement la même fonction qui est utilisée par notre code de production. L’inconvénient est que nous devons rendre nos composants avec état explicites et les passer partout. David Heinemeier Hansson, le créateur de Ruby on Rails, a décrit cela comme des "dommages de conception induits par les tests".
Dans les deux cas, nous pouvons maintenant travailler à corriger tous les bugs dans notre implémentation ; énumérer les tests pour tous les cas limites est maintenant beaucoup plus facile.
3.3.2. Pourquoi ne Pas Simplement le Patcher ?
À ce stade, vous vous grattez peut-être la tête en pensant :
"Pourquoi n’utilisez-vous pas simplement mock.patch et vous épargner l’effort ?"
Nous évitons d’utiliser des mocks dans ce livre et dans notre code de production aussi. Nous n’allons pas entrer dans une guerre sainte, mais notre instinct est que les frameworks de mocking, en particulier le monkeypatching, sont un code smell.
Au lieu de cela, nous aimons identifier clairement les responsabilités dans notre base de code, et séparer ces responsabilités en petits objets focalisés qui sont faciles à remplacer par un double de test.
Vous pouvez voir un exemple dans Événements et Bus de Messages (Events and the Message Bus),
où nous utilisons mock.patch() sur un module d’envoi d’e-mails, mais finalement nous
le remplaçons par une injection de dépendance explicite dans
Injection de Dépendances (Dependency Injection) (et Amorçage).
|
Nous avons trois raisons étroitement liées pour notre préférence :
-
Patcher la dépendance que vous utilisez permet de tester unitairement le code, mais cela ne fait rien pour améliorer la conception. Utiliser
mock.patchne permettra pas à votre code de fonctionner avec un flag--dry-run, ni ne vous aidera à exécuter contre un serveur FTP. Pour cela, vous devrez introduire des abstractions. -
Les tests qui utilisent des mocks ont tendance à être plus couplés aux détails d’implémentation de la base de code. C’est parce que les tests mock vérifient les interactions entre les choses : avons-nous appelé
shutil.copyavec les bons arguments ? Ce couplage entre code et test a tendance à rendre les tests plus fragiles, selon notre expérience. -
L’utilisation excessive de mocks conduit à des suites de tests compliquées qui n’expliquent pas le code.
| Concevoir pour la testabilité signifie vraiment concevoir pour l’extensibilité. Nous échangeons un peu plus de complexité contre une conception plus propre qui admet de nouveaux cas d’usage. |
Nous considérons le TDD comme une pratique de conception d’abord et une pratique de test ensuite. Les tests agissent comme un enregistrement de nos choix de conception et servent à expliquer le système à nous lorsque nous revenons au code après une longue absence.
Les tests qui utilisent trop de mocks sont submergés par du code de configuration qui cache l' histoire qui nous intéresse.
Steve Freeman a un excellent exemple de tests sur-mockés dans son talk "Test-Driven Development". Vous devriez également regarder ce talk PyCon, "Mocking and Patching Pitfalls", par notre estimé réviseur technique, Ed Jung, qui aborde également le mocking et ses alternatives.
Et tant que nous recommandons des talks, regardez le merveilleux Brandon Rhodes dans "Hoisting Your I/O". Ce n’est pas vraiment sur les mocks, mais plutôt sur la question générale de découpler la logique métier de l’I/O, dans lequel il utilise un exemple illustratif merveilleusement simple.
| Dans ce chapitre, nous avons passé beaucoup de temps à remplacer les tests de bout en bout par des tests unitaires. Cela ne signifie pas que nous pensons que vous ne devriez jamais utiliser de tests E2E ! Dans ce livre, nous montrons des techniques pour vous amener à une pyramide de tests décente avec autant de tests unitaires que possible, et avec le minimum de tests E2E nécessaires pour vous sentir confiant. Lisez la suite dans Récapitulatif : Règles Empiriques pour Différents Types de Tests pour plus de détails. |
3.4. Récapitulation
Nous verrons cette idée revenir encore et encore dans le livre : nous pouvons rendre nos systèmes plus faciles à tester et à maintenir en simplifiant l’interface entre notre logique métier et l’I/O désordonné. Trouver la bonne abstraction est délicat, mais voici quelques heuristiques et questions à vous poser :
-
Puis-je choisir une structure de données Python familière pour représenter l’état du système désordonné et ensuite essayer d’imaginer une fonction unique qui peut retourner cet état ?
-
Séparez le quoi du comment : puis-je utiliser une structure de données ou un DSL pour représenter les effets externes que je veux qu’il se produise, indépendamment de comment je prévois de les faire se produire ?
-
Où puis-je tracer une ligne entre mes systèmes, où puis-je découper une couture pour insérer cette abstraction ?
-
Quelle est une façon sensée de diviser les choses en composants avec des responsabilités différentes ? Quels concepts implicites puis-je rendre explicites ?
-
Quelles sont les dépendances, et quelle est la logique métier de base ?
La pratique rend moins imparfait ! Et maintenant retour à notre programmation régulière…
4. Notre Premier Cas d’Usage (Use Case) : API Flask et Couche de Service (Service Layer)
Retour à notre projet d’allocations ! Avant : nous pilotons notre app en parlant aux dépôts et au modèle de domaine montre le point que nous avons atteint à la fin de Pattern Repository (Dépôt), qui couvrait le pattern Dépôt (Repository).
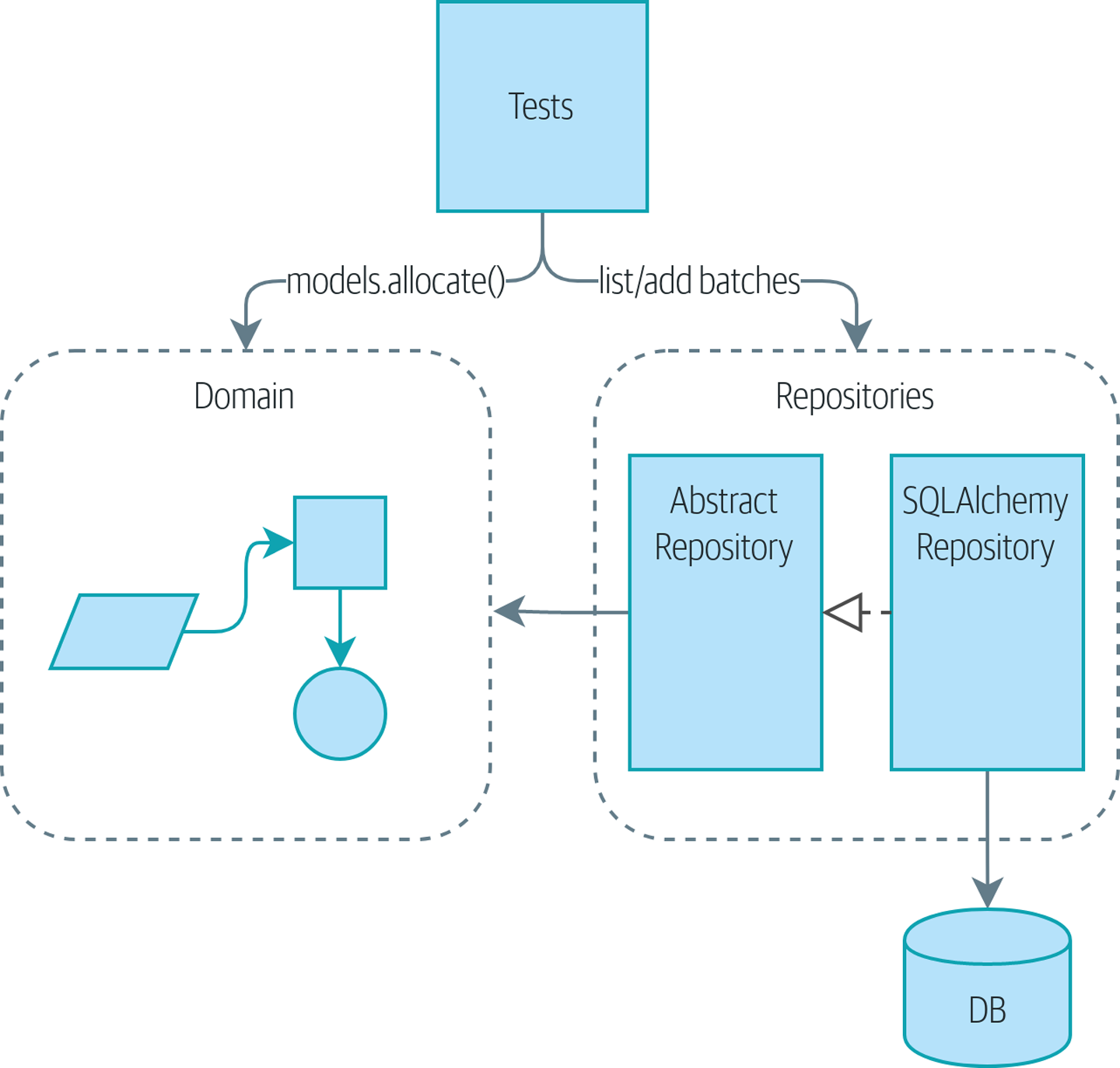
Dans ce chapitre, nous discutons des différences entre la logique d’orchestration, la logique métier, et le code d’interfaçage, et nous introduisons le pattern Couche de Service (Service Layer) pour prendre en charge l’orchestration de nos workflows et la définition des cas d’usage (use cases) de notre système.
Nous discuterons également des tests : en combinant la Couche de Service avec notre abstraction de dépôt sur la base de données, nous sommes capables d’écrire des tests rapides, non seulement de notre modèle de domaine mais de l’ensemble du workflow pour un cas d’usage.
La couche de service deviendra le principal moyen d’entrer dans notre app montre ce que nous visons : nous allons
ajouter une API Flask qui parlera à la couche de service, qui servira de
point d’entrée à notre modèle de domaine. Parce que notre couche de service dépend de
AbstractRepository, nous pouvons la tester unitairement en utilisant FakeRepository mais exécuter notre code de production en utilisant SqlAlchemyRepository.
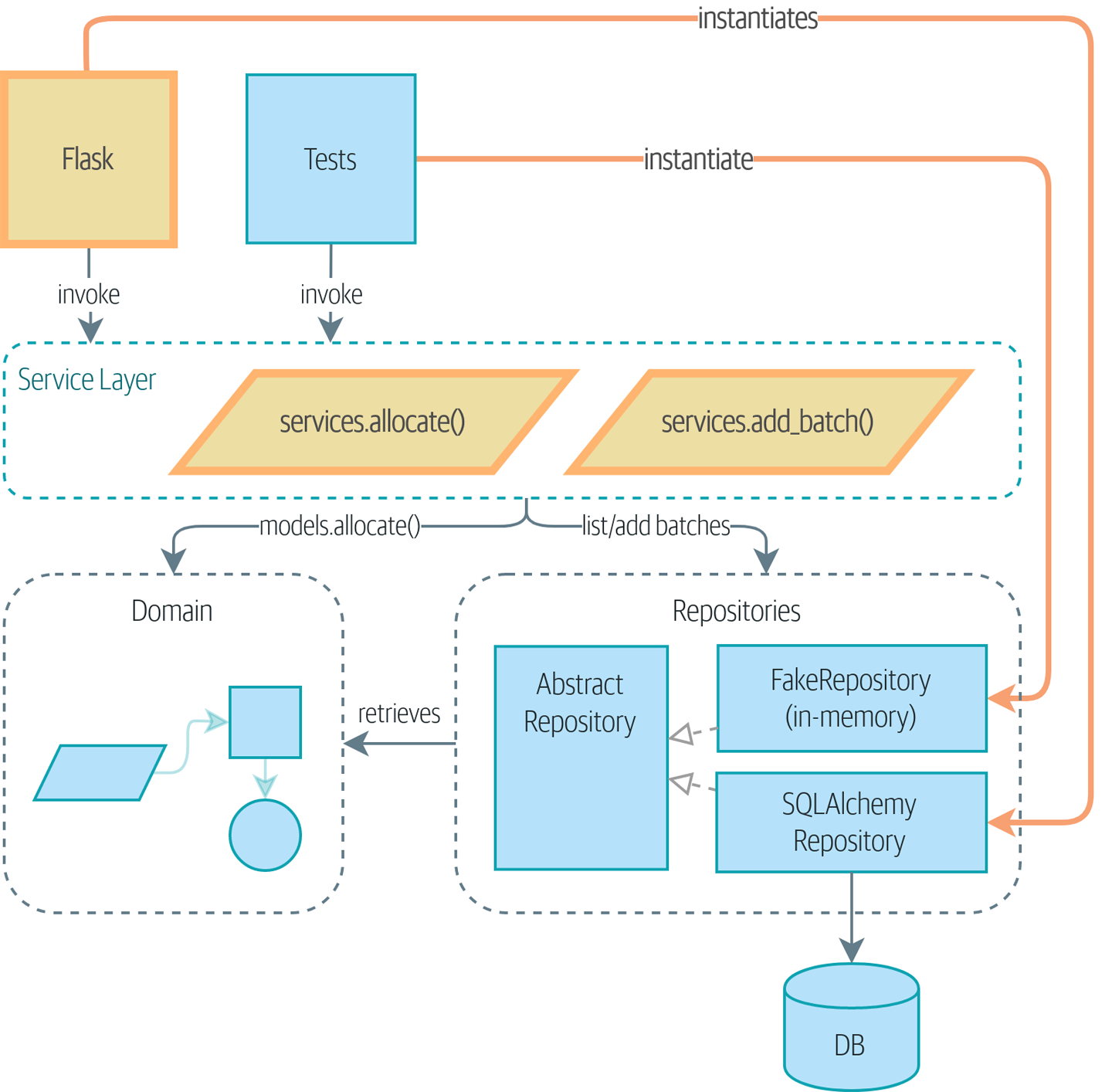
Dans nos diagrammes, nous utilisons la convention que les nouveaux composants sont mis en évidence avec du texte/lignes en gras (et couleur jaune/orange, si vous lisez une version numérique).
|
Le code de ce chapitre se trouve dans la branche chapter_04_service_layer sur GitHub : git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_04_service_layer # ou pour coder en parallèle, checkout Chapitre 2: git checkout chapter_02_repository |
4.1. Connecter Notre Application au Monde Réel
Comme toute bonne équipe agile, nous nous précipitons pour essayer de sortir un MVP et le mettre devant les utilisateurs pour commencer à recueillir des retours. Nous avons le cœur de notre modèle de domaine et le service de domaine dont nous avons besoin pour allouer les commandes, et nous avons l’interface de dépôt pour le stockage permanent.
Branchons toutes les pièces mobiles ensemble aussi rapidement que nous le pouvons et ensuite refactorisons vers une architecture plus propre. Voici notre plan :
-
Utiliser Flask pour mettre un point de terminaison API devant notre service de domaine
allocate. Câbler la session de base de données et notre dépôt. Le tester avec un test de bout en bout et un peu de SQL rapide et sale pour préparer les données de test. -
Refactoriser une couche de service qui peut servir d’abstraction pour capturer le cas d’usage et qui se situera entre Flask et notre modèle de domaine. Construire quelques tests de couche de service et montrer comment ils peuvent utiliser
FakeRepository. -
Expérimenter avec différents types de paramètres pour nos fonctions de couche de service ; montrer que l’utilisation de types de données primitifs permet aux clients de la couche de service (nos tests et notre API Flask) d’être découplés de la couche modèle.
4.2. Un Premier Test de Bout en Bout
Personne n’est intéressé par un long débat terminologique sur ce qui compte comme un test de bout en bout (E2E) versus un test fonctionnel versus un test d’acceptation versus un test d’intégration versus un test unitaire. Différents projets ont besoin de différentes combinaisons de tests, et nous avons vu des projets parfaitement réussis qui divisent simplement les choses en "tests rapides" et "tests lents".
Pour l’instant, nous voulons écrire un ou peut-être deux tests qui vont exercer un point de terminaison API "réel" (utilisant HTTP) et parler à une vraie base de données. Appelons-les tests de bout en bout parce que c’est l’un des noms les plus explicites.
Ce qui suit montre une première version :
@pytest.mark.usefixtures("restart_api")
def test_api_returns_allocation(add_stock):
sku, othersku = random_sku(), random_sku("other") (1)
earlybatch = random_batchref(1)
laterbatch = random_batchref(2)
otherbatch = random_batchref(3)
add_stock( (2)
[
(laterbatch, sku, 100, "2011-01-02"),
(earlybatch, sku, 100, "2011-01-01"),
(otherbatch, othersku, 100, None),
]
)
data = {"orderid": random_orderid(), "sku": sku, "qty": 3}
url = config.get_api_url() (3)
r = requests.post(f"{url}/allocate", json=data)
assert r.status_code == 201
assert r.json()["batchref"] == earlybatch| 1 | random_sku(), random_batchref(), et ainsi de suite sont de petites fonctions d’aide qui
génèrent des caractères aléatoires en utilisant le module uuid. Parce que
nous exécutons contre une vraie base de données maintenant, c’est une façon d’empêcher
divers tests et exécutions de s’interférer les uns avec les autres. |
| 2 | add_stock est une fixture d’aide qui cache simplement les détails de
l’insertion manuelle de lignes dans la base de données en utilisant SQL. Nous montrerons une meilleure
façon de faire cela plus tard dans le chapitre. |
| 3 | config.py est un module dans lequel nous gardons les informations de configuration. |
Tout le monde résout ces problèmes de différentes façons, mais vous allez avoir besoin d’une façon de faire tourner Flask, possiblement dans un conteneur, et de parler à une base de données Postgres. Si vous voulez voir comment nous l’avons fait, consultez Une Structure de Projet Modèle.
4.3. L’Implémentation Directe
En implémentant les choses de la façon la plus évidente, vous pourriez obtenir quelque chose comme ceci :
from flask import Flask, request
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
import config
import model
import orm
import repository
orm.start_mappers()
get_session = sessionmaker(bind=create_engine(config.get_postgres_uri()))
app = Flask(__name__)
@app.route("/allocate", methods=["POST"])
def allocate_endpoint():
session = get_session()
batches = repository.SqlAlchemyRepository(session).list()
line = model.OrderLine(
request.json["orderid"], request.json["sku"], request.json["qty"],
)
batchref = model.allocate(line, batches)
return {"batchref": batchref}, 201Jusqu’ici, tout va bien. Pas besoin de trop de vos bêtises "d’architecte astronaute", Bob et Harry, pourriez-vous penser.
Mais attendez une minute—il n’y a pas de commit. Nous ne sauvegardons pas réellement notre allocation dans la base de données. Maintenant nous avons besoin d’un deuxième test, soit un qui va inspecter l’état de la base de données après (pas très boîte noire), ou peut-être un qui vérifie que nous ne pouvons pas allouer une deuxième ligne si une première aurait déjà dû épuiser le lot :
@pytest.mark.usefixtures("restart_api")
def test_allocations_are_persisted(add_stock):
sku = random_sku()
batch1, batch2 = random_batchref(1), random_batchref(2)
order1, order2 = random_orderid(1), random_orderid(2)
add_stock(
[(batch1, sku, 10, "2011-01-01"), (batch2, sku, 10, "2011-01-02"),]
)
line1 = {"orderid": order1, "sku": sku, "qty": 10}
line2 = {"orderid": order2, "sku": sku, "qty": 10}
url = config.get_api_url()
# la première commande utilise tout le stock du lot 1
r = requests.post(f"{url}/allocate", json=line1)
assert r.status_code == 201
assert r.json()["batchref"] == batch1
# la deuxième commande devrait aller au lot 2
r = requests.post(f"{url}/allocate", json=line2)
assert r.status_code == 201
assert r.json()["batchref"] == batch2Pas tout à fait aussi joli, mais cela nous forcera à ajouter le commit.
4.4. Conditions d’Erreur qui Nécessitent des Vérifications de Base de Données
Si nous continuons comme ça, cependant, les choses vont devenir de plus en plus laides.
Supposons que nous voulons ajouter un peu de gestion d’erreurs. Que se passe-t-il si le domaine lève une erreur, pour un SKU qui est en rupture de stock ? Ou qu’en est-il d’un SKU qui n’existe même pas ? Ce n’est pas quelque chose que le domaine connaît, ni ne devrait le savoir. C’est plutôt une vérification de cohérence que nous devrions implémenter au niveau de la base de données, avant même d’invoquer le service de domaine.
Maintenant nous regardons deux tests de bout en bout supplémentaires :
@pytest.mark.usefixtures("restart_api")
def test_400_message_for_out_of_stock(add_stock): (1)
sku, small_batch, large_order = random_sku(), random_batchref(), random_orderid()
add_stock(
[(small_batch, sku, 10, "2011-01-01"),]
)
data = {"orderid": large_order, "sku": sku, "qty": 20}
url = config.get_api_url()
r = requests.post(f"{url}/allocate", json=data)
assert r.status_code == 400
assert r.json()["message"] == f"Out of stock for sku {sku}"
@pytest.mark.usefixtures("restart_api")
def test_400_message_for_invalid_sku(): (2)
unknown_sku, orderid = random_sku(), random_orderid()
data = {"orderid": orderid, "sku": unknown_sku, "qty": 20}
url = config.get_api_url()
r = requests.post(f"{url}/allocate", json=data)
assert r.status_code == 400
assert r.json()["message"] == f"Invalid sku {unknown_sku}"| 1 | Dans le premier test, nous essayons d’allouer plus d’unités que nous n’en avons en stock. |
| 2 | Dans le deuxième, le SKU n’existe tout simplement pas (parce que nous n’avons jamais appelé add_stock),
donc il est invalide en ce qui concerne notre app. |
Et bien sûr, nous pourrions l’implémenter dans l’app Flask aussi :
def is_valid_sku(sku, batches):
return sku in {b.sku for b in batches}
@app.route("/allocate", methods=["POST"])
def allocate_endpoint():
session = get_session()
batches = repository.SqlAlchemyRepository(session).list()
line = model.OrderLine(
request.json["orderid"], request.json["sku"], request.json["qty"],
)
if not is_valid_sku(line.sku, batches):
return {"message": f"Invalid sku {line.sku}"}, 400
try:
batchref = model.allocate(line, batches)
except model.OutOfStock as e:
return {"message": str(e)}, 400
session.commit()
return {"batchref": batchref}, 201Mais notre app Flask commence à paraître un peu lourde. Et notre nombre de tests E2E commence à devenir incontrôlable, et bientôt nous finirons avec une pyramide de tests inversée (ou "modèle de cône de glace", comme Bob aime l’appeler).
4.5. Introduire une Couche de Service, et Utiliser FakeRepository pour la Tester Unitairement
Si nous regardons ce que fait notre app Flask, il y a pas mal de ce que nous pourrions appeler de l'orchestration—récupérer des choses de notre dépôt, valider notre entrée contre l’état de la base de données, gérer les erreurs, et committer dans le chemin heureux. La plupart de ces choses n’ont rien à voir avec avoir un point de terminaison d’API web (vous en auriez besoin si vous construisiez une CLI, par exemple ; voir Remplacer l’Infrastructure : Tout Faire avec des CSVs), et ce ne sont pas vraiment des choses qui doivent être testées par des tests de bout en bout.
Il est souvent logique de séparer une couche de service, parfois appelée une couche d’orchestration ou une couche de cas d’usage (use-case layer).
Vous souvenez-vous du FakeRepository que nous avons préparé dans Une Brève Digression : Sur le Couplage et les Abstractions ?
class FakeRepository(repository.AbstractRepository):
def __init__(self, batches):
self._batches = set(batches)
def add(self, batch):
self._batches.add(batch)
def get(self, reference):
return next(b for b in self._batches if b.reference == reference)
def list(self):
return list(self._batches)Voici où il sera utile ; il nous permet de tester notre couche de service avec de jolis tests unitaires rapides :
def test_returns_allocation():
line = model.OrderLine("o1", "COMPLICATED-LAMP", 10)
batch = model.Batch("b1", "COMPLICATED-LAMP", 100, eta=None)
repo = FakeRepository([batch]) (1)
result = services.allocate(line, repo, FakeSession()) (2) (3)
assert result == "b1"
def test_error_for_invalid_sku():
line = model.OrderLine("o1", "NONEXISTENTSKU", 10)
batch = model.Batch("b1", "AREALSKU", 100, eta=None)
repo = FakeRepository([batch]) (1)
with pytest.raises(services.InvalidSku, match="Invalid sku NONEXISTENTSKU"):
services.allocate(line, repo, FakeSession()) (2) (3)| 1 | FakeRepository contient les objets Batch qui seront utilisés par notre test. |
| 2 | Notre module services (services.py) définira une fonction de couche de service allocate().
Elle se situera entre notre fonction allocate_endpoint()
dans la couche API et la fonction de service de domaine allocate() de
notre modèle de domaine.[20] |
| 3 | Nous avons également besoin d’une FakeSession pour simuler la session de base de données, comme montré dans
l’extrait de code suivant.
|
class FakeSession:
committed = False
def commit(self):
self.committed = TrueCette fausse session n’est qu’une solution temporaire. Nous nous en débarrasserons et rendrons
les choses encore plus agréables bientôt, dans Motif Unité de Travail (Unit of Work Pattern). Mais en attendant
le faux .commit() nous permet de migrer un troisième test depuis la couche E2E :
def test_commits():
line = model.OrderLine("o1", "OMINOUS-MIRROR", 10)
batch = model.Batch("b1", "OMINOUS-MIRROR", 100, eta=None)
repo = FakeRepository([batch])
session = FakeSession()
services.allocate(line, repo, session)
assert session.committed is True4.5.1. Une Fonction de Service Typique
Nous écrirons une fonction de service qui ressemble à quelque chose comme ceci :
class InvalidSku(Exception):
pass
def is_valid_sku(sku, batches):
return sku in {b.sku for b in batches}
def allocate(line: OrderLine, repo: AbstractRepository, session) -> str:
batches = repo.list() (1)
if not is_valid_sku(line.sku, batches): (2)
raise InvalidSku(f"Invalid sku {line.sku}")
batchref = model.allocate(line, batches) (3)
session.commit() (4)
return batchrefLes fonctions de couche de service typiques ont des étapes similaires :
| 1 | Nous récupérons des objets depuis le dépôt. |
| 2 | Nous faisons quelques vérifications ou assertions sur la requête par rapport à l’état actuel du monde. |
| 3 | Nous appelons un service de domaine. |
| 4 | Si tout va bien, nous sauvegardons/mettons à jour tout état que nous avons changé. |
Cette dernière étape est un peu insatisfaisante pour le moment, car notre couche de service est étroitement couplée à notre couche de base de données. Nous améliorerons cela dans Motif Unité de Travail (Unit of Work Pattern) avec le pattern Unité de Travail (Unit of Work).
Mais l’essentiel de la couche de service est là, et notre app Flask a maintenant l’air beaucoup plus propre :
@app.route("/allocate", methods=["POST"])
def allocate_endpoint():
session = get_session() (1)
repo = repository.SqlAlchemyRepository(session) (1)
line = model.OrderLine(
request.json["orderid"], request.json["sku"], request.json["qty"], (2)
)
try:
batchref = services.allocate(line, repo, session) (2)
except (model.OutOfStock, services.InvalidSku) as e:
return {"message": str(e)}, 400 (3)
return {"batchref": batchref}, 201 (3)| 1 | Nous instancions une session de base de données et quelques objets de dépôt. |
| 2 | Nous extrayons les commandes de l’utilisateur depuis la requête web et les passons à un service de domaine. |
| 3 | Nous retournons quelques réponses JSON avec les codes de statut appropriés. |
Les responsabilités de l’app Flask sont juste des trucs web standard : gestion de session par requête, analyse des informations des paramètres POST, codes de statut de réponse, et JSON. Toute la logique d’orchestration est dans la couche de cas d’usage/service, et la logique de domaine reste dans le domaine.
Finalement, nous pouvons réduire en toute confiance nos tests E2E à seulement deux, un pour le chemin heureux et un pour le chemin malheureux :
@pytest.mark.usefixtures("restart_api")
def test_happy_path_returns_201_and_allocated_batch(add_stock):
sku, othersku = random_sku(), random_sku("other")
earlybatch = random_batchref(1)
laterbatch = random_batchref(2)
otherbatch = random_batchref(3)
add_stock(
[
(laterbatch, sku, 100, "2011-01-02"),
(earlybatch, sku, 100, "2011-01-01"),
(otherbatch, othersku, 100, None),
]
)
data = {"orderid": random_orderid(), "sku": sku, "qty": 3}
url = config.get_api_url()
r = requests.post(f"{url}/allocate", json=data)
assert r.status_code == 201
assert r.json()["batchref"] == earlybatch
@pytest.mark.usefixtures("restart_api")
def test_unhappy_path_returns_400_and_error_message():
unknown_sku, orderid = random_sku(), random_orderid()
data = {"orderid": orderid, "sku": unknown_sku, "qty": 20}
url = config.get_api_url()
r = requests.post(f"{url}/allocate", json=data)
assert r.status_code == 400
assert r.json()["message"] == f"Invalid sku {unknown_sku}"Nous avons réussi à diviser nos tests en deux grandes catégories : des tests sur les trucs web, que nous implémentons de bout en bout ; et des tests sur les trucs d’orchestration, que nous pouvons tester contre la couche de service en mémoire.
4.6. Pourquoi Tout S’Appelle-t-il un Service ?
Certains d’entre vous se grattent probablement la tête à ce stade en essayant de comprendre exactement quelle est la différence entre un service de domaine et une couche de service.
Nous sommes désolés—nous n’avons pas choisi les noms, sinon nous aurions des façons beaucoup plus cool et amicales de parler de ces trucs.
Nous utilisons deux choses appelées un service dans ce chapitre. La première est un service d’application (notre couche de service). Son travail est de gérer les requêtes du monde extérieur et d'orchestrer une opération. Ce que nous voulons dire est que la couche de service pilote l’application en suivant un ensemble d’étapes simples :
-
Obtenir des données depuis la base de données
-
Mettre à jour le modèle de domaine
-
Persister tous les changements
C’est le genre de travail ennuyeux qui doit se produire pour chaque opération dans votre système, et le garder séparé de la logique métier aide à garder les choses ordonnées.
Le deuxième type de service est un service de domaine. C’est le nom pour une pièce de
logique qui appartient au modèle de domaine mais ne se trouve pas naturellement dans une
entité ou un objet de valeur avec état. Par exemple, si vous construisiez une application de
panier d’achat, vous pourriez choisir de construire les règles de taxation comme un service de domaine.
Calculer les taxes est un travail séparé de la mise à jour du panier, et c’est une
partie importante du modèle, mais cela ne semble pas correct d’avoir une entité persistée pour
le travail. Au lieu de cela, une classe TaxCalculator sans état ou une fonction calculate_tax
peut faire le travail.
4.7. Mettre les Choses dans des Dossiers pour Voir Où Tout Appartient
À mesure que notre application grandit, nous aurons besoin de continuer à ranger notre structure de répertoires. La disposition de notre projet nous donne des indices utiles sur quels types d' objets nous trouverons dans chaque fichier.
Voici une façon dont nous pourrions organiser les choses :
.
├── config.py
├── domain (1)
│ ├── __init__.py
│ └── model.py
├── service_layer (2)
│ ├── __init__.py
│ └── services.py
├── adapters (3)
│ ├── __init__.py
│ ├── orm.py
│ └── repository.py
├── entrypoints (4)
│ ├── __init__.py
│ └── flask_app.py
└── tests
├── __init__.py
├── conftest.py
├── unit
│ ├── test_allocate.py
│ ├── test_batches.py
│ └── test_services.py
├── integration
│ ├── test_orm.py
│ └── test_repository.py
└── e2e
└── test_api.py| 1 | Ayons un dossier pour notre modèle de domaine. Actuellement c’est juste un fichier,
mais pour une application plus complexe, vous pourriez avoir un fichier par classe ; vous
pourriez avoir des classes parentes d’aide pour Entity, ValueObject, et
Aggregate, et vous pourriez ajouter un exceptions.py pour les exceptions de couche de domaine
et, comme vous le verrez dans Architecture Événementielle, commands.py et events.py.
|
| 2 | Nous distinguerons la couche de service. Actuellement c’est juste un fichier appelé services.py pour nos fonctions de couche de service. Vous pourriez ajouter des exceptions de couche de service ici, et comme vous le verrez dans TDD en Vitesse Supérieure et en Vitesse Inférieure, nous ajouterons unit_of_work.py. |
| 3 | Adapters est un clin d’œil à la terminologie ports et adaptateurs. Cela se remplira avec toutes les autres abstractions autour de l’I/O externe (par ex., un redis_client.py). Strictement parlant, vous appelleriez ceux-ci des adaptateurs secondaires ou pilotés, ou parfois des adaptateurs orientés vers l’intérieur. |
| 4 | Les entrypoints sont les endroits d’où nous pilotons notre application. Dans la terminologie officielle ports et adaptateurs, ce sont également des adaptateurs, et sont appelés adaptateurs primaires, pilotant, ou orientés vers l’extérieur. |
Qu’en est-il des ports ? Comme vous vous en souvenez peut-être, ce sont les interfaces abstraites que les adaptateurs implémentent. Nous avons tendance à les garder dans le même fichier que les adaptateurs qui les implémentent.
4.8. Récapitulation
Ajouter la couche de service nous a vraiment apporté pas mal de choses :
-
Nos points de terminaison d’API Flask deviennent très minces et faciles à écrire : leur seule responsabilité est de faire des "trucs web", comme analyser le JSON et produire les bons codes HTTP pour les cas heureux ou malheureux.
-
Nous avons défini une API claire pour notre domaine, un ensemble de cas d’usage ou de points d’entrée qui peuvent être utilisés par n’importe quel adaptateur sans avoir besoin de savoir quoi que ce soit sur nos classes de modèle de domaine—que ce soit une API, une CLI (voir Remplacer l’Infrastructure : Tout Faire avec des CSVs), ou les tests ! Ils sont un adaptateur pour notre domaine aussi.
-
Nous pouvons écrire des tests en "vitesse supérieure" en utilisant la couche de service, nous laissant libres de refactoriser le modèle de domaine de la façon que nous jugeons appropriée. Tant que nous pouvons toujours délivrer les mêmes cas d’usage, nous pouvons expérimenter avec de nouvelles conceptions sans avoir besoin de réécrire un tas de tests.
-
Et notre pyramide de tests a bonne allure—la majorité de nos tests sont des tests unitaires rapides, avec juste le strict minimum de tests E2E et d’intégration.
4.8.1. Le DIP en Action
Dépendances abstraites de la couche de service montre les
dépendances de notre couche de service : le modèle de domaine
et AbstractRepository (le port, dans la terminologie ports et adaptateurs).
Lorsque nous exécutons les tests, Les tests fournissent une implémentation de la dépendance abstraite montre
comment nous implémentons les dépendances abstraites en utilisant FakeRepository (l'
adaptateur).
Et lorsque nous exécutons réellement notre app, nous échangeons la dépendance "réelle" montrée dans Dépendances à l’exécution.
[ditaa, apwp_0403]
+-----------------------------+
| Service Layer |
+-----------------------------+
| |
| | depends on abstraction
V V
+------------------+ +--------------------+
| Domain Model | | AbstractRepository |
| | | (Port) |
+------------------+ +--------------------+
[ditaa, apwp_0404]
+-----------------------------+
| Tests |-------------\
+-----------------------------+ |
| |
V |
+-----------------------------+ |
| Service Layer | provides |
+-----------------------------+ |
| | |
V V |
+------------------+ +--------------------+ |
| Domain Model | | AbstractRepository | |
+------------------+ +--------------------+ |
^ |
implements | |
| |
+----------------------+ |
| FakeRepository |<--/
| (in–memory) |
+----------------------+
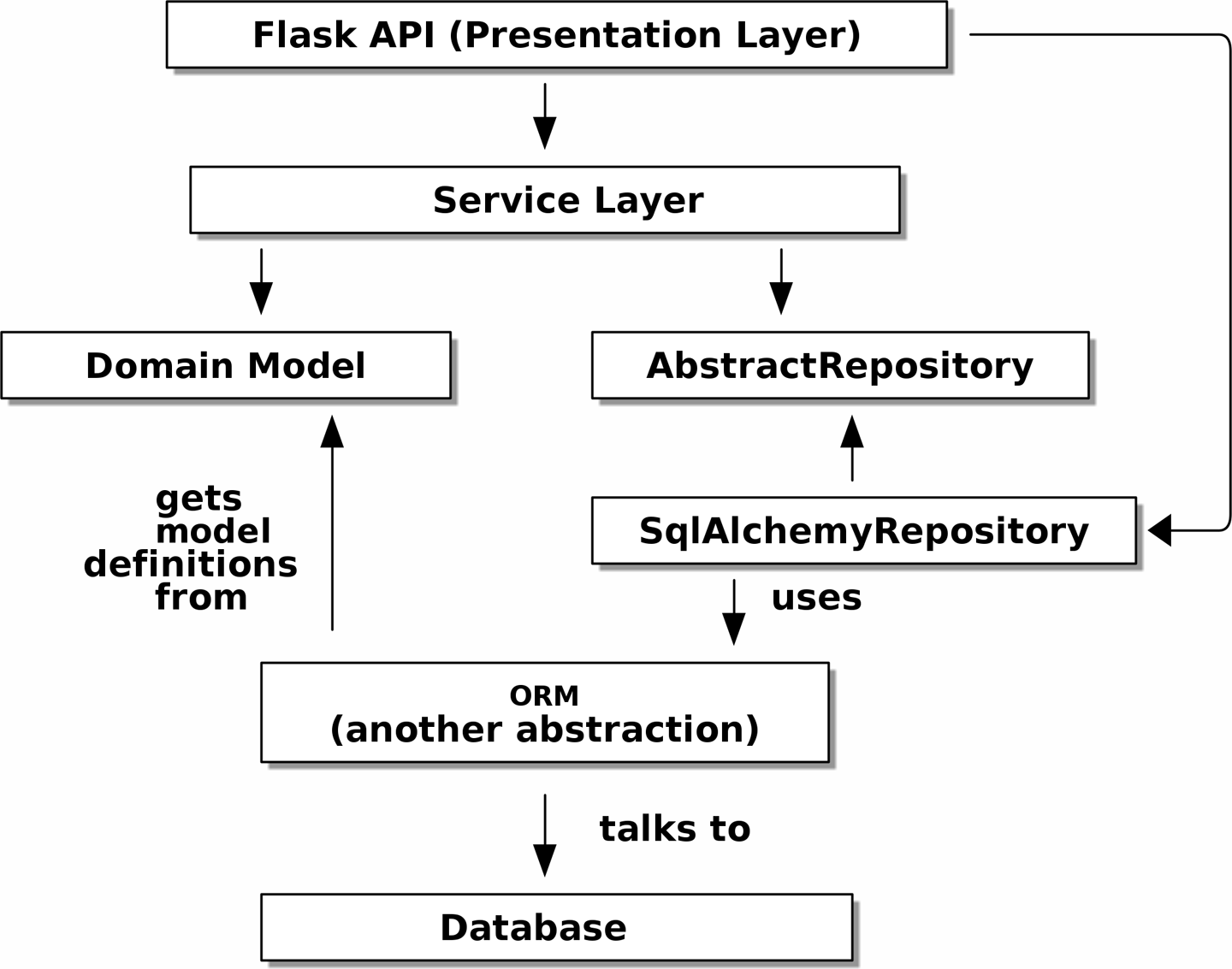
[ditaa, apwp_0405]
+--------------------------------+
| Flask API (Presentation Layer) |-----------\
+--------------------------------+ |
| |
V |
+-----------------------------+ |
| Service Layer | |
+-----------------------------+ |
| | |
V V |
+------------------+ +--------------------+ |
| Domain Model | | AbstractRepository | |
+------------------+ +--------------------+ |
^ ^ |
| | |
gets | +----------------------+ |
model | | SqlAlchemyRepository |<--/
definitions| +----------------------+
from | | uses
| V
+-----------------------+
| ORM |
| (another abstraction) |
+-----------------------+
|
| talks to
V
+------------------------+
| Database |
+------------------------+
Merveilleux.
Faisons une pause pour Couche de service : les compromis, dans lequel nous considérons les avantages et les inconvénients d’avoir une couche de service du tout.
| Avantages | Inconvénients |
|---|---|
|
|
Mais il reste encore quelques bits de maladresse à ranger :
-
La couche de service est toujours étroitement couplée au domaine, parce que son API est exprimée en termes d’objets
OrderLine. Dans TDD en Vitesse Supérieure et en Vitesse Inférieure, nous corrigerons cela et parlerons de la façon dont la couche de service permet un TDD plus productif. -
La couche de service est étroitement couplée à un objet
session. Dans Motif Unité de Travail (Unit of Work Pattern), nous introduirons un pattern de plus qui fonctionne étroitement avec les patterns Dépôt et Couche de Service, le pattern Unité de Travail (Unit of Work), et tout sera absolument charmant. Vous verrez !
5. TDD en Vitesse Supérieure et en Vitesse Inférieure
Nous avons introduit la couche de service pour capturer certaines des responsabilités d’orchestration supplémentaires dont nous avons besoin pour une application fonctionnelle. La couche de service nous aide à définir clairement nos cas d’usage et le workflow pour chacun : ce que nous devons obtenir de nos dépôts, quelles pré-vérifications et validation de l’état actuel nous devons faire, et ce que nous sauvegardons à la fin.
Mais actuellement, beaucoup de nos tests unitaires opèrent à un niveau inférieur, agissant directement sur le modèle. Dans ce chapitre, nous discuterons des compromis impliqués dans le déplacement de ces tests vers le niveau de la couche de service, et de quelques directives de test plus générales.
5.1. À Quoi Ressemble Notre Pyramide de Tests ?
Voyons ce que ce passage à l’utilisation d’une couche de service, avec ses propres tests de couche de service, fait à notre pyramide de tests :
$ grep -c test_ **/test_*.py
tests/unit/test_allocate.py:4
tests/unit/test_batches.py:8
tests/unit/test_services.py:3
tests/integration/test_orm.py:6
tests/integration/test_repository.py:2
tests/e2e/test_api.py:2Pas mal ! Nous avons 15 tests unitaires, 8 tests d’intégration, et juste 2 tests de bout en bout. C’est déjà une pyramide de tests à l’allure saine.
5.2. Les Tests de Couche de Domaine Devraient-ils Passer à la Couche de Service ?
Voyons ce qui se passe si nous poussons cela un peu plus loin. Puisque nous pouvons tester notre logiciel contre la couche de service, nous n’avons pas vraiment besoin de tests pour le modèle de domaine plus. Au lieu de cela, nous pourrions réécrire tous les tests de niveau domaine de Modélisation du Domaine en termes de la couche de service :
# test de couche de domaine :
def test_prefers_current_stock_batches_to_shipments():
in_stock_batch = Batch("in-stock-batch", "RETRO-CLOCK", 100, eta=None)
shipment_batch = Batch("shipment-batch", "RETRO-CLOCK", 100, eta=tomorrow)
line = OrderLine("oref", "RETRO-CLOCK", 10)
allocate(line, [in_stock_batch, shipment_batch])
assert in_stock_batch.available_quantity == 90
assert shipment_batch.available_quantity == 100
# test de couche de service :
def test_prefers_warehouse_batches_to_shipments():
in_stock_batch = Batch("in-stock-batch", "RETRO-CLOCK", 100, eta=None)
shipment_batch = Batch("shipment-batch", "RETRO-CLOCK", 100, eta=tomorrow)
repo = FakeRepository([in_stock_batch, shipment_batch])
session = FakeSession()
line = OrderLine('oref', "RETRO-CLOCK", 10)
services.allocate(line, repo, session)
assert in_stock_batch.available_quantity == 90
assert shipment_batch.available_quantity == 100Pourquoi voudrions-nous faire cela ?
Les tests sont censés nous aider à changer notre système sans crainte, mais souvent nous voyons des équipes écrire trop de tests contre leur modèle de domaine. Cela cause des problèmes lorsqu’elles viennent modifier leur base de code et trouvent qu’elles doivent mettre à jour des dizaines voire des centaines de tests unitaires.
Cela a du sens si vous vous arrêtez pour réfléchir à l’objectif des tests automatisés. Nous utilisons des tests pour imposer qu’une propriété du système ne change pas pendant que nous travaillons. Nous utilisons des tests pour vérifier que l’API continue de retourner 200, que la session de base de données continue de committer, et que les commandes sont toujours allouées.
Si nous changeons accidentellement l’un de ces comportements, nos tests vont se casser. Le revers de la médaille, cependant, est que si nous voulons changer la conception de notre code, tous les tests qui dépendent directement de ce code échoueront également.
À mesure que nous progressons dans le livre, vous verrez comment la couche de service forme une API pour notre système que nous pouvons piloter de plusieurs façons. Tester contre cette API réduit la quantité de code que nous devons changer lorsque nous refactorisons notre modèle de domaine. Si nous nous limitons à tester uniquement contre la couche de service, nous n’aurons aucun test qui interagit directement avec des méthodes ou attributs "privés" sur nos objets modèle, ce qui nous laisse plus libres de les refactoriser.
| Chaque ligne de code que nous mettons dans un test est comme une goutte de colle, maintenant le système dans une forme particulière. Plus nous avons de tests de bas niveau, plus il sera difficile de changer les choses. |
5.3. Sur la Décision de Quels Types de Tests Écrire
Vous vous demandez peut-être : "Devrais-je réécrire tous mes tests unitaires, alors ? Est-il mal d’écrire des tests contre le modèle de domaine ?" Pour répondre à ces questions, il est important de comprendre le compromis entre le couplage et le retour de conception (voir Le spectre de tests).

[ditaa, apwp_0501] | Faible retour Fort retour | | Faible barrière au changement Forte barrière au changement | | Couverture système élevée Couverture focalisée | | | | <--------- ----------> | | | | Tests API Tests de Couche de Service Tests de Domaine |
La programmation extrême (XP) nous exhorte à "écouter le code". Lorsque nous écrivons des tests, nous pourrions trouver que le code est difficile à utiliser ou remarquer un code smell. C’est un déclencheur pour nous de refactoriser, et de reconsidérer notre conception.
Nous n’obtenons ce retour, cependant, que lorsque nous travaillons étroitement avec le code cible. Un test pour l’API HTTP ne nous dit rien sur la conception fine de nos objets, parce qu’il se situe à un niveau d’abstraction beaucoup plus élevé.
D’un autre côté, nous pouvons réécrire toute notre application et, tant que nous ne changeons pas les URLs ou les formats de requête, nos tests HTTP continueront de passer. Cela nous donne confiance que des changements à grande échelle, comme changer le schéma de base de données, n’ont pas cassé notre code.
À l’autre bout du spectre, les tests que nous avons écrits dans Modélisation du Domaine nous ont aidés à élaborer notre compréhension des objets dont nous avons besoin. Les tests nous ont guidés vers une conception qui a du sens et se lit dans le langage du domaine. Lorsque nos tests se lisent dans le langage du domaine, nous nous sentons à l’aise que notre code correspond à notre intuition sur le problème que nous essayons de résoudre.
Parce que les tests sont écrits dans le langage du domaine, ils agissent comme une documentation vivante pour notre modèle. Un nouveau membre de l’équipe peut lire ces tests pour rapidement comprendre comment le système fonctionne et comment les concepts de base sont liés.
Nous "esquissons" souvent de nouveaux comportements en écrivant des tests à ce niveau pour voir comment le code pourrait se présenter. Lorsque nous voulons améliorer la conception du code, cependant, nous devrons remplacer ou supprimer ces tests, parce qu’ils sont étroitement couplés à une implémentation particulière.
5.4. Vitesse Supérieure et Vitesse Inférieure
La plupart du temps, lorsque nous ajoutons une nouvelle fonctionnalité ou corrigeons un bug, nous n’avons pas besoin de faire de changements importants au modèle de domaine. Dans ces cas, nous préférons écrire des tests contre les services en raison du couplage plus faible et de la couverture plus élevée.
Par exemple, lors de l’écriture d’une fonction add_stock ou d’une fonctionnalité cancel_order,
nous pouvons travailler plus rapidement et avec moins de couplage en écrivant des tests contre la
couche de service.
Lorsque nous démarrons un nouveau projet ou lorsque nous rencontrons un problème particulièrement épineux, nous redescendons à l’écriture de tests contre le modèle de domaine pour obtenir un meilleur retour et une documentation exécutable de notre intention.
La métaphore que nous utilisons est celle du changement de vitesses. Lors du démarrage d’un voyage, le vélo doit être en vitesse inférieure pour pouvoir surmonter l’inertie. Une fois que nous sommes partis et en mouvement, nous pouvons aller plus vite et plus efficacement en passant en vitesse supérieure ; mais si nous rencontrons soudainement une colline abrupte ou sommes forcés de ralentir par un danger, nous redescendons en vitesse inférieure jusqu’à ce que nous puissions reprendre de la vitesse.
5.5. Découpler Complètement les Tests de Couche de Service du Domaine
Nous avons encore des dépendances directes sur le domaine dans nos tests de couche de service, parce que nous utilisons des objets de domaine pour configurer nos données de test et pour invoquer nos fonctions de couche de service.
Pour avoir une couche de service qui est complètement découplée du domaine, nous devons réécrire son API pour qu’elle fonctionne en termes de primitives.
Notre couche de service prend actuellement un objet de domaine OrderLine :
def allocate(line: OrderLine, repo: AbstractRepository, session) -> str:À quoi cela ressemblerait-il si ses paramètres étaient tous des types primitifs ?
def allocate(
orderid: str, sku: str, qty: int,
repo: AbstractRepository, session
) -> str:Nous réécrivons les tests en ces termes également :
def test_returns_allocation():
batch = model.Batch("batch1", "COMPLICATED-LAMP", 100, eta=None)
repo = FakeRepository([batch])
result = services.allocate("o1", "COMPLICATED-LAMP", 10, repo, FakeSession())
assert result == "batch1"Mais nos tests dépendent toujours du domaine, parce que nous instancions toujours manuellement
des objets Batch. Donc, si un jour nous décidons de refactoriser massivement la façon dont notre modèle Batch
fonctionne, nous devrons changer un tas de tests.
5.5.1. Atténuation : Garder Toutes les Dépendances de Domaine dans les Fonctions de Fixture
Nous pourrions au moins abstraire cela en une fonction d’aide ou une fixture
dans nos tests. Voici une façon de faire cela, en ajoutant une fonction factory
sur FakeRepository :
class FakeRepository(set):
@staticmethod
def for_batch(ref, sku, qty, eta=None):
return FakeRepository([
model.Batch(ref, sku, qty, eta),
])
...
def test_returns_allocation():
repo = FakeRepository.for_batch("batch1", "COMPLICATED-LAMP", 100, eta=None)
result = services.allocate("o1", "COMPLICATED-LAMP", 10, repo, FakeSession())
assert result == "batch1"Au moins cela déplacerait toutes les dépendances de nos tests sur le domaine en un seul endroit.
5.5.2. Ajouter un Service Manquant
Nous pourrions aller encore plus loin, cependant. Si nous avions un service pour ajouter du stock, nous pourrions l’utiliser et rendre nos tests de couche de service complètement exprimés en termes des cas d’usage officiels de la couche de service, supprimant toutes les dépendances sur le domaine :
def test_add_batch():
repo, session = FakeRepository([]), FakeSession()
services.add_batch("b1", "CRUNCHY-ARMCHAIR", 100, None, repo, session)
assert repo.get("b1") is not None
assert session.committed| En général, si vous vous trouvez à avoir besoin de faire des trucs de couche de domaine directement dans vos tests de couche de service, cela peut être une indication que votre couche de service est incomplète. |
Et l’implémentation ne fait que deux lignes :
def add_batch(
ref: str, sku: str, qty: int, eta: Optional[date],
repo: AbstractRepository, session,
) -> None:
repo.add(model.Batch(ref, sku, qty, eta))
session.commit()
def allocate(
orderid: str, sku: str, qty: int,
repo: AbstractRepository, session
) -> str:
Devriez-vous écrire un nouveau service juste parce que cela aiderait à supprimer
les dépendances de vos tests ? Probablement pas. Mais dans ce cas, nous
aurions presque certainement besoin d’un service add_batch un jour de toute façon.
|
Cela nous permet maintenant de réécrire tous nos tests de couche de service purement en termes des services eux-mêmes, en utilisant uniquement des primitives, et sans aucune dépendance sur le modèle :
def test_allocate_returns_allocation():
repo, session = FakeRepository([]), FakeSession()
services.add_batch("batch1", "COMPLICATED-LAMP", 100, None, repo, session)
result = services.allocate("o1", "COMPLICATED-LAMP", 10, repo, session)
assert result == "batch1"
def test_allocate_errors_for_invalid_sku():
repo, session = FakeRepository([]), FakeSession()
services.add_batch("b1", "AREALSKU", 100, None, repo, session)
with pytest.raises(services.InvalidSku, match="Invalid sku NONEXISTENTSKU"):
services.allocate("o1", "NONEXISTENTSKU", 10, repo, FakeSession())C’est un très bon endroit où être. Nos tests de couche de service ne dépendent que de la couche de service elle-même, nous laissant complètement libres de refactoriser le modèle comme nous le jugeons approprié.
5.6. Porter l’Amélioration jusqu’aux Tests E2E
De la même manière que l’ajout de add_batch a aidé à découpler nos tests de couche de service
du modèle, l’ajout d’un point de terminaison API pour ajouter un lot supprimerait
le besoin de la laide fixture add_stock, et nos tests E2E pourraient être libres
de ces requêtes SQL codées en dur et de la dépendance directe à la base de données.
Grâce à notre fonction de service, ajouter le point de terminaison est facile, avec juste un peu de manipulation JSON et un seul appel de fonction requis :
@app.route("/add_batch", methods=["POST"])
def add_batch():
session = get_session()
repo = repository.SqlAlchemyRepository(session)
eta = request.json["eta"]
if eta is not None:
eta = datetime.fromisoformat(eta).date()
services.add_batch(
request.json["ref"],
request.json["sku"],
request.json["qty"],
eta,
repo,
session,
)
return "OK", 201| Pensez-vous à vous-même, POST vers /add_batch ? Ce n’est pas très RESTful ! Vous avez tout à fait raison. Nous sommes joyeusement négligents, mais si vous aimeriez rendre tout plus RESTful, peut-être un POST vers /batches, alors allez-y ! Parce que Flask est un adaptateur mince, ce sera facile. Voir l’encadré suivant. |
Et nos requêtes SQL codées en dur de conftest.py sont remplacées par des appels API, ce qui signifie que les tests API n’ont pas d’autres dépendances que l’API, ce qui est également agréable :
def post_to_add_batch(ref, sku, qty, eta):
url = config.get_api_url()
r = requests.post(
f"{url}/add_batch", json={"ref": ref, "sku": sku, "qty": qty, "eta": eta}
)
assert r.status_code == 201
@pytest.mark.usefixtures("postgres_db")
@pytest.mark.usefixtures("restart_api")
def test_happy_path_returns_201_and_allocated_batch():
sku, othersku = random_sku(), random_sku("other")
earlybatch = random_batchref(1)
laterbatch = random_batchref(2)
otherbatch = random_batchref(3)
post_to_add_batch(laterbatch, sku, 100, "2011-01-02")
post_to_add_batch(earlybatch, sku, 100, "2011-01-01")
post_to_add_batch(otherbatch, othersku, 100, None)
data = {"orderid": random_orderid(), "sku": sku, "qty": 3}
url = config.get_api_url()
r = requests.post(f"{url}/allocate", json=data)
assert r.status_code == 201
assert r.json()["batchref"] == earlybatch5.7. Récapitulation
Une fois que vous avez une couche de service en place, vous pouvez vraiment déplacer la majorité de votre couverture de test vers les tests unitaires et développer une pyramide de tests saine.
Quelques choses aideront en chemin :
-
Exprimez votre couche de service en termes de primitives plutôt que d’objets de domaine.
-
Dans un monde idéal, vous aurez tous les services dont vous avez besoin pour pouvoir tester entièrement contre la couche de service, plutôt que de bidouiller l’état via des dépôts ou la base de données. Cela porte ses fruits dans vos tests de bout en bout également.
Au chapitre suivant !
6. Motif Unité de Travail (Unit of Work Pattern)
Dans ce chapitre, nous allons introduire la dernière pièce du puzzle qui relie ensemble les motifs Dépôt (Repository) et Couche de Service (Service Layer) : le motif Unité de Travail (Unit of Work).
Si le motif Dépôt (Repository) est notre abstraction de l’idée de stockage persistant, le motif Unité de Travail (Unit of Work, UoW) est notre abstraction de l’idée d'opérations atomiques. Il nous permettra enfin de découpler complètement notre couche de service de la couche de données.
Sans UoW : l’API parle directement à trois couches montre qu’actuellement, beaucoup de communication se produit à travers les couches de notre infrastructure : l’API parle directement à la couche de base de données pour démarrer une session, elle parle à la couche dépôt pour initialiser SQLAlchemyRepository, et elle parle à la couche de service pour lui demander d’allouer.
|
Le code pour ce chapitre se trouve dans la branche chapter_06_uow sur GitHub : git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_06_uow # ou pour coder en même temps, récupérez le Chapitre 4 : git checkout chapter_04_service_layer |
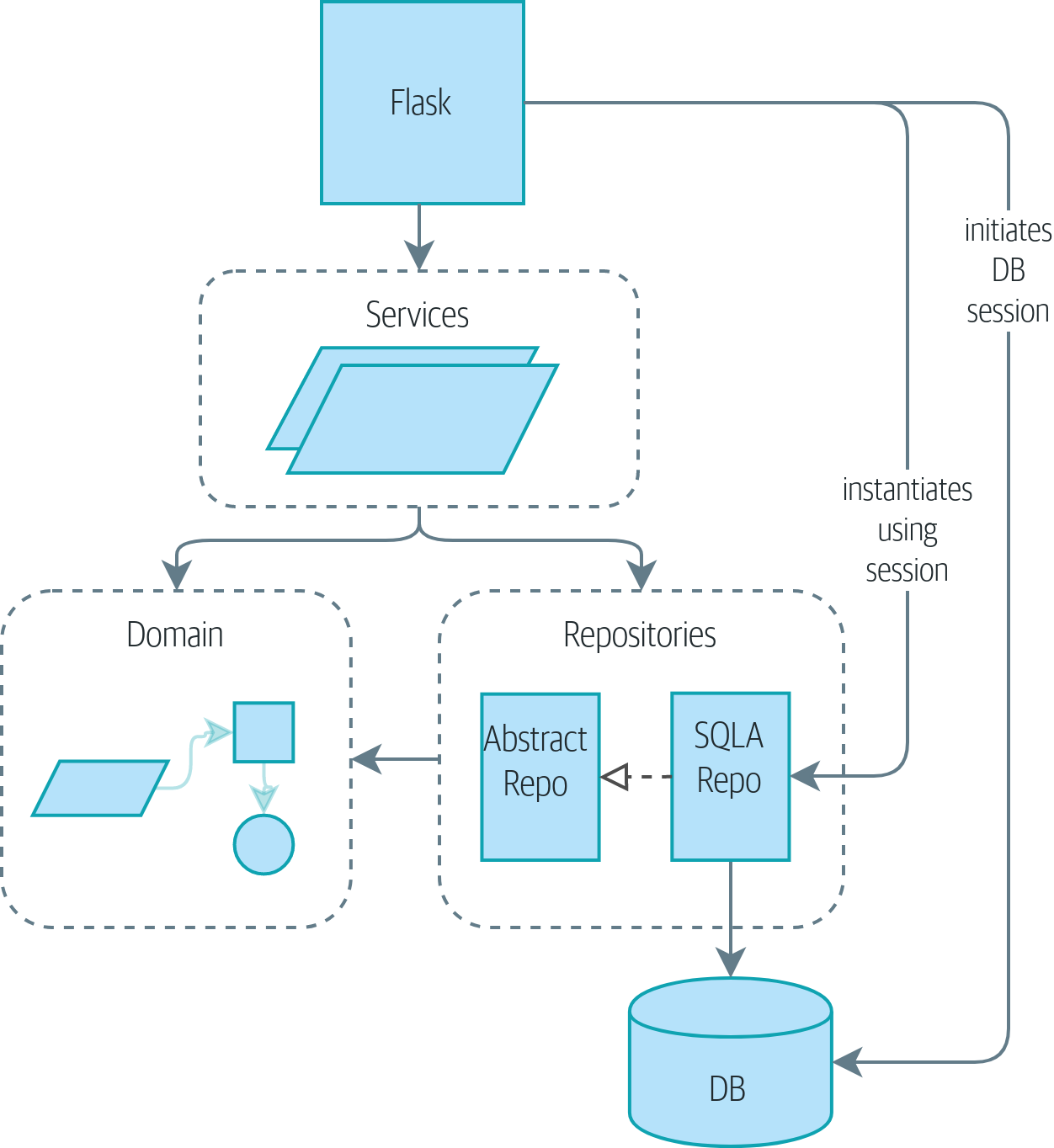
Avec UoW : l’UoW gère maintenant l’état de la base de données montre notre état cible. L’API Flask ne fait maintenant que deux choses : elle initialise une unité de travail et elle invoque un service. Le service collabore avec l’UoW (nous aimons penser que l’UoW fait partie de la couche de service), mais ni la fonction de service elle-même ni Flask n’ont plus besoin de parler directement à la base de données.
Et nous allons tout faire en utilisant une magnifique syntaxe Python, un gestionnaire de contexte (context manager).
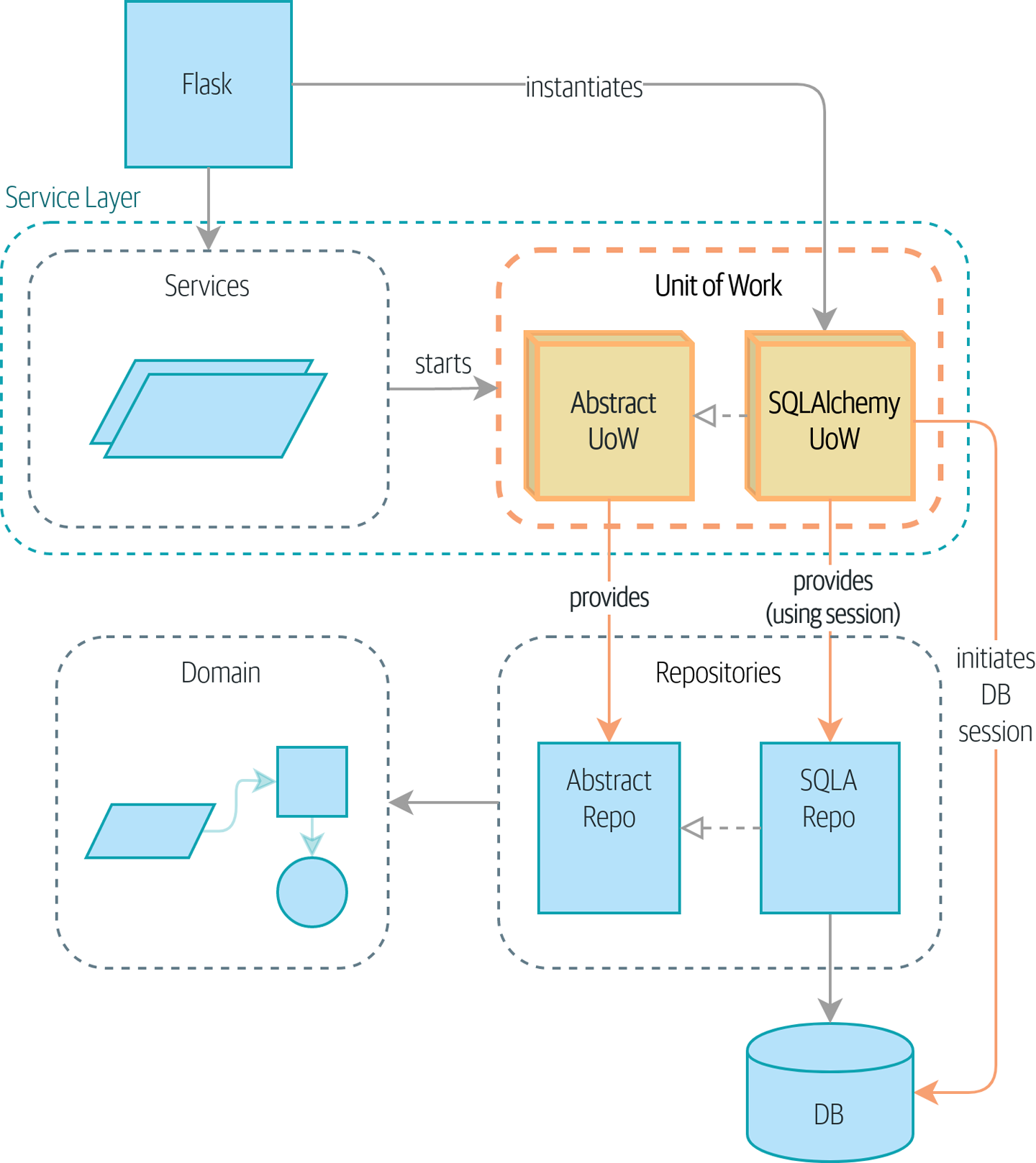
6.1. L’Unité de Travail collabore avec le Dépôt
Voyons l’unité de travail (ou UoW, que nous prononçons "you-wow") en action. Voici à quoi ressemblera la couche de service quand nous aurons terminé :
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork,
) -> str:
line = OrderLine(orderid, sku, qty)
with uow: (1)
batches = uow.batches.list() (2)
...
batchref = model.allocate(line, batches)
uow.commit() (3)| 1 | Nous allons démarrer une UoW comme un gestionnaire de contexte (context manager). |
| 2 | uow.batches est le dépôt de lots (batches), donc l’UoW nous donne accès à notre stockage permanent.
|
| 3 | Quand nous avons terminé, nous validons (commit) ou annulons (roll back) notre travail, en utilisant l’UoW. |
L’UoW agit comme un point d’entrée unique vers notre stockage persistant, et il garde une trace des objets qui ont été chargés et de leur dernier état.[22]
Cela nous donne trois choses utiles :
-
Un instantané stable de la base de données sur lequel travailler, de sorte que les objets que nous utilisons ne changent pas à mi-chemin d’une opération
-
Un moyen de persister tous nos changements en une fois, donc si quelque chose se passe mal, nous ne nous retrouvons pas dans un état incohérent
-
Une API simple pour nos préoccupations de persistance et un endroit pratique pour obtenir un dépôt
6.2. Test-Driving d’une UoW avec des tests d’intégration
Voici nos tests d’intégration pour l’UoW :
def test_uow_can_retrieve_a_batch_and_allocate_to_it(session_factory):
session = session_factory()
insert_batch(session, "batch1", "HIPSTER-WORKBENCH", 100, None)
session.commit()
uow = unit_of_work.SqlAlchemyUnitOfWork(session_factory) (1)
with uow:
batch = uow.batches.get(reference="batch1") (2)
line = model.OrderLine("o1", "HIPSTER-WORKBENCH", 10)
batch.allocate(line)
uow.commit() (3)
batchref = get_allocated_batch_ref(session, "o1", "HIPSTER-WORKBENCH")
assert batchref == "batch1"| 1 | Nous initialisons l’UoW en utilisant notre fabrique de session personnalisée et obtenons un objet uow à utiliser dans notre bloc with. |
| 2 | L’UoW nous donne accès au dépôt de lots via uow.batches. |
| 3 | Nous appelons commit() dessus quand nous avons terminé. |
Pour les curieux, les assistants insert_batch et get_allocated_batch_ref ressemblent à ceci :
def insert_batch(session, ref, sku, qty, eta):
session.execute(
"INSERT INTO batches (reference, sku, _purchased_quantity, eta)"
" VALUES (:ref, :sku, :qty, :eta)",
dict(ref=ref, sku=sku, qty=qty, eta=eta),
)
def get_allocated_batch_ref(session, orderid, sku):
[[orderlineid]] = session.execute(
"SELECT id FROM order_lines WHERE orderid=:orderid AND sku=:sku",
dict(orderid=orderid, sku=sku),
)
[[batchref]] = session.execute(
"SELECT b.reference FROM allocations JOIN batches AS b ON batch_id = b.id"
" WHERE orderline_id=:orderlineid",
dict(orderlineid=orderlineid),
)
return batchref6.3. Unité de Travail et son Gestionnaire de Contexte
Dans nos tests, nous avons implicitement défini une interface pour ce qu’une UoW doit faire. Rendons cela explicite en utilisant une classe de base abstraite :
class AbstractUnitOfWork(abc.ABC):
batches: repository.AbstractRepository (1)
def __exit__(self, *args): (2)
self.rollback() (4)
@abc.abstractmethod
def commit(self): (3)
raise NotImplementedError
@abc.abstractmethod
def rollback(self): (4)
raise NotImplementedError| 1 | L’UoW fournit un attribut appelé .batches, qui nous donnera accès au dépôt de lots. |
| 2 | Si vous n’avez jamais vu de gestionnaire de contexte, __enter__ et __exit__ sont les deux méthodes magiques qui s’exécutent quand nous entrons dans le bloc with et quand nous en sortons, respectivement. Ce sont nos phases de configuration et de démontage.
|
| 3 | Nous appellerons cette méthode pour valider explicitement notre travail quand nous serons prêts. |
| 4 | Si nous ne validons pas (commit), ou si nous quittons le gestionnaire de contexte en levant une erreur, nous faisons une annulation (rollback). (L’annulation n’a aucun effet si commit() a été appelé. Lisez la suite pour plus de discussion à ce sujet.)
|
6.3.1. La véritable Unité de Travail utilise les Sessions SQLAlchemy
La principale chose que notre implémentation concrète ajoute est la session de base de données :
DEFAULT_SESSION_FACTORY = sessionmaker( (1)
bind=create_engine(
config.get_postgres_uri(),
)
)
class SqlAlchemyUnitOfWork(AbstractUnitOfWork):
def __init__(self, session_factory=DEFAULT_SESSION_FACTORY):
self.session_factory = session_factory (1)
def __enter__(self):
self.session = self.session_factory() # type: Session (2)
self.batches = repository.SqlAlchemyRepository(self.session) (2)
return super().__enter__()
def __exit__(self, *args):
super().__exit__(*args)
self.session.close() (3)
def commit(self): (4)
self.session.commit()
def rollback(self): (4)
self.session.rollback()| 1 | Le module définit une fabrique de session par défaut qui se connectera à Postgres, mais nous autorisons qu’elle soit remplacée dans nos tests d’intégration pour que nous puissions utiliser SQLite à la place. |
| 2 | La méthode __enter__ est responsable du démarrage d’une session de base de données et de l’instanciation d’un véritable dépôt qui peut utiliser cette session.
|
| 3 | Nous fermons la session à la sortie. |
| 4 | Enfin, nous fournissons des méthodes concrètes commit() et rollback() qui utilisent notre session de base de données.
|
6.3.2. Fausse Unité de Travail pour les tests
Voici comment nous utilisons une fausse UoW dans nos tests de couche de service :
class FakeUnitOfWork(unit_of_work.AbstractUnitOfWork):
def __init__(self):
self.batches = FakeRepository([]) (1)
self.committed = False (2)
def commit(self):
self.committed = True (2)
def rollback(self):
pass
def test_add_batch():
uow = FakeUnitOfWork() (3)
services.add_batch("b1", "CRUNCHY-ARMCHAIR", 100, None, uow) (3)
assert uow.batches.get("b1") is not None
assert uow.committed
def test_allocate_returns_allocation():
uow = FakeUnitOfWork() (3)
services.add_batch("batch1", "COMPLICATED-LAMP", 100, None, uow) (3)
result = services.allocate("o1", "COMPLICATED-LAMP", 10, uow) (3)
assert result == "batch1"
...| 1 | FakeUnitOfWork et FakeRepository sont étroitement couplés, tout comme les vraies classes UnitofWork et Repository. C’est bien parce que nous reconnaissons que les objets sont des collaborateurs. |
| 2 | Notez la similarité avec la fausse fonction commit() de FakeSession (dont nous pouvons maintenant nous débarrasser). Mais c’est une amélioration substantielle parce que nous simulons maintenant du code que nous avons écrit plutôt que du code tiers. Certaines personnes disent, "Ne simulez pas ce que vous ne possédez pas". |
| 3 | Dans nos tests, nous pouvons instancier une UoW et la passer à notre couche de service, plutôt que de passer un dépôt et une session. C’est considérablement moins encombrant. |
6.4. Utiliser l’UoW dans la Couche de Service
Voici à quoi ressemble notre nouvelle couche de service :
def add_batch(
ref: str, sku: str, qty: int, eta: Optional[date],
uow: unit_of_work.AbstractUnitOfWork, (1)
):
with uow:
uow.batches.add(model.Batch(ref, sku, qty, eta))
uow.commit()
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork, (1)
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
batches = uow.batches.list()
if not is_valid_sku(line.sku, batches):
raise InvalidSku(f"Invalid sku {line.sku}")
batchref = model.allocate(line, batches)
uow.commit()
return batchref| 1 | Notre couche de service n’a maintenant qu’une seule dépendance, encore une fois sur une UoW abstraite. |
6.5. Tests explicites pour le comportement Validation/Annulation
Pour nous convaincre que le comportement validation/annulation fonctionne, nous avons écrit quelques tests :
def test_rolls_back_uncommitted_work_by_default(session_factory):
uow = unit_of_work.SqlAlchemyUnitOfWork(session_factory)
with uow:
insert_batch(uow.session, "batch1", "MEDIUM-PLINTH", 100, None)
new_session = session_factory()
rows = list(new_session.execute('SELECT * FROM "batches"'))
assert rows == []
def test_rolls_back_on_error(session_factory):
class MyException(Exception):
pass
uow = unit_of_work.SqlAlchemyUnitOfWork(session_factory)
with pytest.raises(MyException):
with uow:
insert_batch(uow.session, "batch1", "LARGE-FORK", 100, None)
raise MyException()
new_session = session_factory()
rows = list(new_session.execute('SELECT * FROM "batches"'))
assert rows == []| Nous ne l’avons pas montré ici, mais il peut valoir la peine de tester certains des comportements de base de données les plus "obscurs", comme les transactions, contre la "vraie" base de données—c’est-à-dire, le même moteur. Pour l’instant, nous nous en sortons en utilisant SQLite au lieu de Postgres, mais dans Agrégats et Limites de Cohérence (Aggregates and Consistency Boundaries), nous changerons certains des tests pour utiliser la vraie base de données. Il est pratique que notre classe UoW rende cela facile ! |
6.6. Validations explicites versus implicites
Nous allons maintenant brièvement nous écarter sur différentes manières d’implémenter le motif UoW.
Nous pourrions imaginer une version légèrement différente de l’UoW qui valide par défaut et annule seulement s’il détecte une exception :
class AbstractUnitOfWork(abc.ABC):
def __enter__(self):
return self
def __exit__(self, exn_type, exn_value, traceback):
if exn_type is None:
self.commit() (1)
else:
self.rollback() (2)| 1 | Devrions-nous avoir une validation implicite dans le chemin heureux ? |
| 2 | Et annuler seulement en cas d’exception ? |
Cela nous permettrait d’économiser une ligne de code et de supprimer la validation explicite de notre code client :
def add_batch(ref: str, sku: str, qty: int, eta: Optional[date], uow):
with uow:
uow.batches.add(model.Batch(ref, sku, qty, eta))
# uow.commit()C’est un jugement à porter, mais nous avons tendance à préférer exiger la validation explicite afin de devoir choisir quand vider l’état.
Bien que nous utilisions une ligne de code supplémentaire, cela rend le logiciel sûr par défaut. Le comportement par défaut est de ne rien changer. À son tour, cela rend notre code plus facile à comprendre parce qu’il n’y a qu’un seul chemin de code qui mène à des changements dans le système : succès total et validation explicite. Tout autre chemin de code, toute exception, toute sortie anticipée de la portée de l’UoW mène à un état sûr.
De même, nous préférons annuler par défaut parce que c’est plus facile à comprendre ; cela annule jusqu’à la dernière validation, donc soit l’utilisateur en a fait une, soit nous effaçons ses changements. Dur mais simple.
6.7. Exemples : Utiliser l’UoW pour grouper plusieurs opérations en une unité atomique
Voici quelques exemples montrant le motif Unité de Travail en usage. Vous pouvez voir comment il mène à un raisonnement simple sur les blocs de code qui se produisent ensemble.
6.7.1. Exemple 1 : Réallouer
Supposons que nous voulions être capable de désallouer puis réallouer des commandes :
def reallocate(
line: OrderLine,
uow: AbstractUnitOfWork,
) -> str:
with uow:
batch = uow.batches.get(sku=line.sku)
if batch is None:
raise InvalidSku(f'Invalid sku {line.sku}')
batch.deallocate(line) (1)
allocate(line) (2)
uow.commit()| 1 | Si deallocate() échoue, nous ne voulons pas appeler allocate(), évidemment. |
| 2 | Si allocate() échoue, nous ne voulons probablement pas réellement valider la deallocate() non plus. |
6.7.2. Exemple 2 : Changer la quantité d’un lot
Notre compagnie de transport nous appelle pour dire que l’une des portes de conteneur s’est ouverte, et la moitié de nos canapés sont tombés dans l’océan Indien. Oups !
def change_batch_quantity(
batchref: str, new_qty: int,
uow: AbstractUnitOfWork,
):
with uow:
batch = uow.batches.get(reference=batchref)
batch.change_purchased_quantity(new_qty)
while batch.available_quantity < 0:
line = batch.deallocate_one() (1)
uow.commit()| 1 | Ici, nous pourrions avoir besoin de désallouer un nombre quelconque de lignes. Si nous obtenons un échec à n’importe quelle étape, nous voulons probablement valider aucun des changements. |
6.8. Nettoyer les tests d’intégration
Nous avons maintenant trois ensembles de tests, tous pointant essentiellement vers la base de données : test_orm.py, test_repository.py, et test_uow.py. Devrions-nous en jeter certains ?
└── tests
├── conftest.py
├── e2e
│ └── test_api.py
├── integration
│ ├── test_orm.py
│ ├── test_repository.py
│ └── test_uow.py
├── pytest.ini
└── unit
├── test_allocate.py
├── test_batches.py
└── test_services.pyVous devriez toujours vous sentir libre de jeter des tests si vous pensez qu’ils n’ajouteront pas de valeur à long terme. Nous dirions que test_orm.py était principalement un outil pour nous aider à apprendre SQLAlchemy, donc nous n’en aurons pas besoin à long terme, surtout si les principales choses qu’il fait sont couvertes dans test_repository.py. Ce dernier test, vous pourriez le garder, mais nous pourrions certainement voir un argument pour garder tout au plus haut niveau d’abstraction possible (tout comme nous l’avons fait pour les tests unitaires).
| C’est un autre exemple de la leçon de TDD en Vitesse Supérieure et en Vitesse Inférieure : au fur et à mesure que nous construisons de meilleures abstractions, nous pouvons déplacer nos tests pour s’exécuter contre elles, ce qui nous laisse libres de changer les détails sous-jacents. |
6.9. Récapitulatif
Nous espérons vous avoir convaincu que le motif Unité de Travail est utile, et que le gestionnaire de contexte est une manière vraiment agréable et pythonique de grouper visuellement le code en blocs que nous voulons se produire atomiquement.
Ce motif est si utile, en fait, que SQLAlchemy utilise déjà une UoW sous la forme de l’objet Session. L’objet Session dans SQLAlchemy est la façon dont votre application charge des données de la base de données.
Chaque fois que vous chargez une nouvelle entité de la base de données, la session commence à suivre les changements à l’entité, et quand la session est vidée (flushed), tous vos changements sont persistés ensemble. Pourquoi nous donnons-nous la peine d’abstraire la session SQLAlchemy si elle implémente déjà le motif que nous voulons ?
Motif Unité de Travail : les compromis discute de certains des compromis.
| Pour | Contre |
|---|---|
|
|
Pour une chose, l’API Session est riche et supporte des opérations que nous ne voulons pas ou n’avons pas besoin dans notre domaine. Notre UnitOfWork simplifie la session à son noyau essentiel : elle peut être démarrée, validée ou jetée.
Pour une autre, nous utilisons l'`UnitOfWork` pour accéder à nos objets Repository. C’est un bel aspect d’utilisabilité pour le développeur que nous ne pourrions pas faire avec une simple Session SQLAlchemy.
Enfin, nous sommes à nouveau motivés par le principe d’inversion de dépendance : notre couche de service dépend d’une abstraction mince, et nous attachons une implémentation concrète au bord externe du système. Cela s’aligne bien avec les propres recommandations de SQLAlchemy :
Gardez le cycle de vie de la session (et généralement la transaction) séparé et externe. L’approche la plus complète, recommandée pour les applications plus substantielles, essaiera de garder les détails de la session, de la transaction et de la gestion des exceptions aussi loin que possible des détails du programme faisant son travail.
7. Agrégats et Limites de Cohérence (Aggregates and Consistency Boundaries)
Dans ce chapitre, nous aimerions revisiter notre modèle de domaine pour parler d’invariants et de contraintes, et voir comment nos objets de domaine peuvent maintenir leur propre cohérence interne, à la fois conceptuellement et dans le stockage persistant. Nous discuterons du concept de limite de cohérence (consistency boundary) et montrerons comment le rendre explicite peut nous aider à construire des logiciels performants sans compromettre la maintenabilité.
Ajout de l’agrégat Product montre un aperçu de notre destination : nous introduirons un nouvel objet modèle appelé Product pour envelopper plusieurs lots (batches), et nous rendrons l’ancien service de domaine allocate() disponible comme une méthode sur Product à la place.
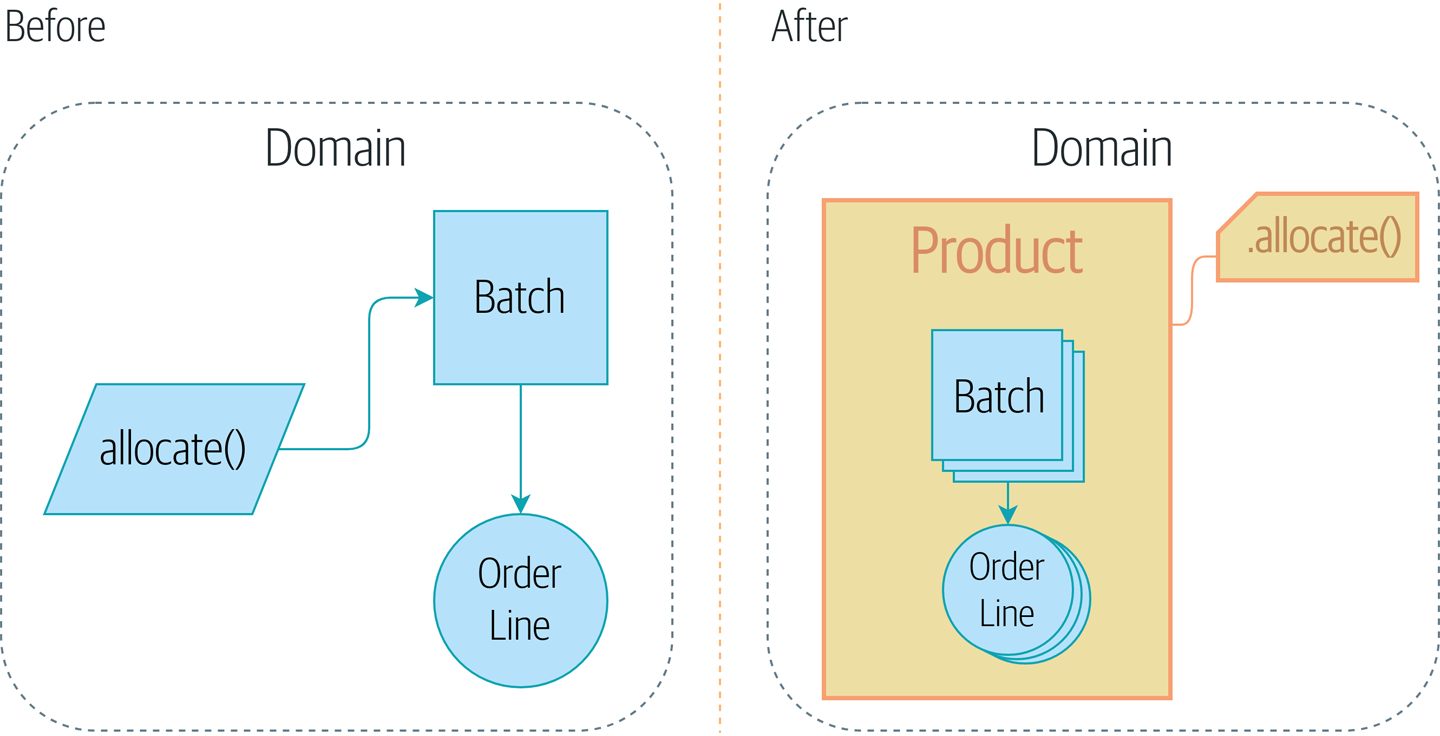
Pourquoi ? Découvrons-le.
|
Le code pour ce chapitre se trouve dans la branche chapter_07_aggregate sur GitHub : git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_07_aggregate # ou pour coder en même temps, récupérez le chapitre précédent : git checkout chapter_06_uow |
7.1. Pourquoi ne pas tout exécuter dans une feuille de calcul ?
Quel est l’intérêt d’un modèle de domaine, de toute façon ? Quel est le problème fondamental que nous essayons de résoudre ?
Ne pourrions-nous pas tout exécuter dans une feuille de calcul ? Beaucoup de nos utilisateurs seraient ravis de cela. Les utilisateurs métier aiment les feuilles de calcul parce qu’elles sont simples, familières et pourtant extrêmement puissantes.
En fait, un nombre énorme de processus métier fonctionnent en envoyant manuellement des feuilles de calcul par email. Cette architecture "CSV sur SMTP" a une faible complexité initiale mais tend à ne pas très bien s’adapter car il est difficile d’appliquer la logique et de maintenir la cohérence.
Qui est autorisé à voir ce champ particulier ? Qui est autorisé à le mettre à jour ? Que se passe-t-il quand nous essayons de commander –350 chaises, ou 10 000 000 de tables ? Un employé peut-il avoir un salaire négatif ?
Ce sont les contraintes d’un système. Une grande partie de la logique de domaine que nous écrivons existe pour faire respecter ces contraintes afin de maintenir les invariants du système. Les invariants sont les choses qui doivent être vraies chaque fois que nous finissons une opération.
7.2. Invariants, contraintes et cohérence
Les deux mots sont quelque peu interchangeables, mais une contrainte est une règle qui restreint les états possibles dans lesquels notre modèle peut se trouver, tandis qu’un invariant est défini un peu plus précisément comme une condition qui est toujours vraie.
Si nous écrivions un système de réservation d’hôtel, nous pourrions avoir la contrainte que les doubles réservations ne sont pas autorisées. Cela soutient l’invariant qu’une chambre ne peut pas avoir plus d’une réservation pour la même nuit.
Bien sûr, parfois nous pourrions avoir besoin de plier temporairement les règles. Peut-être devons-nous réorganiser les chambres en raison d’une réservation VIP. Pendant que nous déplaçons les réservations en mémoire, nous pourrions être doublement réservés, mais notre modèle de domaine devrait s’assurer que, quand nous avons terminé, nous nous retrouvons dans un état final cohérent, où les invariants sont respectés. Si nous ne trouvons pas de moyen d’accueillir tous nos invités, nous devrions lever une erreur et refuser de terminer l’opération.
Examinons quelques exemples concrets de nos exigences métier ; nous commencerons par celui-ci :
Une ligne de commande ne peut être allouée qu’à un seul lot à la fois.
C’est une règle métier qui impose un invariant. L’invariant est qu’une ligne de commande est allouée soit à zéro soit à un lot, mais jamais plus d’un. Nous devons nous assurer que notre code n’appelle jamais accidentellement Batch.allocate() sur deux lots différents pour la même ligne, et actuellement, il n’y a rien là pour nous empêcher explicitement de faire cela.
7.2.1. Invariants, concurrence et verrous
Examinons une autre de nos règles métier :
Nous ne pouvons pas allouer à un lot si la quantité disponible est inférieure à la quantité de la ligne de commande.
Ici, la contrainte est que nous ne pouvons pas allouer plus de stock que ce qui est disponible à un lot, donc nous ne sursoldons jamais le stock en allouant deux clients au même coussin physique, par exemple. Chaque fois que nous mettons à jour l’état du système, notre code doit s’assurer que nous ne brisons pas l’invariant, qui est que la quantité disponible doit être supérieure ou égale à zéro.
Dans une application monothread, mono-utilisateur, il est relativement facile pour nous de maintenir cet invariant. Nous pouvons simplement allouer le stock une ligne à la fois, et lever une erreur s’il n’y a pas de stock disponible.
Cela devient beaucoup plus difficile quand nous introduisons l’idée de concurrence. Soudainement, nous pourrions allouer du stock pour plusieurs lignes de commande simultanément. Nous pourrions même allouer des lignes de commande en même temps que nous traitons des changements aux lots eux-mêmes.
Nous résolvons généralement ce problème en appliquant des verrous à nos tables de base de données. Cela empêche deux opérations de se produire simultanément sur la même ligne ou la même table.
Au fur et à mesure que nous commençons à penser à l’agrandissement de notre application, nous réalisons que notre modèle d’allocation de lignes contre tous les lots disponibles pourrait ne pas passer à l’échelle. Si nous traitons des dizaines de milliers de commandes par heure, et des centaines de milliers de lignes de commande, nous ne pouvons pas tenir un verrou sur toute la table batches pour chacune—nous obtiendrons des interblocages ou des problèmes de performance au minimum.
7.3. Qu’est-ce qu’un Agrégat ?
OK, donc si nous ne pouvons pas verrouiller toute la base de données chaque fois que nous voulons allouer une ligne de commande, que devrions-nous faire à la place ? Nous voulons protéger les invariants de notre système mais permettre le plus grand degré de concurrence. Maintenir nos invariants signifie inévitablement empêcher les écritures concurrentes ; si plusieurs utilisateurs peuvent allouer DEADLY-SPOON en même temps, nous courons le risque de surallouer.
D’autre part, il n’y a aucune raison pour que nous ne puissions pas allouer DEADLY-SPOON en même temps que FLIMSY-DESK. Il est sûr d’allouer deux produits en même temps parce qu’il n’y a pas d’invariant qui les couvre tous les deux. Nous n’avons pas besoin qu’ils soient cohérents l’un avec l’autre.
Le motif Agrégat (Aggregate) est un motif de conception de la communauté DDD qui nous aide à résoudre cette tension. Un agrégat est juste un objet de domaine qui contient d’autres objets de domaine et nous permet de traiter toute la collection comme une seule unité.
La seule façon de modifier les objets à l’intérieur de l’agrégat est de charger la chose entière, et d’appeler des méthodes sur l’agrégat lui-même.
Au fur et à mesure qu’un modèle devient plus complexe et développe plus d’entités et d’objets valeur, se référençant les uns aux autres dans un graphe enchevêtré, il peut être difficile de garder une trace de qui peut modifier quoi. Surtout quand nous avons des collections dans le modèle comme nous le faisons (nos lots sont une collection), c’est une bonne idée de nommer certaines entités pour être le point d’entrée unique pour modifier leurs objets liés. Cela rend le système conceptuellement plus simple et facile à raisonner si vous nommez certains objets pour être en charge de la cohérence pour les autres.
Par exemple, si nous construisons un site d’achat, le Panier (Cart) pourrait faire un bon agrégat : c’est une collection d’articles que nous pouvons traiter comme une seule unité. Surtout, nous voulons charger le panier entier comme un seul blob de notre magasin de données. Nous ne voulons pas que deux requêtes modifient le panier en même temps, sinon nous courons le risque d’erreurs de concurrence bizarres. Au lieu de cela, nous voulons que chaque changement au panier s’exécute dans une seule transaction de base de données.
Nous ne voulons pas modifier plusieurs paniers dans une transaction, parce qu’il n’y a pas de cas d’usage pour changer les paniers de plusieurs clients en même temps. Chaque panier est une seule limite de cohérence (consistency boundary) responsable du maintien de ses propres invariants.
Un AGRÉGAT est un groupe d’objets associés que nous traitons comme une unité pour les changements de données.
Domain-Driven Design blue book
Selon Evans, notre agrégat a une entité racine (le Panier) qui encapsule l’accès aux articles. Chaque article a sa propre identité, mais d’autres parties du système feront toujours référence au Panier uniquement comme un tout indivisible.
Tout comme nous utilisons parfois des _underscores_de_début pour marquer les méthodes ou fonctions comme "privées", vous pouvez penser aux agrégats comme étant les classes "publiques" de notre modèle, et le reste des entités et objets valeur comme "privés".
|
7.4. Choisir un Agrégat
Quel agrégat devrions-nous utiliser pour notre système ? Le choix est quelque peu arbitraire, mais il est important. L’agrégat sera la limite où nous nous assurons que chaque opération se termine dans un état cohérent. Cela nous aide à raisonner sur notre logiciel et à prévenir les problèmes de course bizarres. Nous voulons tracer une limite autour d’un petit nombre d’objets—le plus petit, le mieux, pour la performance—qui doivent être cohérents les uns avec les autres, et nous devons donner à cette limite un bon nom.
L’objet que nous manipulons sous le capot est Batch. Comment appelons-nous une collection de lots ? Comment devrions-nous diviser tous les lots du système en îlots discrets de cohérence ?
Nous pourrions utiliser Shipment comme notre limite. Chaque expédition contient plusieurs lots, et ils voyagent tous vers notre entrepôt en même temps. Ou peut-être pourrions-nous utiliser Warehouse comme notre limite : chaque entrepôt contient de nombreux lots, et compter tout le stock en même temps pourrait avoir du sens.
Aucun de ces concepts ne nous satisfait vraiment, cependant. Nous devrions être capables d’allouer des DEADLY-SPOON ou des FLIMSY-DESK en une seule fois, même s’ils ne sont pas dans le même entrepôt ou la même expédition. Ces concepts ont la mauvaise granularité.
Quand nous allouons une ligne de commande, nous nous intéressons uniquement aux lots qui ont le même SKU que la ligne de commande. Une sorte de concept comme GlobalSkuStock pourrait fonctionner : une collection de tous les lots pour un SKU donné.
C’est un nom encombrant, cependant, donc après quelques discussions via SkuStock, Stock, ProductStock, etc., nous avons décidé de l’appeler simplement Product—après tout, c’était le premier concept que nous avons rencontré dans notre exploration du langage du domaine dans Modélisation du Domaine.
Donc le plan est le suivant : quand nous voulons allouer une ligne de commande, au lieu de Avant : allouer contre tous les lots en utilisant le service de domaine, où nous recherchons tous les objets Batch dans le monde et les passons au service de domaine allocate()…
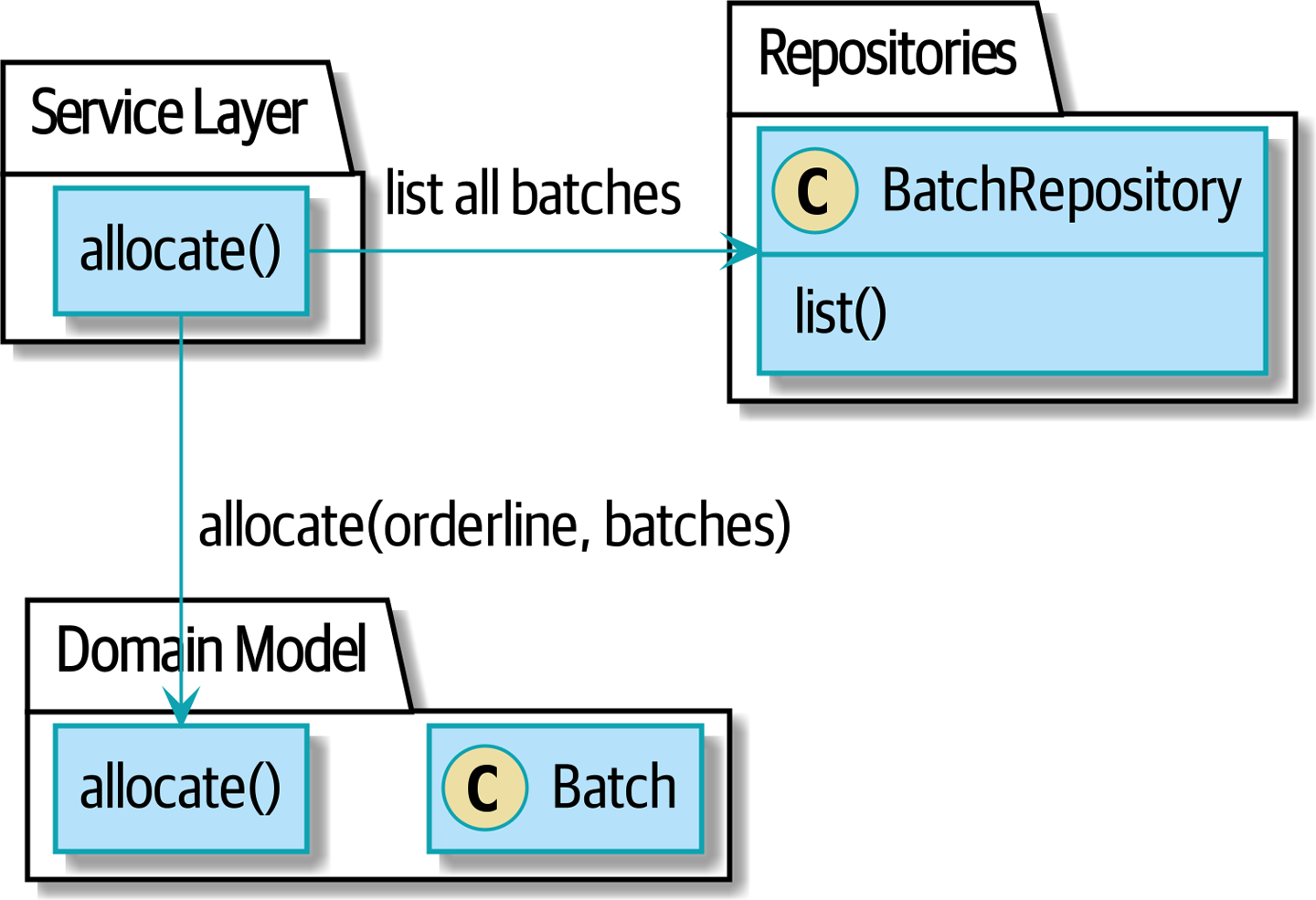
[plantuml, apwp_0702, config=plantuml.cfg]
@startuml
scale 4
hide empty members
package "Service Layer" as services {
class "allocate()" as allocate {
}
hide allocate circle
hide allocate members
}
package "Domain Model" as domain_model {
class Batch {
}
class "allocate()" as allocate_domain_service {
}
hide allocate_domain_service circle
hide allocate_domain_service members
}
package Repositories {
class BatchRepository {
list()
}
}
allocate -> BatchRepository: list all batches
allocate --> allocate_domain_service: allocate(orderline, batches)
@enduml
…nous passerons au monde de Après : demander à Product d’allouer contre ses lots, dans lequel il y a un nouvel objet Product pour le SKU particulier de notre ligne de commande, et il sera en charge de tous les lots pour ce SKU, et nous pouvons appeler une méthode .allocate() dessus à la place.
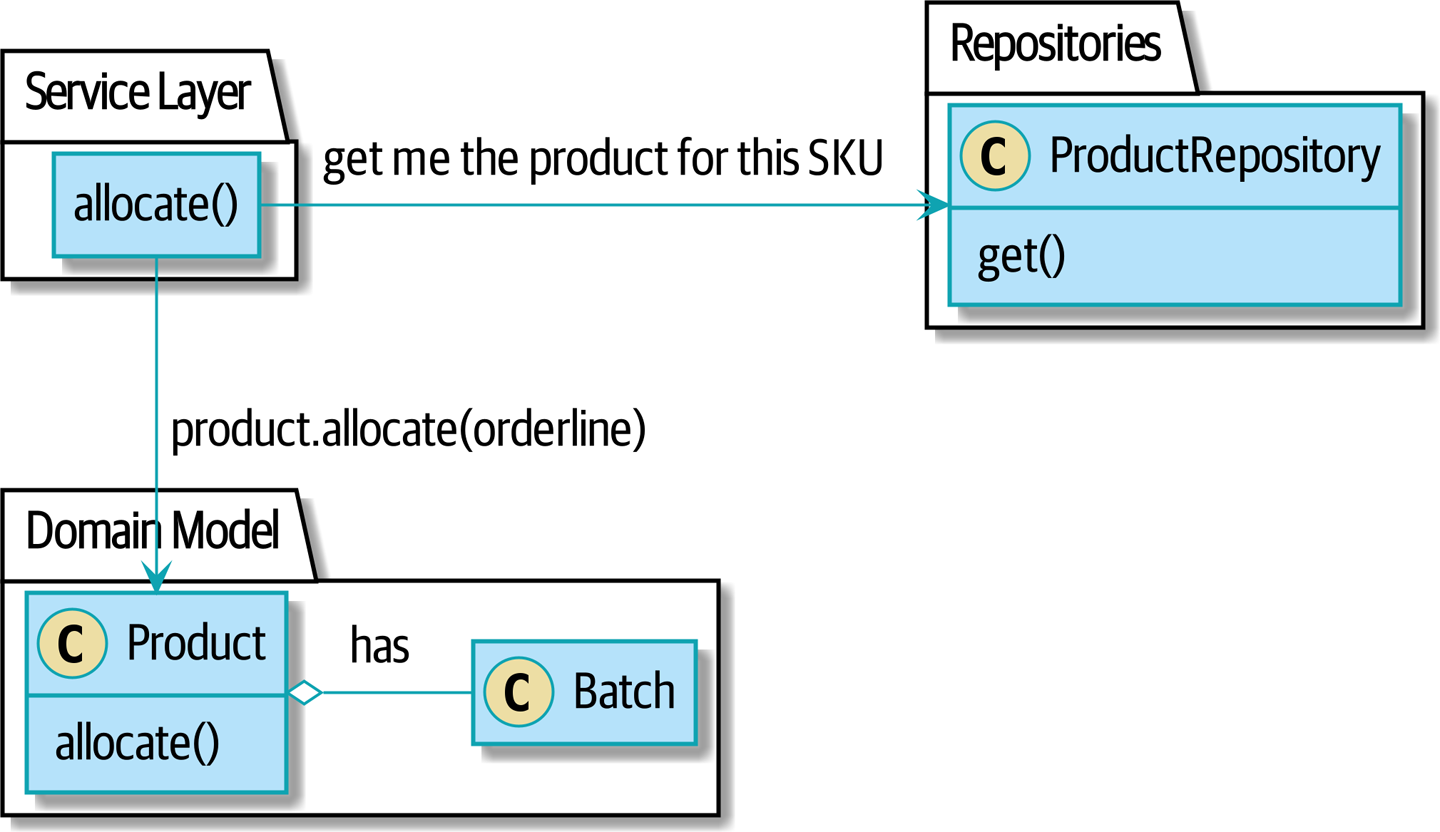
[plantuml, apwp_0703, config=plantuml.cfg]
@startuml
scale 4
hide empty members
package "Service Layer" as services {
class "allocate()" as allocate {
}
}
hide allocate circle
hide allocate members
package "Domain Model" as domain_model {
class Product {
allocate()
}
class Batch {
}
}
package Repositories {
class ProductRepository {
get()
}
}
allocate -> ProductRepository: get me the product for this SKU
allocate --> Product: product.allocate(orderline)
Product o- Batch: has
@enduml
Voyons à quoi cela ressemble sous forme de code :
class Product:
def __init__(self, sku: str, batches: List[Batch]):
self.sku = sku (1)
self.batches = batches (2)
def allocate(self, line: OrderLine) -> str: (3)
try:
batch = next(b for b in sorted(self.batches) if b.can_allocate(line))
batch.allocate(line)
return batch.reference
except StopIteration:
raise OutOfStock(f"Out of stock for sku {line.sku}")| 1 | L’identifiant principal de Product est le sku. |
| 2 | Notre classe Product détient une référence à une collection de batches pour ce SKU.
|
| 3 | Enfin, nous pouvons déplacer le service de domaine allocate() pour être une méthode sur l’agrégat Product. |
Ce Product ne ressemble peut-être pas à ce à quoi vous vous attendriez qu’un modèle Product ressemble. Pas de prix, pas de description, pas de dimensions. Notre service d’allocation ne se soucie d’aucune de ces choses. C’est la puissance des contextes bornés ; le concept d’un produit dans une application peut être très différent d’une autre. Voir l’encadré suivant pour plus de discussion.
|
7.5. Un Agrégat = Un Dépôt
Une fois que vous définissez certaines entités comme étant des agrégats, nous devons appliquer la règle qu’ils sont les seules entités qui sont publiquement accessibles au monde extérieur. En d’autres termes, les seuls dépôts que nous sommes autorisés à avoir devraient être des dépôts qui retournent des agrégats.
| La règle que les dépôts ne devraient retourner que des agrégats est le principal endroit où nous appliquons la convention que les agrégats sont la seule voie d’entrée dans notre modèle de domaine. Méfiez-vous de la briser ! |
Dans notre cas, nous passerons de BatchRepository à ProductRepository :
class AbstractUnitOfWork(abc.ABC):
products: repository.AbstractProductRepository
...
class AbstractProductRepository(abc.ABC):
@abc.abstractmethod
def add(self, product):
...
@abc.abstractmethod
def get(self, sku) -> model.Product:
...
La couche ORM aura besoin de quelques ajustements pour que les bons lots soient automatiquement chargés et associés aux objets Product. La bonne chose est que le motif Dépôt signifie que nous n’avons pas à nous inquiéter de cela encore. Nous pouvons juste utiliser notre FakeRepository et ensuite alimenter le nouveau modèle dans notre couche de service pour voir à quoi il ressemble avec Product comme point d’entrée principal :
def add_batch(
ref: str, sku: str, qty: int, eta: Optional[date],
uow: unit_of_work.AbstractUnitOfWork,
):
with uow:
product = uow.products.get(sku=sku)
if product is None:
product = model.Product(sku, batches=[])
uow.products.add(product)
product.batches.append(model.Batch(ref, sku, qty, eta))
uow.commit()
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork,
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
product = uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f"Invalid sku {line.sku}")
batchref = product.allocate(line)
uow.commit()
return batchref7.6. Qu’en est-il de la performance ?
Nous avons mentionné plusieurs fois que nous modélisons avec des agrégats parce que nous voulons avoir un logiciel performant, mais ici nous chargeons tous les lots quand nous n’en avons besoin que d’un. Vous pourriez vous attendre à ce que ce soit inefficace, mais il y a quelques raisons pour lesquelles nous sommes à l’aise ici.
D’abord, nous modélisons délibérément nos données de sorte que nous puissions faire une seule requête à la base de données pour lire, et une seule mise à jour pour persister nos changements. Cela tend à avoir de bien meilleures performances que les systèmes qui émettent beaucoup de requêtes ad hoc. Dans les systèmes qui ne modélisent pas de cette façon, nous trouvons souvent que les transactions deviennent lentement plus longues et plus complexes au fur et à mesure que le logiciel évolue.
Deuxièmement, nos structures de données sont minimales et comprennent quelques chaînes et entiers par ligne. Nous pouvons facilement charger des dizaines ou même des centaines de lots en quelques millisecondes.
Troisièmement, nous nous attendons à n’avoir qu’environ 20 lots de chaque produit à la fois. Une fois qu’un lot est épuisé, nous pouvons l’exclure de nos calculs. Cela signifie que la quantité de données que nous récupérons ne devrait pas devenir incontrôlable au fil du temps.
Si nous nous attendions à avoir des milliers de lots actifs pour un produit, nous aurions quelques options. D’une part, nous pourrions utiliser le chargement paresseux pour les lots dans un produit. Du point de vue de notre code, rien ne changerait, mais en arrière-plan, SQLAlchemy paginerait les données pour nous. Cela mènerait à plus de requêtes, chacune récupérant un plus petit nombre de lignes. Parce que nous devons trouver seulement un seul lot avec suffisamment de capacité pour notre commande, cela pourrait fonctionner assez bien.
Si tout le reste échouait, nous chercherions simplement un agrégat différent. Peut-être pourrions-nous diviser les lots par région ou par entrepôt. Peut-être pourrions-nous reconcevoir notre stratégie d’accès aux données autour du concept d’expédition. Le motif Agrégat est conçu pour aider à gérer certaines contraintes techniques autour de la cohérence et de la performance. Il n’y a pas un agrégat correct, et nous devrions nous sentir à l’aise de changer d’avis si nous constatons que nos limites causent des problèmes de performance.
7.7. Concurrence optimiste avec numéros de version
Nous avons notre nouvel agrégat, donc nous avons résolu le problème conceptuel du choix d’un objet pour être en charge des limites de cohérence. Passons maintenant un peu de temps à parler de la façon d’appliquer l’intégrité des données au niveau de la base de données.
| Cette section a beaucoup de détails d’implémentation ; par exemple, certains sont spécifiques à Postgres. Mais plus généralement, nous montrons une façon de gérer les problèmes de concurrence, mais c’est juste une approche. Les exigences réelles dans ce domaine varient beaucoup d’un projet à l’autre. Vous ne devriez pas vous attendre à pouvoir copier et coller le code d’ici en production. |
Nous ne voulons pas tenir un verrou sur toute la table batches, mais comment allons-nous implémenter le maintien d’un verrou uniquement sur les lignes pour un SKU particulier ?
Une réponse est d’avoir un seul attribut sur le modèle Product qui agit comme un marqueur pour que tout le changement d’état soit complet et de l’utiliser comme la ressource unique sur laquelle les travailleurs concurrents peuvent se battre. Si deux transactions lisent l’état du monde pour batches en même temps, et les deux veulent mettre à jour la table allocations, nous forçons les deux à également essayer de mettre à jour le version_number dans la table products, de telle manière qu’un seul d’entre eux puisse gagner et que le monde reste cohérent.
Diagramme de séquence : deux transactions tentant une mise à jour concurrente sur Product illustre deux transactions concurrentes faisant leurs opérations de lecture en même temps, donc elles voient un Product avec, par exemple, version=3. Elles appellent toutes les deux Product.allocate() afin de modifier un état. Mais nous configurons nos règles d’intégrité de base de données de telle sorte qu’un seul d’entre eux est autorisé à commit le nouveau Product avec version=4, et l’autre mise à jour est rejetée.
Les numéros de version ne sont qu’une façon d’implémenter le verrouillage optimiste. Vous pourriez obtenir la même chose en définissant le niveau d’isolation des transactions Postgres à SERIALIZABLE, mais cela vient souvent avec un coût de performance sévère. Les numéros de version rendent également les concepts implicites explicites.
|
Product[plantuml, apwp_0704, config=plantuml.cfg] @startuml scale 4 entity Model collections Transaction1 collections Transaction2 database Database Transaction1 -> Database: get product Database -> Transaction1: Product(version=3) Transaction2 -> Database: get product Database -> Transaction2: Product(version=3) Transaction1 -> Model: Product.allocate() Model -> Transaction1: Product(version=4) Transaction2 -> Model: Product.allocate() Model -> Transaction2: Product(version=4) Transaction1 -> Database: commit Product(version=4) Database -[#green]> Transaction1: OK Transaction2 -> Database: commit Product(version=4) Database -[#red]>x Transaction2: Error! version is already 4 @enduml
7.7.1. Options d’implémentation pour les numéros de version
Il y a essentiellement trois options pour implémenter les numéros de version :
-
version_numbervit dans le domaine ; nous l’ajoutons au constructeurProduct, etProduct.allocate()est responsable de l’incrémenter. -
La couche de service pourrait le faire ! Le numéro de version n’est pas strictement une préoccupation de domaine, donc à la place notre couche de service pourrait supposer que le numéro de version actuel est attaché à
Productpar le dépôt, et la couche de service l’incrémentera avant de faire lecommit(). -
Puisque c’est sans doute une préoccupation d’infrastructure, l’UoW et le dépôt pourraient le faire par magie. Le dépôt a accès aux numéros de version pour tous les produits qu’il récupère, et quand l’UoW fait un commit, il peut incrémenter le numéro de version pour tous les produits qu’il connaît, en supposant qu’ils aient changé.
L’option 3 n’est pas idéale, parce qu’il n’y a pas de vraie façon de le faire sans devoir supposer que tous les produits ont changé, donc nous incrémenterons les numéros de version quand nous n’avons pas à le faire.[23]
L’option 2 implique de mélanger la responsabilité de muter l’état entre la couche de service et la couche de domaine, donc c’est un peu désordonné aussi.
Donc à la fin, même si les numéros de version ne doivent pas être une préoccupation de domaine, vous pourriez décider que le compromis le plus propre est de les mettre dans le domaine :
class Product:
def __init__(self, sku: str, batches: List[Batch], version_number: int = 0): (1)
self.sku = sku
self.batches = batches
self.version_number = version_number (1)
def allocate(self, line: OrderLine) -> str:
try:
batch = next(b for b in sorted(self.batches) if b.can_allocate(line))
batch.allocate(line)
self.version_number += 1 (1)
return batch.reference
except StopIteration:
raise OutOfStock(f"Out of stock for sku {line.sku}")| 1 | Le voilà ! |
Si vous vous grattez la tête à propos de ce business de numéro de version, il pourrait être utile de se rappeler que le numéro n’est pas important. Ce qui est important est que la ligne de base de données Product soit modifiée chaque fois que nous apportons un changement à l’agrégat Product. Le numéro de version est un moyen simple et compréhensible par l’humain de modéliser une chose qui change à chaque écriture, mais cela pourrait tout aussi bien être un UUID aléatoire à chaque fois.
|
7.8. Tester nos règles d’intégrité des données
Maintenant pour s’assurer que nous pouvons obtenir le comportement que nous voulons : si nous avons deux tentatives concurrentes de faire une allocation contre le même Product, l’une d’elles devrait échouer, parce qu’elles ne peuvent pas toutes les deux mettre à jour le numéro de version.
D’abord, simulons une transaction "lente" en utilisant une fonction qui fait une allocation puis fait un sleep explicite :[24]
def try_to_allocate(orderid, sku, exceptions):
line = model.OrderLine(orderid, sku, 10)
try:
with unit_of_work.SqlAlchemyUnitOfWork() as uow:
product = uow.products.get(sku=sku)
product.allocate(line)
time.sleep(0.2)
uow.commit()
except Exception as e:
print(traceback.format_exc())
exceptions.append(e)Ensuite, nous avons notre test qui invoque cette allocation lente deux fois, de manière concurrente, en utilisant des threads :
def test_concurrent_updates_to_version_are_not_allowed(postgres_session_factory):
sku, batch = random_sku(), random_batchref()
session = postgres_session_factory()
insert_batch(session, batch, sku, 100, eta=None, product_version=1)
session.commit()
order1, order2 = random_orderid(1), random_orderid(2)
exceptions = [] # type: List[Exception]
try_to_allocate_order1 = lambda: try_to_allocate(order1, sku, exceptions)
try_to_allocate_order2 = lambda: try_to_allocate(order2, sku, exceptions)
thread1 = threading.Thread(target=try_to_allocate_order1) (1)
thread2 = threading.Thread(target=try_to_allocate_order2) (1)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
[[version]] = session.execute(
"SELECT version_number FROM products WHERE sku=:sku",
dict(sku=sku),
)
assert version == 2 (2)
[exception] = exceptions
assert "could not serialize access due to concurrent update" in str(exception) (3)
orders = session.execute(
"SELECT orderid FROM allocations"
" JOIN batches ON allocations.batch_id = batches.id"
" JOIN order_lines ON allocations.orderline_id = order_lines.id"
" WHERE order_lines.sku=:sku",
dict(sku=sku),
)
assert orders.rowcount == 1 (4)
with unit_of_work.SqlAlchemyUnitOfWork() as uow:
uow.session.execute("select 1")| 1 | Nous démarrons deux threads qui produiront de manière fiable le comportement de concurrence que nous voulons : read1, read2, write1, write2. |
| 2 | Nous affirmons que le numéro de version n’a été incrémenté qu’une seule fois. |
| 3 | Nous pouvons aussi vérifier l’exception spécifique si nous le souhaitons. |
| 4 | Et nous vérifions doublement qu’une seule allocation est passée. |
7.8.1. Faire respecter les règles de concurrence en utilisant les niveaux d’isolation des transactions de base de données
Pour que le test passe tel quel, nous pouvons définir le niveau d’isolation des transactions sur notre session :
DEFAULT_SESSION_FACTORY = sessionmaker(
bind=create_engine(
config.get_postgres_uri(),
isolation_level="REPEATABLE READ",
)
)| Les niveaux d’isolation des transactions sont des choses délicates, donc il vaut la peine de passer du temps à comprendre la documentation Postgres.[25] |
7.8.2. Exemple de contrôle de concurrence pessimiste : SELECT FOR UPDATE
Il y a plusieurs façons d’aborder cela, mais nous en montrerons une. SELECT FOR UPDATE produit un comportement différent ; deux transactions concurrentes ne seront pas autorisées à faire une lecture sur les mêmes lignes en même temps :
SELECT FOR UPDATE est une façon de choisir une ligne ou des lignes à utiliser comme verrou (bien que ces lignes ne doivent pas être celles que vous mettez à jour). Si deux transactions essaient toutes les deux de SELECT FOR UPDATE une ligne en même temps, l’une gagnera, et l’autre attendra jusqu’à ce que le verrou soit libéré. C’est donc un exemple de contrôle de concurrence pessimiste.
Voici comment vous pouvez utiliser le DSL SQLAlchemy pour spécifier FOR UPDATE au moment de la requête :
def get(self, sku):
return (
self.session.query(model.Product)
.filter_by(sku=sku)
.with_for_update()
.first()
)Cela aura pour effet de changer le modèle de concurrence de
read1, read2, write1, write2(fail)
à
read1, write1, read2, write2(succeed)
Certaines personnes font référence à cela comme le mode d’échec "read-modify-write". Lisez "PostgreSQL Anti-Patterns: Read-Modify-Write Cycles" pour un bon aperçu.
Nous n’avons vraiment pas le temps de discuter de tous les compromis entre REPEATABLE READ et SELECT FOR UPDATE, ou le verrouillage optimiste versus pessimiste en général. Mais si vous avez un test comme celui que nous avons montré, vous pouvez spécifier le comportement que vous voulez et voir comment il change. Vous pouvez aussi utiliser le test comme base pour effectuer quelques expériences de performance.
7.9. Récapitulatif
Les choix spécifiques autour du contrôle de concurrence varient beaucoup selon les circonstances métier et les choix de technologie de stockage, mais nous aimerions ramener ce chapitre à l’idée conceptuelle d’un agrégat : nous modélisons explicitement un objet comme étant le point d’entrée principal vers un sous-ensemble de notre modèle, et comme étant en charge de faire respecter les invariants et les règles métier qui s’appliquent à tous ces objets.
Choisir le bon agrégat est clé, et c’est une décision que vous pourriez revisiter au fil du temps. Vous pouvez en lire plus à ce sujet dans plusieurs livres DDD. Nous recommandons aussi ces trois articles en ligne sur la conception d’agrégats efficaces par Vaughn Vernon (l’auteur du "livre rouge").
Agrégats : les compromis a quelques réflexions sur les compromis de l’implémentation du motif Agrégat.
| Pour | Contre |
|---|---|
|
|
7.10. Récapitulatif de la Partie I
Vous souvenez-vous de Un diagramme de composants pour notre application à la fin de la Partie I, le diagramme que nous avons montré au début de Construire une Architecture pour Supporter la Modélisation de Domaine pour prévisualiser où nous allions ?
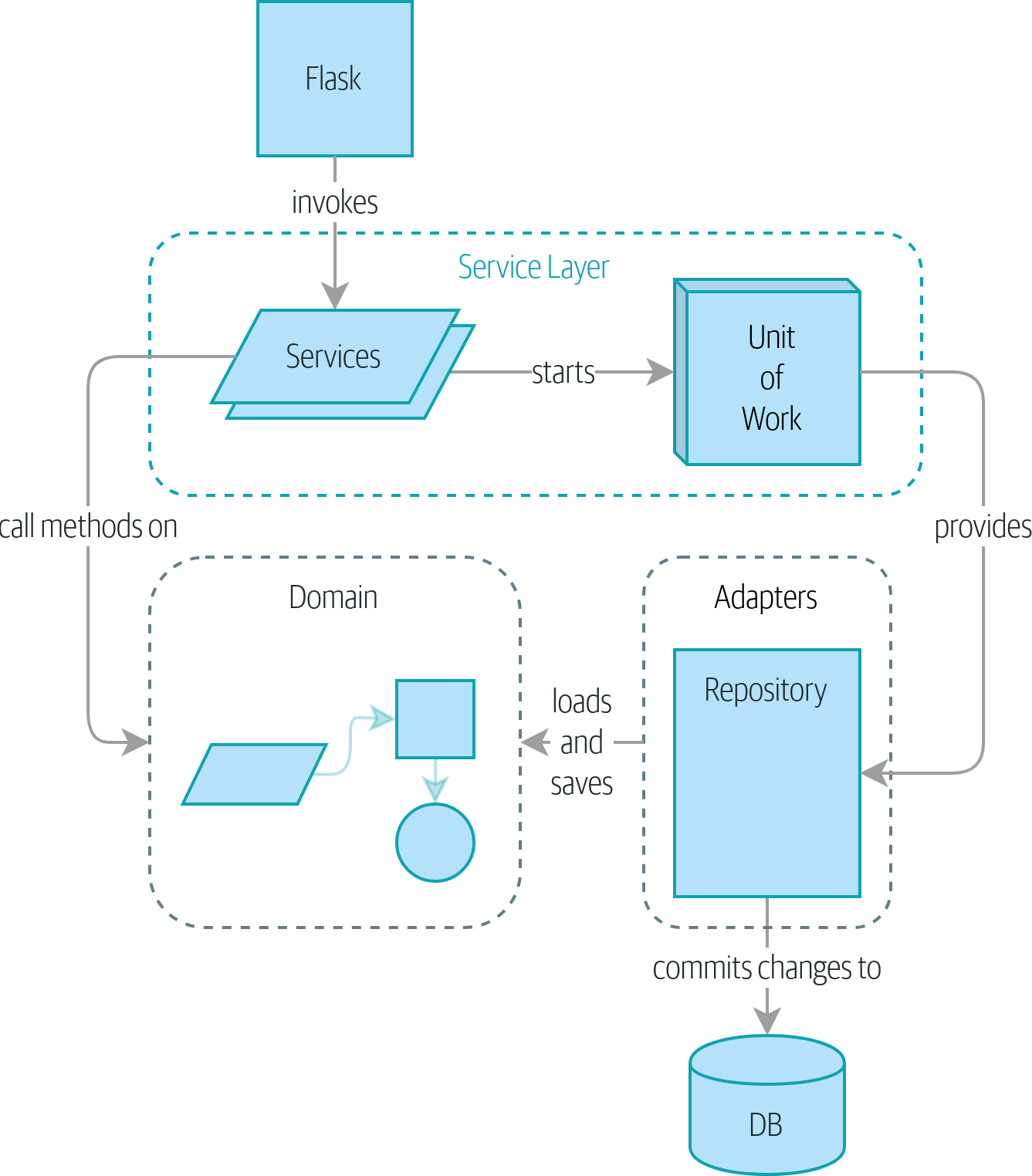
Donc c’est où nous en sommes à la fin de la Partie I. Qu’avons-nous accompli ? Nous avons vu comment construire un modèle de domaine qui est exercé par un ensemble de tests unitaires de haut niveau. Nos tests sont une documentation vivante : ils décrivent le comportement de notre système—les règles sur lesquelles nous nous sommes mis d’accord avec nos parties prenantes métier—dans un code agréable et lisible. Quand nos exigences métier changent, nous avons confiance que nos tests nous aideront à prouver la nouvelle fonctionnalité, et quand de nouveaux développeurs rejoignent le projet, ils peuvent lire nos tests pour comprendre comment les choses fonctionnent.
Nous avons découplé les parties infrastructurelles de notre système, comme la base de données et les gestionnaires d’API, pour que nous puissions les brancher à l’extérieur de notre application. Cela nous aide à garder notre base de code bien organisée et nous empêche de construire une grosse boule de boue.
En appliquant le principe d’inversion de dépendance, et en utilisant des motifs inspirés de ports-et-adaptateurs comme Dépôt (Repository) et Unité de Travail (Unit of Work), nous avons rendu possible de faire du TDD en haute et basse vitesse et de maintenir une pyramide de tests saine. Nous pouvons tester notre système de bout en bout, et le besoin de tests d’intégration et de bout en bout est maintenu au minimum.
Enfin, nous avons parlé de l’idée de limites de cohérence. Nous ne voulons pas verrouiller notre système entier chaque fois que nous apportons un changement, donc nous devons choisir quelles parties sont cohérentes les unes avec les autres.
Pour un petit système, c’est tout ce dont vous avez besoin pour aller jouer avec les idées de conception pilotée par le domaine. Vous avez maintenant les outils pour construire des modèles de domaine indépendants de la base de données qui représentent le langage partagé de vos experts métier. Hourra !
| Au risque d’insister sur le point—nous avons pris soin de souligner que chaque motif vient avec un coût. Chaque couche d’indirection a un prix en termes de complexité et de duplication dans notre code et sera déroutant pour les programmeurs qui n’ont jamais vu ces motifs auparavant. Si votre application est essentiellement un simple wrapper CRUD autour d’une base de données et n’est pas susceptible d’être quoi que ce soit de plus que cela dans un avenir prévisible, vous n’avez pas besoin de ces motifs. Allez-y et utilisez Django, et économisez-vous beaucoup de tracas. |
Dans la Partie II, nous allons zoomer et parler d’un sujet plus large : si les agrégats sont notre limite, et que nous ne pouvons en mettre à jour qu’un à la fois, comment modélisons-nous les processus qui traversent les limites de cohérence ?
Architecture Événementielle
Je suis désolé d’avoir inventé il y a longtemps le terme "objets" pour ce sujet parce qu’il amène beaucoup de gens à se concentrer sur l’idée la moins importante.
La grande idée est "la messagerie."…La clé pour créer des systèmes formidables et évolutifs est beaucoup plus de concevoir comment ses modules communiquent plutôt que ce que leurs propriétés et comportements internes devraient être.
C’est très bien de pouvoir écrire un modèle de domaine pour gérer un seul morceau de processus métier, mais que se passe-t-il lorsque nous devons écrire plusieurs modèles ? Dans le monde réel, nos applications se situent au sein d’une organisation et doivent échanger des informations avec d’autres parties du système. Vous vous souvenez peut-être de notre diagramme de contexte montré dans Mais exactement comment tous ces systèmes vont-ils communiquer entre eux ?.
Face à cette exigence, de nombreuses équipes se tournent vers des microservices intégrés via des APIs HTTP. Mais si elles ne font pas attention, elles finiront par produire le désordre le plus chaotique de tous : la grosse boule de boue distribuée.
Dans la Partie II, nous montrerons comment les techniques de la Construire une Architecture pour Supporter la Modélisation de Domaine peuvent être étendues aux systèmes distribués. Nous prendrons du recul pour voir comment nous pouvons composer un système à partir de nombreux petits composants qui interagissent par passage de messages asynchrone.
Nous verrons comment nos patterns Couche de Service (Service Layer) et Unité de Travail (Unit of Work) nous permettent de reconfigurer notre application pour qu’elle s’exécute comme un processeur de messages asynchrone, et comment les systèmes événementiels nous aident à découpler les agrégats et les applications les uns des autres.
Nous examinerons les patterns et techniques suivants :
- Événements de Domaine (Domain Events)
-
Déclencher des workflows qui traversent les limites de cohérence.
- Bus de Messages (Message Bus)
-
Fournir une manière unifiée d’invoquer des cas d’usage depuis n’importe quel point d’entrée.
- CQRS
-
Séparer les lectures et les écritures évite des compromis maladroits dans une architecture événementielle et permet des améliorations de performance et d’évolutivité.
De plus, nous ajouterons un framework d’injection de dépendances. Cela n’a rien à voir avec l’architecture événementielle en soi, mais cela range beaucoup de fils pendants.
8. Événements et Bus de Messages (Events and the Message Bus)
Jusqu’à présent, nous avons passé beaucoup de temps et d’énergie sur un problème simple que nous aurions facilement pu résoudre avec Django. Vous vous demandez peut-être si l’amélioration de la testabilité et de l’expressivité valent vraiment tous les efforts.
En pratique, cependant, nous trouvons que ce ne sont pas les fonctionnalités évidentes qui mettent en désordre nos bases de code : c’est la substance collante autour des bords. C’est le reporting, et les permissions, et les workflows qui touchent un million d’objets.
Notre exemple sera une exigence de notification typique : quand nous ne pouvons pas allouer une commande parce que nous sommes en rupture de stock, nous devrions alerter l’équipe d’achat. Ils iront réparer le problème en achetant plus de stock, et tout ira bien.
Pour une première version, notre product owner dit que nous pouvons simplement envoyer l’alerte par email.
Voyons comment notre architecture tient le coup quand nous devons brancher certaines des choses banales qui constituent une grande partie de nos systèmes.
Nous commencerons par faire la chose la plus simple et la plus expédiente, et parlerons de pourquoi c’est exactement ce genre de décision qui nous mène au Big Ball of Mud (Grosse Boule de Boue).
Ensuite, nous montrerons comment utiliser le motif Événements de Domaine (Domain Events) pour séparer les effets secondaires de nos cas d’usage, et comment utiliser un simple motif Bus de Messages (Message Bus) pour déclencher un comportement basé sur ces événements. Nous montrerons quelques options pour créer ces événements et comment les passer au bus de messages, et enfin nous montrerons comment le motif Unité de Travail peut être modifié pour connecter les deux ensemble élégamment, comme prévisualisé dans Événements circulant à travers le système.
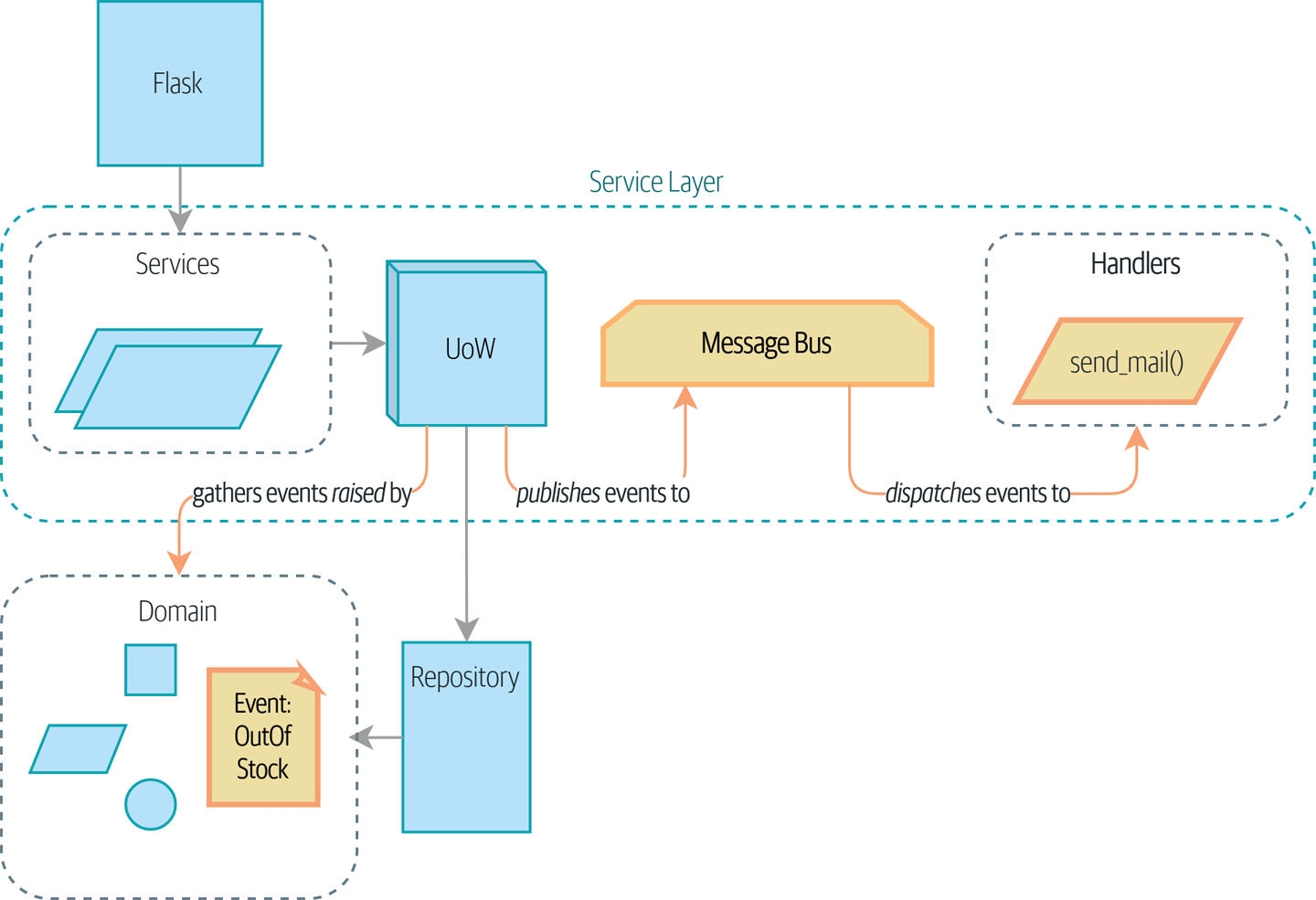
|
Le code pour ce chapitre se trouve dans la branche chapter_08_events_and_message_bus sur GitHub : git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_08_events_and_message_bus # ou pour coder en même temps, récupérez le chapitre précédent : git checkout chapter_07_aggregate |
8.1. Éviter de faire un gâchis
Donc. Alertes email quand nous sommes en rupture de stock. Quand nous avons de nouvelles exigences comme celles qui n’ont vraiment rien à voir avec le domaine principal, il est trop facile de commencer à déverser ces choses dans nos contrôleurs web.
8.1.1. D’abord, évitons de faire un gâchis de nos contrôleurs web
Comme un hack ponctuel, cela pourrait être OK :
@app.route("/allocate", methods=["POST"])
def allocate_endpoint():
line = model.OrderLine(
request.json["orderid"],
request.json["sku"],
request.json["qty"],
)
try:
uow = unit_of_work.SqlAlchemyUnitOfWork()
batchref = services.allocate(line, uow)
except (model.OutOfStock, services.InvalidSku) as e:
send_mail(
"out of stock",
"stock_admin@made.com",
f"{line.orderid} - {line.sku}"
)
return {"message": str(e)}, 400
return {"batchref": batchref}, 201…mais il est facile de voir comment nous pouvons rapidement nous retrouver dans un désordre en rafistolant les choses comme ça. L’envoi d’email n’est pas le travail de notre couche HTTP, et nous aimerions pouvoir tester unitairement cette nouvelle fonctionnalité.
8.1.2. Et ne faisons pas non plus un gâchis de notre modèle
En supposant que nous ne voulons pas mettre ce code dans nos contrôleurs web, parce que nous voulons qu’ils soient aussi minces que possible, nous pourrions envisager de le mettre directement à la source, dans le modèle :
def allocate(self, line: OrderLine) -> str:
try:
batch = next(b for b in sorted(self.batches) if b.can_allocate(line))
#...
except StopIteration:
email.send_mail("stock@made.com", f"Out of stock for {line.sku}")
raise OutOfStock(f"Out of stock for sku {line.sku}")Mais c’est encore pire ! Nous ne voulons pas que notre modèle ait des dépendances sur des préoccupations d’infrastructure comme email.send_mail.
Cette chose d’envoi d’email est une substance collante indésirable qui perturbe le flux propre et net de notre système. Ce que nous aimerions, c’est garder notre modèle de domaine concentré sur la règle "Vous ne pouvez pas allouer plus de trucs que ce qui est réellement disponible."
8.1.3. Ou la couche de service !
L’exigence "Essayer d’allouer du stock, et envoyer un email si cela échoue" est un exemple d’orchestration de workflow : c’est un ensemble d’étapes que le système doit suivre pour atteindre un objectif.
Nous avons écrit une couche de service pour gérer l’orchestration pour nous, mais même ici la fonctionnalité semble déplacée :
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork,
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
product = uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f"Invalid sku {line.sku}")
try:
batchref = product.allocate(line)
uow.commit()
return batchref
except model.OutOfStock:
email.send_mail("stock@made.com", f"Out of stock for {line.sku}")
raiseAttraper une exception et la relancer ? Cela pourrait être pire, mais cela nous rend définitivement malheureux. Pourquoi est-il si difficile de trouver un foyer approprié pour ce code ?
8.2. Principe de responsabilité unique
Vraiment, c’est une violation du principe de responsabilité unique (SRP).[26]
Notre cas d’usage est l’allocation. Notre point de terminaison, notre fonction de service et nos méthodes de domaine s’appellent tous allocate, pas
allocate_and_send_mail_if_out_of_stock.
| Règle empirique : si vous ne pouvez pas décrire ce que fait votre fonction sans utiliser des mots comme "puis" ou "et", vous pourriez violer le SRP. |
Une formulation du SRP est que chaque classe ne devrait avoir qu’une seule raison de changer. Quand nous passerons de l’email au SMS, nous ne devrions pas avoir à mettre à jour notre fonction allocate(), parce que c’est clairement une responsabilité séparée.
Pour résoudre le problème, nous allons diviser l’orchestration en étapes séparées de sorte que les différentes préoccupations ne s’emmêlent pas.[27] Le travail du modèle de domaine est de savoir que nous sommes en rupture de stock, mais la responsabilité d’envoyer une alerte appartient ailleurs. Nous devrions être capables d’activer ou de désactiver cette fonctionnalité, ou de passer aux notifications SMS à la place, sans avoir besoin de changer les règles de notre modèle de domaine.
Nous aimerions également garder la couche de service libre de détails d’implémentation. Nous voulons appliquer le principe d’inversion de dépendance aux notifications de sorte que notre couche de service dépende d’une abstraction, de la même manière que nous évitons de dépendre de la base de données en utilisant une unité de travail.
8.3. Tous à bord du Bus de Messages !
Les motifs que nous allons introduire ici sont Événements de Domaine (Domain Events) et le Bus de Messages (Message Bus). Nous pouvons les implémenter de quelques façons, donc nous en montrerons quelques-unes avant de nous fixer sur celle que nous préférons.
8.3.1. Le modèle enregistre les événements
D’abord, plutôt que de se préoccuper des emails, notre modèle sera en charge d’enregistrer des événements—des faits sur des choses qui se sont produites. Nous utiliserons un bus de messages pour répondre aux événements et invoquer une nouvelle opération.
8.3.2. Les événements sont de simples dataclasses
Un événement est une sorte d'objet valeur (value object). Les événements n’ont aucun comportement, parce qu’ils sont de pures structures de données. Nous nommons toujours les événements dans le langage du domaine, et nous pensons à eux comme faisant partie de notre modèle de domaine.
Nous pourrions les stocker dans model.py, mais nous pourrions aussi bien les garder dans leur propre fichier (cela pourrait être un bon moment pour envisager de refactoriser un répertoire appelé domain de sorte que nous ayons domain/model.py et domain/events.py) :
from dataclasses import dataclass
class Event: (1)
pass
@dataclass
class OutOfStock(Event): (2)
sku: str| 1 | Une fois que nous avons plusieurs événements, nous trouverons utile d’avoir une classe parente qui peut stocker des attributs communs. C’est également utile pour les annotations de type dans notre bus de messages, comme vous le verrez bientôt. |
| 2 | Les dataclasses sont également excellentes pour les événements de domaine. |
8.3.3. Le modèle lève des événements
Quand notre modèle de domaine enregistre un fait qui s’est produit, nous disons qu’il lève un événement.
Voici à quoi cela ressemblera de l’extérieur ; si nous demandons à Product d’allouer mais qu’il ne peut pas, il devrait lever un événement :
def test_records_out_of_stock_event_if_cannot_allocate():
batch = Batch("batch1", "SMALL-FORK", 10, eta=today)
product = Product(sku="SMALL-FORK", batches=[batch])
product.allocate(OrderLine("order1", "SMALL-FORK", 10))
allocation = product.allocate(OrderLine("order2", "SMALL-FORK", 1))
assert product.events[-1] == events.OutOfStock(sku="SMALL-FORK") (1)
assert allocation is None| 1 | Notre agrégat exposera un nouvel attribut appelé .events qui contiendra une liste de faits sur ce qui s’est passé, sous la forme d’objets Event. |
Voici à quoi ressemble le modèle de l’intérieur :
class Product:
def __init__(self, sku: str, batches: List[Batch], version_number: int = 0):
self.sku = sku
self.batches = batches
self.version_number = version_number
self.events = [] # type: List[events.Event] (1)
def allocate(self, line: OrderLine) -> str:
try:
#...
except StopIteration:
self.events.append(events.OutOfStock(line.sku)) (2)
# raise OutOfStock(f"Out of stock for sku {line.sku}") (3)
return None| 1 | Voici notre nouvel attribut .events en usage. |
| 2 | Plutôt que d’invoquer directement du code d’envoi d’email, nous enregistrons ces événements à l’endroit où ils se produisent, en utilisant uniquement le langage du domaine. |
| 3 | Nous allons également arrêter de lever une exception pour le cas de rupture de stock. L’événement fera le travail que l’exception faisait. |
| Nous abordons en fait un code smell que nous avions jusqu’à présent, qui est que nous utilisions des exceptions pour le contrôle de flux. En général, si vous implémentez des événements de domaine, ne levez pas d’exceptions pour décrire le même concept de domaine. Comme vous le verrez plus tard quand nous gérerons les événements dans le motif Unité de Travail, il est déroutant de devoir raisonner sur les événements et les exceptions ensemble. |
8.3.4. Le Bus de Messages mappe les événements aux gestionnaires
Un bus de messages dit fondamentalement : "Quand je vois cet événement, je devrais invoquer la fonction gestionnaire suivante." En d’autres termes, c’est un simple système publication-abonnement. Les gestionnaires sont abonnés pour recevoir des événements, que nous publions sur le bus. Cela semble plus difficile que ce n’est, et nous l’implémentons généralement avec un dict :
def handle(event: events.Event):
for handler in HANDLERS[type(event)]:
handler(event)
def send_out_of_stock_notification(event: events.OutOfStock):
email.send_mail(
"stock@made.com",
f"Out of stock for {event.sku}",
)
HANDLERS = {
events.OutOfStock: [send_out_of_stock_notification],
} # type: Dict[Type[events.Event], List[Callable]]| Notez que le bus de messages tel qu’implémenté ne nous donne pas de concurrence parce qu’un seul gestionnaire s’exécutera à la fois. Notre objectif n’est pas de supporter les threads parallèles mais de séparer les tâches conceptuellement, et de garder chaque UoW aussi petite que possible. Cela nous aide à comprendre la base de code parce que la "recette" pour exécuter chaque cas d’usage est écrite en un seul endroit. Voir l’encadré suivant. |
8.4. Option 1 : La couche de service prend les événements du modèle et les met sur le bus de messages
Notre modèle de domaine lève des événements, et notre bus de messages appellera les bons gestionnaires chaque fois qu’un événement se produit. Maintenant, tout ce dont nous avons besoin est de connecter les deux. Nous avons besoin de quelque chose pour attraper les événements du modèle et les passer au bus de messages—l’étape de publication.
La manière la plus simple de faire cela est d’ajouter du code dans notre couche de service :
from . import messagebus
...
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork,
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
product = uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f"Invalid sku {line.sku}")
try: (1)
batchref = product.allocate(line)
uow.commit()
return batchref
finally: (1)
messagebus.handle(product.events) (2)| 1 | Nous gardons le try/finally de notre implémentation laide précédente (nous ne nous sommes pas débarrassés de toutes les exceptions encore, juste OutOfStock). |
| 2 | Mais maintenant, au lieu de dépendre directement d’une infrastructure email, la couche de service est juste en charge de passer les événements du modèle jusqu’au bus de messages. |
Cela évite déjà une partie de la laideur que nous avions dans notre implémentation naïve, et nous avons plusieurs systèmes qui fonctionnent comme celui-ci, dans lesquels la couche de service collecte explicitement les événements des agrégats et les passe au bus de messages.
8.5. Option 2 : La couche de service lève ses propres événements
Une autre variante que nous avons utilisée est d’avoir la couche de service en charge de créer et de lever des événements directement, plutôt que de les faire lever par le modèle de domaine :
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork,
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
product = uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f"Invalid sku {line.sku}")
batchref = product.allocate(line)
uow.commit() (1)
if batchref is None:
messagebus.handle(events.OutOfStock(line.sku))
return batchref| 1 | Comme précédemment, nous validons même si nous ne parvenons pas à allouer parce que le code est plus simple de cette façon et qu’il est plus facile à raisonner : nous validons toujours sauf si quelque chose se passe mal. Valider quand nous n’avons rien changé est sûr et garde le code épuré. |
Encore une fois, nous avons des applications en production qui implémentent le motif de cette façon. Ce qui fonctionne pour vous dépendra des compromis particuliers auxquels vous êtes confronté, mais nous aimerions vous montrer ce que nous pensons être la solution la plus élégante, dans laquelle nous mettons l’unité de travail en charge de collecter et de lever les événements.
8.6. Option 3 : L’UoW publie les événements au Bus de Messages
L’UoW a déjà un try/finally, et elle connaît tous les agrégats actuellement en jeu parce qu’elle donne accès au dépôt. C’est donc un bon endroit pour repérer les événements et les passer au bus de messages :
class AbstractUnitOfWork(abc.ABC):
...
def commit(self):
self._commit() (1)
self.publish_events() (2)
def publish_events(self): (2)
for product in self.products.seen: (3)
while product.events:
event = product.events.pop(0)
messagebus.handle(event)
@abc.abstractmethod
def _commit(self):
raise NotImplementedError
...
class SqlAlchemyUnitOfWork(AbstractUnitOfWork):
...
def _commit(self): (1)
self.session.commit()| 1 | Nous changerons notre méthode commit pour exiger une méthode privée ._commit() des sous-classes. |
| 2 | Après la validation, nous parcourons tous les objets que notre dépôt a vus et passons leurs événements au bus de messages. |
| 3 | Cela repose sur le fait que le dépôt garde une trace des agrégats qui ont été chargés en utilisant un nouvel attribut, .seen, comme vous le verrez dans la liste suivante.
|
| Vous vous demandez ce qui se passe si l’un des gestionnaires échoue ? Nous discuterons de la gestion des erreurs en détail dans Commandes et Gestionnaire de Commandes. |
class AbstractRepository(abc.ABC):
def __init__(self):
self.seen = set() # type: Set[model.Product] (1)
def add(self, product: model.Product): (2)
self._add(product)
self.seen.add(product)
def get(self, sku) -> model.Product: (3)
product = self._get(sku)
if product:
self.seen.add(product)
return product
@abc.abstractmethod
def _add(self, product: model.Product): (2)
raise NotImplementedError
@abc.abstractmethod (3)
def _get(self, sku) -> model.Product:
raise NotImplementedError
class SqlAlchemyRepository(AbstractRepository):
def __init__(self, session):
super().__init__()
self.session = session
def _add(self, product): (2)
self.session.add(product)
def _get(self, sku): (3)
return self.session.query(model.Product).filter_by(sku=sku).first()| 1 | Pour que l’UoW puisse publier de nouveaux événements, elle doit pouvoir demander au dépôt quels objets Product ont été utilisés pendant cette session. Nous utilisons un set appelé .seen pour les stocker. Cela signifie que nos implémentations doivent appeler super().__init__().
|
| 2 | La méthode parente add() ajoute des choses à .seen, et exige maintenant que les sous-classes implémentent ._add(). |
| 3 | De même, .get() délègue à une fonction ._get(), à implémenter par les sous-classes, afin de capturer les objets vus. |
L’utilisation de méthodes ._underscorey() et de sous-classement n’est définitivement pas la seule façon dont vous pourriez implémenter ces motifs. Essayez l'"Exercice pour le lecteur" dans ce chapitre et expérimentez avec quelques alternatives.
|
Après que l’UoW et le dépôt collaborent de cette façon pour garder automatiquement une trace des objets vivants et traiter leurs événements, la couche de service peut être totalement libre de préoccupations de gestion d’événements :
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork,
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
product = uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f"Invalid sku {line.sku}")
batchref = product.allocate(line)
uow.commit()
return batchref
Nous devons également nous souvenir de changer les fakes dans la couche de service et de les faire appeler super() aux bons endroits, et d’implémenter les méthodes underscorey, mais les changements sont minimes :
class FakeRepository(repository.AbstractRepository):
def __init__(self, products):
super().__init__()
self._products = set(products)
def _add(self, product):
self._products.add(product)
def _get(self, sku):
return next((p for p in self._products if p.sku == sku), None)
...
class FakeUnitOfWork(unit_of_work.AbstractUnitOfWork):
...
def _commit(self):
self.committed = TrueVous pourriez commencer à vous inquiéter que maintenir ces fakes va être un fardeau de maintenance. Il n’y a aucun doute que c’est du travail, mais dans notre expérience, ce n’est pas beaucoup de travail. Une fois que votre projet est lancé, l’interface pour vos abstractions de dépôt et UoW ne change vraiment pas beaucoup. Et si vous utilisez des ABCs, ils vous aideront à vous rappeler quand les choses ne sont plus synchronisées.
8.7. Récapitulatif
Les événements de domaine nous donnent un moyen de gérer les workflows dans notre système. Nous trouvons souvent, en écoutant nos experts du domaine, qu’ils expriment des exigences de manière causale ou temporelle—par exemple, "Quand nous essayons d’allouer du stock mais qu’il n’y en a pas de disponible, alors nous devrions envoyer un email à l’équipe d’achat."
Les mots magiques "Quand X, alors Y" nous parlent souvent d’un événement que nous pouvons concrétiser dans notre système. Traiter les événements comme des choses de première classe dans notre modèle nous aide à rendre notre code plus testable et observable, et cela aide à isoler les préoccupations.
Et Événements de domaine : les compromis montre les compromis tels que nous les voyons.
| Pour | Contre |
|---|---|
|
|
Les événements sont utiles pour plus que juste envoyer des emails, cependant. Dans Agrégats et Limites de Cohérence (Aggregates and Consistency Boundaries) nous avons passé beaucoup de temps à vous convaincre que vous devriez définir des agrégats, ou des limites où nous garantissons la cohérence. Les gens demandent souvent : "Que dois-je faire si j’ai besoin de changer plusieurs agrégats dans le cadre d’une requête ?" Maintenant nous avons les outils dont nous avons besoin pour répondre à cette question.
Si nous avons deux choses qui peuvent être isolées transactionnellement (par exemple, une commande et un produit), alors nous pouvons les rendre éventuellement cohérentes en utilisant des événements. Quand une commande est annulée, nous devrions trouver les produits qui lui ont été alloués et retirer les allocations.
Dans Exploitation à Fond du Bus de Messages, nous examinerons cette idée plus en détail alors que nous construisons un workflow plus complexe avec notre nouveau bus de messages.
9. Exploitation à Fond du Bus de Messages
Dans ce chapitre, nous allons commencer à rendre les événements plus fondamentaux pour la structure interne de notre application. Nous passerons de l’état actuel dans Avant : le bus de messages (message bus) est un ajout optionnel, où les événements sont un effet secondaire optionnel…
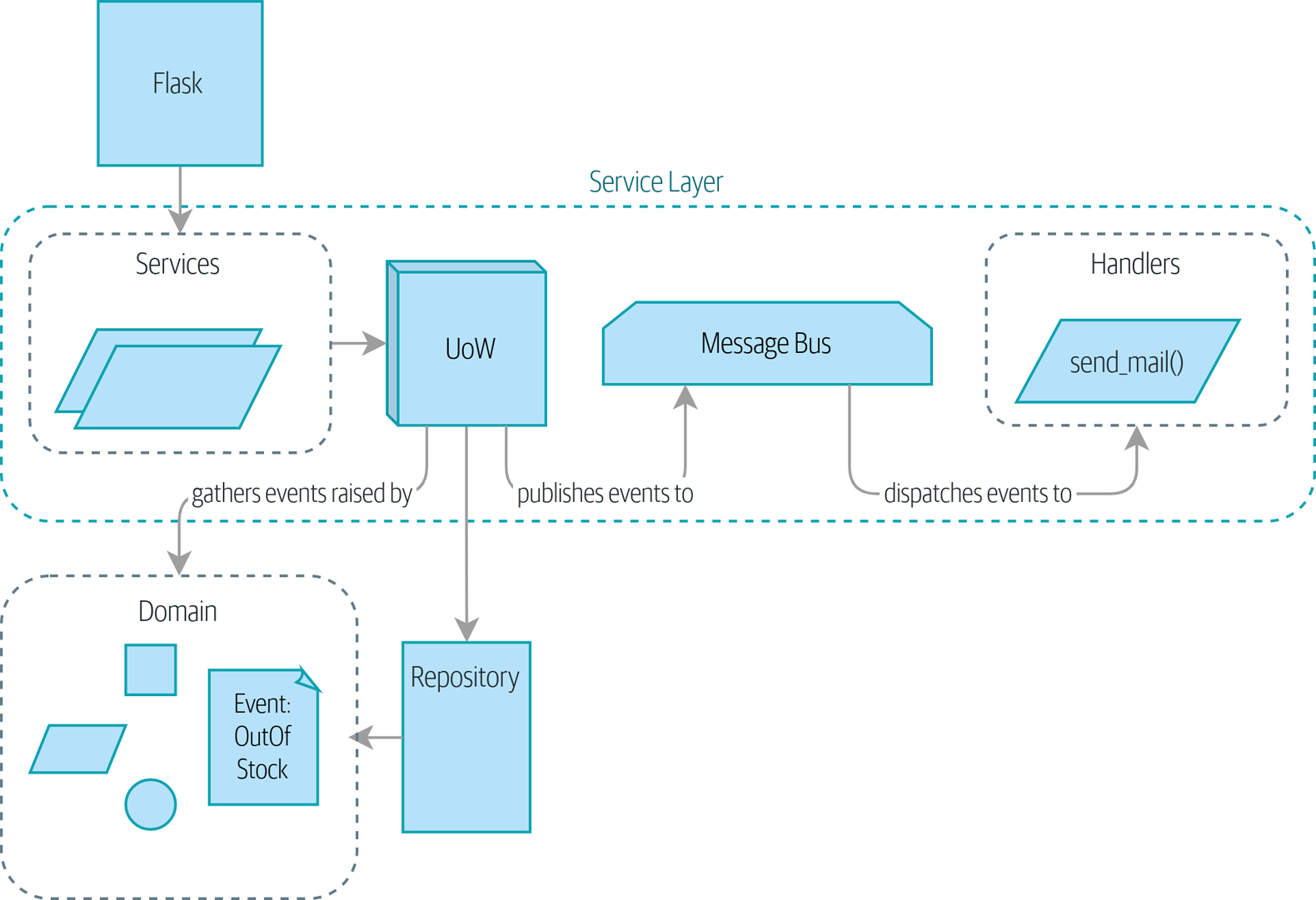
…à la situation dans Le bus de messages (message bus) est maintenant le point d’entrée principal vers la couche de service (service layer), où tout passe par le bus de messages, et notre application a été fondamentalement transformée en un processeur de messages.
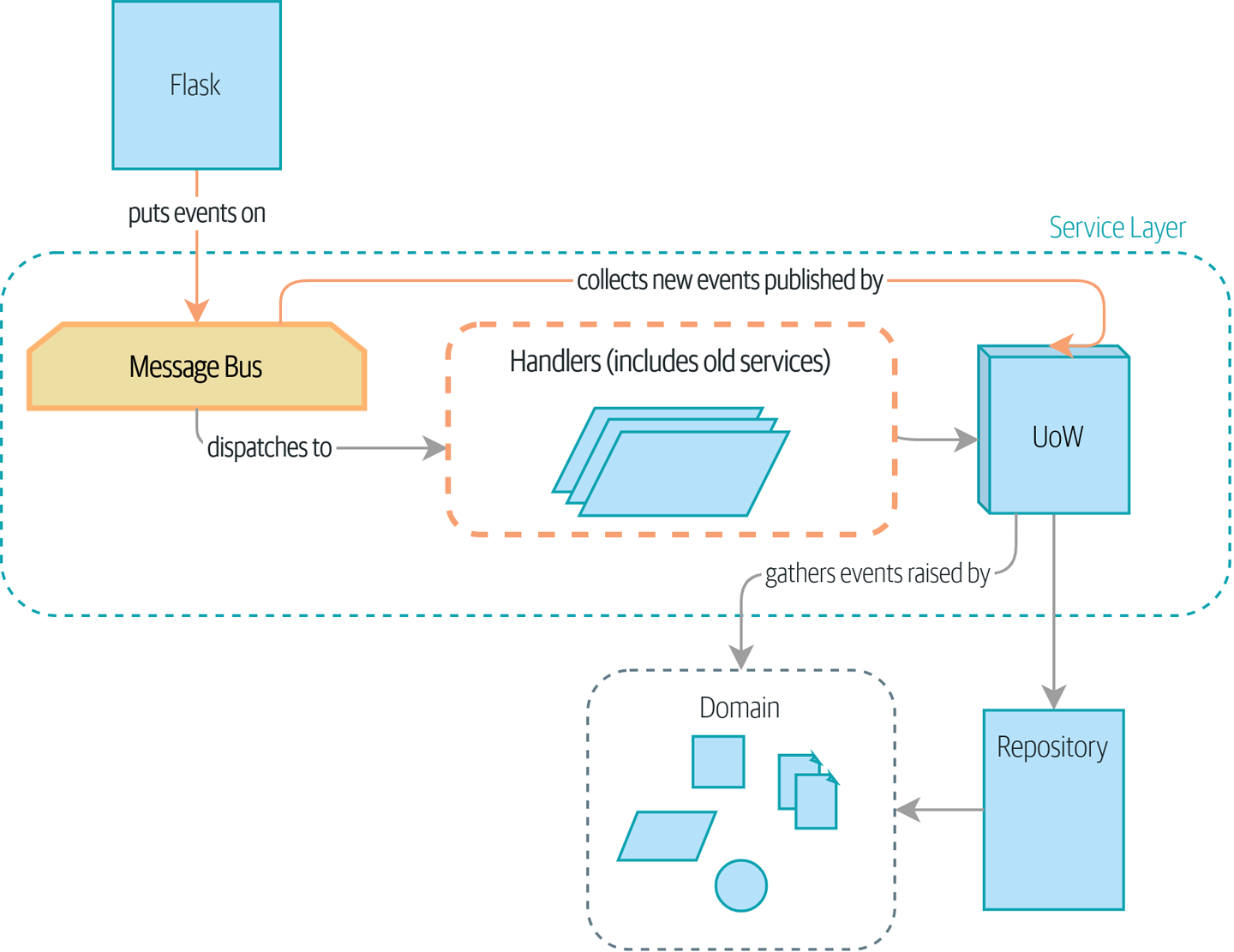
|
Le code de ce chapitre se trouve dans la branche chapter_09_all_messagebus sur GitHub: git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_09_all_messagebus # ou pour suivre, récupérez le chapitre précédent : git checkout chapter_08_events_and_message_bus |
9.1. Une Nouvelle Exigence Nous Conduit à une Nouvelle Architecture
Rich Hickey parle de situated software, c’est-à-dire un logiciel qui fonctionne pendant de longues périodes, gérant un processus du monde réel. Les exemples incluent les systèmes de gestion d’entrepôt, les planificateurs logistiques et les systèmes de paie.
Ce type de logiciel est délicat à écrire car des choses inattendues se produisent tout le temps dans le monde réel des objets physiques et des humains peu fiables. Par exemple :
-
Lors d’un inventaire, nous découvrons que trois
SPRINGY-MATTRESSont été endommagés par l’eau à cause d’une fuite dans le toit. -
Une expédition de
RELIABLE-FORKest bloquée à la douane pendant plusieurs semaines car il manque la documentation requise. TroisRELIABLE-FORKéchouent ensuite aux tests de sécurité et sont détruits. -
Une pénurie mondiale de paillettes signifie que nous ne pouvons pas fabriquer notre prochain lot de
SPARKLY-BOOKCASE.
Dans ces types de situations, nous apprenons qu’il faut modifier les quantités de lots alors qu’ils sont déjà dans le système. Peut-être que quelqu’un a fait une erreur sur le nombre dans le manifeste, ou peut-être que des canapés sont tombés d’un camion. Suite à une conversation avec le métier,[28] nous modélisons la situation comme dans Le changement de quantité de lot signifie désallouer et réallouer.

[ditaa, apwp_0903]
+----------+ /----\ +------------+ +--------------------+
| Batch |--> |RULE| --> | Deallocate | ----> | AllocationRequired |
| Quantity | \----/ +------------+-+ +--------------------+-+
| Changed | | Deallocate | ----> | AllocationRequired |
+----------+ +------------+-+ +--------------------+-+
| Deallocate | ----> | AllocationRequired |
+------------+ +--------------------+
Un événement que nous appellerons BatchQuantityChanged devrait nous amener à modifier la quantité du lot, oui, mais aussi à appliquer une règle métier : si la nouvelle quantité tombe en dessous du total déjà alloué, nous devons désallouer ces commandes de ce lot. Ensuite, chacune nécessitera une nouvelle allocation, que nous pouvons capturer comme un événement appelé AllocationRequired.
Vous anticipez peut-être déjà que notre bus de messages interne et nos événements peuvent nous aider à implémenter cette exigence. Nous pourrions définir un service appelé change_batch_quantity qui sait comment ajuster les quantités de lots et aussi comment désallouer toute ligne de commande excédentaire, puis chaque désallocation peut émettre un événement AllocationRequired qui peut être transmis au service allocate existant, dans des transactions séparées. Une fois de plus, notre bus de messages nous aide à faire respecter le principe de responsabilité unique, et il nous permet de faire des choix concernant les transactions et l’intégrité des données.
9.1.1. Imaginer un Changement d’Architecture : Tout Sera un Gestionnaire d’Événement
Mais avant de nous lancer, réfléchissons à où nous allons. Il existe deux types de flux dans notre système :
-
Les appels d’API qui sont gérés par une fonction de la couche de service
-
Les événements internes (qui peuvent être déclenchés comme effet secondaire d’une fonction de la couche de service) et leurs gestionnaires (handlers) (qui à leur tour appellent des fonctions de la couche de service)
Ne serait-il pas plus simple si tout était un gestionnaire d’événement ? Si nous repensons nos appels d’API comme capturant des événements, les fonctions de la couche de service peuvent également être des gestionnaires d’événements, et nous n’avons plus besoin de faire la distinction entre gestionnaires d’événements internes et externes :
-
services.allocate()pourrait être le gestionnaire (handler) pour un événementAllocationRequiredet pourrait émettre des événementsAllocateden sortie. -
services.add_batch()pourrait être le gestionnaire pour un événementBatchCreated.[29]
Notre nouvelle exigence suivra le même modèle :
-
Un événement appelé
BatchQuantityChangedpeut invoquer un gestionnaire appeléchange_batch_quantity(). -
Et les nouveaux événements
AllocationRequiredqu’il peut déclencher peuvent également être transmis àservices.allocate(), donc il n’y a pas de différence conceptuelle entre une toute nouvelle allocation provenant de l’API et une réallocation déclenchée en interne par une désallocation.
Tout cela semble un peu trop ? Travaillons-y progressivement. Nous suivrons le flux de travail Preparatory Refactoring, alias "Facilitez le changement ; puis effectuez le changement facile" :
-
Nous refactorisons notre couche de service en gestionnaires d’événements. Nous pouvons nous habituer à l’idée que les événements sont la façon dont nous décrivons les entrées du système. En particulier, la fonction existante
services.allocate()deviendra le gestionnaire pour un événement appeléAllocationRequired. -
Nous construisons un test de bout en bout qui met des événements
BatchQuantityChangeddans le système et recherche des événementsAllocateden sortie. -
Notre implémentation sera conceptuellement très simple : un nouveau gestionnaire pour les événements
BatchQuantityChanged, dont l’implémentation émettra des événementsAllocationRequired, qui à leur tour seront gérés par exactement le même gestionnaire pour les allocations que celui utilisé par l’API.
En cours de route, nous apporterons une petite modification au bus de messages et au UoW, en déplaçant la responsabilité de mettre de nouveaux événements sur le bus de messages dans le bus de messages lui-même.
9.2. Refactorisation des Fonctions de Service en Gestionnaires de Messages
Nous commençons par définir les deux événements qui capturent nos entrées d’API actuelles—AllocationRequired et BatchCreated :
@dataclass
class BatchCreated(Event):
ref: str
sku: str
qty: int
eta: Optional[date] = None
...
@dataclass
class AllocationRequired(Event):
orderid: str
sku: str
qty: intEnsuite, nous renommons services.py en handlers.py ; nous ajoutons le gestionnaire de messages existant pour send_out_of_stock_notification ; et surtout, nous modifions tous les gestionnaires pour qu’ils aient les mêmes entrées, un événement et un UoW :
def add_batch(
event: events.BatchCreated,
uow: unit_of_work.AbstractUnitOfWork,
):
with uow:
product = uow.products.get(sku=event.sku)
...
def allocate(
event: events.AllocationRequired,
uow: unit_of_work.AbstractUnitOfWork,
) -> str:
line = OrderLine(event.orderid, event.sku, event.qty)
...
def send_out_of_stock_notification(
event: events.OutOfStock,
uow: unit_of_work.AbstractUnitOfWork,
):
email.send(
"stock@made.com",
f"Out of stock for {event.sku}",
)Le changement pourrait être plus clair sous forme de diff :
def add_batch(
- ref: str, sku: str, qty: int, eta: Optional[date],
+ event: events.BatchCreated,
uow: unit_of_work.AbstractUnitOfWork,
):
with uow:
- product = uow.products.get(sku=sku)
+ product = uow.products.get(sku=event.sku)
...
def allocate(
- orderid: str, sku: str, qty: int,
+ event: events.AllocationRequired,
uow: unit_of_work.AbstractUnitOfWork,
) -> str:
- line = OrderLine(orderid, sku, qty)
+ line = OrderLine(event.orderid, event.sku, event.qty)
...
+
+def send_out_of_stock_notification(
+ event: events.OutOfStock,
+ uow: unit_of_work.AbstractUnitOfWork,
+):
+ email.send(
...En cours de route, nous avons rendu l’API de notre couche de service plus structurée et plus cohérente. C’était une dispersion de primitives, et maintenant elle utilise des objets bien définis (voir l’encadré suivant).
9.2.1. Le Bus de Messages Collecte Maintenant les Événements depuis le UoW
Nos gestionnaires d’événements ont maintenant besoin d’un UoW. De plus, comme notre bus de messages devient plus central dans notre application, il est logique de le mettre explicitement en charge de collecter et de traiter les nouveaux événements. Il y avait un peu de dépendance circulaire entre le UoW et le bus de messages jusqu’à présent, donc cela en fera une voie à sens unique. Au lieu que le UoW pousse les événements sur le bus de messages, nous ferons en sorte que le bus de messages tire les événements du UoW.
def handle(
event: events.Event,
uow: unit_of_work.AbstractUnitOfWork, (1)
):
queue = [event] (2)
while queue:
event = queue.pop(0) (3)
for handler in HANDLERS[type(event)]: (3)
handler(event, uow=uow) (4)
queue.extend(uow.collect_new_events()) (5)| 1 | Le bus de messages reçoit maintenant le UoW à chaque fois qu’il démarre. |
| 2 | Lorsque nous commençons à gérer notre premier événement, nous démarrons une file d’attente. |
| 3 | Nous récupérons les événements depuis le début de la file d’attente et invoquons leurs gestionnaires (le dictionnaire HANDLERS n’a pas changé ; il mappe toujours les types d’événements aux fonctions de gestionnaire). |
| 4 | Le bus de messages passe le UoW à chaque gestionnaire. |
| 5 | Après que chaque gestionnaire se termine, nous collectons tous les nouveaux événements qui ont été générés et les ajoutons à la file d’attente. |
Dans unit_of_work.py, publish_events() devient une méthode moins active, collect_new_events() :
-from . import messagebus (1)
class AbstractUnitOfWork(abc.ABC):
@@ -22,13 +21,11 @@ class AbstractUnitOfWork(abc.ABC):
def commit(self):
self._commit()
- self.publish_events() (2)
- def publish_events(self):
+ def collect_new_events(self):
for product in self.products.seen:
while product.events:
- event = product.events.pop(0)
- messagebus.handle(event)
+ yield product.events.pop(0) (3)| 1 | Le module unit_of_work ne dépend plus de messagebus. |
| 2 | Nous ne faisons plus publish_events automatiquement lors du commit. Le bus de messages suit la file d’événements à la place. |
| 3 | Et le UoW ne met plus activement les événements sur le bus de messages ; il les rend simplement disponibles. |
9.2.2. Nos Tests Sont Tous Écrits en Termes d’Événements Aussi
Nos tests fonctionnent maintenant en créant des événements et en les mettant sur le bus de messages, plutôt qu’en invoquant directement les fonctions de la couche de service :
class TestAddBatch:
def test_for_new_product(self):
uow = FakeUnitOfWork()
- services.add_batch("b1", "CRUNCHY-ARMCHAIR", 100, None, uow)
+ messagebus.handle(
+ events.BatchCreated("b1", "CRUNCHY-ARMCHAIR", 100, None), uow
+ )
assert uow.products.get("CRUNCHY-ARMCHAIR") is not None
assert uow.committed
...
class TestAllocate:
def test_returns_allocation(self):
uow = FakeUnitOfWork()
- services.add_batch("batch1", "COMPLICATED-LAMP", 100, None, uow)
- result = services.allocate("o1", "COMPLICATED-LAMP", 10, uow)
+ messagebus.handle(
+ events.BatchCreated("batch1", "COMPLICATED-LAMP", 100, None), uow
+ )
+ result = messagebus.handle(
+ events.AllocationRequired("o1", "COMPLICATED-LAMP", 10), uow
+ )
assert result == "batch1"9.2.3. Un Hack Temporaire Moche : Le Bus de Messages Doit Retourner des Résultats
Notre API et notre couche de service veulent actuellement connaître la référence du lot alloué lorsqu’ils invoquent notre gestionnaire allocate(). Cela signifie que nous devons mettre en place un hack temporaire sur notre bus de messages pour lui permettre de retourner des événements :
def handle(
event: events.Event,
uow: unit_of_work.AbstractUnitOfWork,
):
+ results = []
queue = [event]
while queue:
event = queue.pop(0)
for handler in HANDLERS[type(event)]:
- handler(event, uow=uow)
+ results.append(handler(event, uow=uow))
queue.extend(uow.collect_new_events())
+ return resultsC’est parce que nous mélangeons les responsabilités de lecture et d’écriture dans notre système. Nous reviendrons corriger cette verrue dans CQRS (Command Query Responsibility Segregation/Ségrégation des Responsabilités Commande-Requête).
9.2.4. Modification de Notre API pour Travailler avec des Événements
@app.route("/allocate", methods=["POST"])
def allocate_endpoint():
try:
- batchref = services.allocate(
- request.json["orderid"], (1)
- request.json["sku"],
- request.json["qty"],
- unit_of_work.SqlAlchemyUnitOfWork(),
+ event = events.AllocationRequired( (2)
+ request.json["orderid"], request.json["sku"], request.json["qty"]
)
+ results = messagebus.handle(event, unit_of_work.SqlAlchemyUnitOfWork()) (3)
+ batchref = results.pop(0)
except InvalidSku as e:| 1 | Au lieu d’appeler la couche de service avec un tas de primitives extraites du JSON de la requête… |
| 2 | Nous instancions un événement. |
| 3 | Ensuite, nous le passons au bus de messages. |
Et nous devrions revenir à une application entièrement fonctionnelle, mais qui est maintenant entièrement pilotée par les événements :
-
Ce qui était autrefois des fonctions de la couche de service sont maintenant des gestionnaires d’événements.
-
Cela les rend identiques aux fonctions que nous invoquons pour gérer les événements internes déclenchés par notre modèle de domaine.
-
Nous utilisons les événements comme structure de données pour capturer les entrées du système, ainsi que pour le transfert des paquets de travail internes.
-
L’application entière est maintenant mieux décrite comme un processeur de messages, ou un processeur d’événements si vous préférez. Nous parlerons de la distinction dans le chapitre suivant.
9.3. Implémentation de Notre Nouvelle Exigence
Nous avons terminé notre phase de refactorisation. Voyons si nous avons vraiment "facilité le changement". Implémentons notre nouvelle exigence, montrée dans Diagramme de séquence pour le flux de réallocation : nous recevrons en entrée de nouveaux événements BatchQuantityChanged et les passerons à un gestionnaire, qui à son tour pourrait émettre des événements AllocationRequired, et ceux-ci iront à nouveau vers notre gestionnaire existant pour la réallocation.
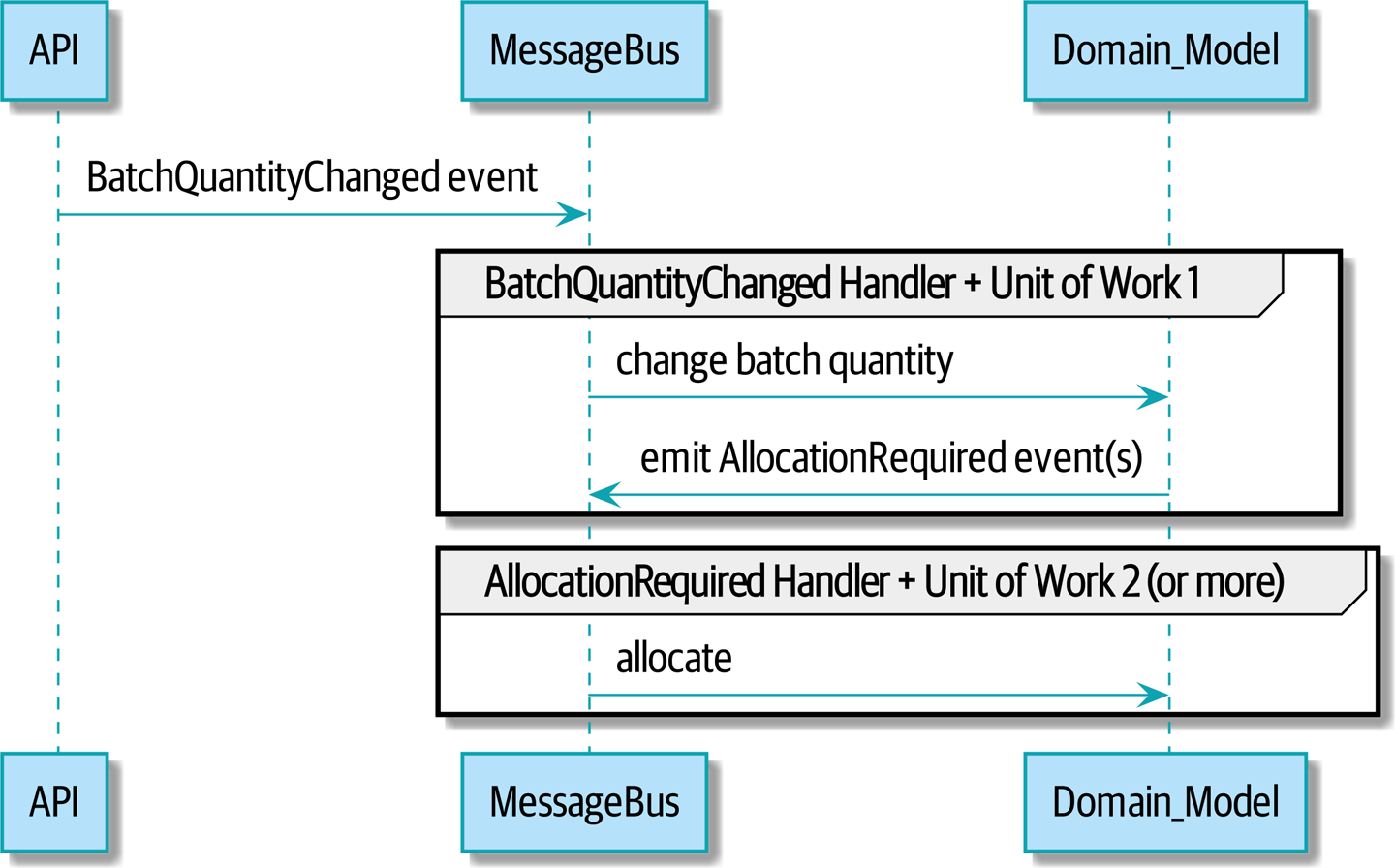
[plantuml, apwp_0904, config=plantuml.cfg]
@startuml
scale 4
API -> MessageBus : BatchQuantityChanged event
group BatchQuantityChanged Handler + Unit of Work 1
MessageBus -> Domain_Model : change batch quantity
Domain_Model -> MessageBus : emit AllocationRequired event(s)
end
group AllocationRequired Handler + Unit of Work 2 (or more)
MessageBus -> Domain_Model : allocate
end
@enduml
| Lorsque vous divisez les choses comme cela entre deux unités de travail (units of work), vous avez maintenant deux transactions de base de données, donc vous vous exposez à des problèmes d’intégrité : quelque chose pourrait arriver qui fait que la première transaction se termine mais pas la seconde. Vous devrez réfléchir si cela est acceptable, et si vous devez remarquer quand cela se produit et faire quelque chose à ce sujet. Voir Pièges pour plus de discussion. |
9.3.1. Notre Nouvel Événement
L’événement qui nous indique qu’une quantité de lot a changé est simple ; il a juste besoin d’une référence de lot et d’une nouvelle quantité :
@dataclass
class BatchQuantityChanged(Event):
ref: str
qty: int9.4. Développement Guidé par les Tests d’un Nouveau Gestionnaire
En suivant les leçons apprises dans Notre Premier Cas d’Usage (Use Case) : API Flask et Couche de Service (Service Layer), nous pouvons opérer en "vitesse supérieure" et écrire nos tests unitaires au niveau d’abstraction le plus élevé possible, en termes d’événements. Voici à quoi ils pourraient ressembler :
class TestChangeBatchQuantity:
def test_changes_available_quantity(self):
uow = FakeUnitOfWork()
messagebus.handle(
events.BatchCreated("batch1", "ADORABLE-SETTEE", 100, None), uow
)
[batch] = uow.products.get(sku="ADORABLE-SETTEE").batches
assert batch.available_quantity == 100 (1)
messagebus.handle(events.BatchQuantityChanged("batch1", 50), uow)
assert batch.available_quantity == 50 (1)
def test_reallocates_if_necessary(self):
uow = FakeUnitOfWork()
event_history = [
events.BatchCreated("batch1", "INDIFFERENT-TABLE", 50, None),
events.BatchCreated("batch2", "INDIFFERENT-TABLE", 50, date.today()),
events.AllocationRequired("order1", "INDIFFERENT-TABLE", 20),
events.AllocationRequired("order2", "INDIFFERENT-TABLE", 20),
]
for e in event_history:
messagebus.handle(e, uow)
[batch1, batch2] = uow.products.get(sku="INDIFFERENT-TABLE").batches
assert batch1.available_quantity == 10
assert batch2.available_quantity == 50
messagebus.handle(events.BatchQuantityChanged("batch1", 25), uow)
# order1 ou order2 sera désalloué, donc nous aurons 25 - 20
assert batch1.available_quantity == 5 (2)
# et 20 sera réalloué au prochain lot
assert batch2.available_quantity == 30 (2)| 1 | Le cas simple serait trivialement facile à implémenter ; nous modifions simplement une quantité. |
| 2 | Mais si nous essayons de changer la quantité à moins que ce qui a été alloué, nous devrons désallouer au moins une commande, et nous nous attendons à la réallouer à un nouveau lot. |
9.4.1. Implémentation
Notre nouveau gestionnaire est très simple :
def change_batch_quantity(
event: events.BatchQuantityChanged,
uow: unit_of_work.AbstractUnitOfWork,
):
with uow:
product = uow.products.get_by_batchref(batchref=event.ref)
product.change_batch_quantity(ref=event.ref, qty=event.qty)
uow.commit()Nous réalisons que nous aurons besoin d’un nouveau type de requête sur notre dépôt (repository) :
class AbstractRepository(abc.ABC):
...
def get(self, sku) -> model.Product:
...
def get_by_batchref(self, batchref) -> model.Product:
product = self._get_by_batchref(batchref)
if product:
self.seen.add(product)
return product
@abc.abstractmethod
def _add(self, product: model.Product):
raise NotImplementedError
@abc.abstractmethod
def _get(self, sku) -> model.Product:
raise NotImplementedError
@abc.abstractmethod
def _get_by_batchref(self, batchref) -> model.Product:
raise NotImplementedError
...
class SqlAlchemyRepository(AbstractRepository):
...
def _get(self, sku):
return self.session.query(model.Product).filter_by(sku=sku).first()
def _get_by_batchref(self, batchref):
return (
self.session.query(model.Product)
.join(model.Batch)
.filter(orm.batches.c.reference == batchref)
.first()
)
Et aussi sur notre FakeRepository :
class FakeRepository(repository.AbstractRepository):
...
def _get(self, sku):
return next((p for p in self._products if p.sku == sku), None)
def _get_by_batchref(self, batchref):
return next(
(p for p in self._products for b in p.batches if b.reference == batchref),
None,
)
Nous ajoutons une requête à notre dépôt pour rendre ce cas d’usage (use case) plus facile à implémenter. Tant que notre requête retourne un seul agrégat, nous ne violons aucune règle. Si vous vous retrouvez à écrire des requêtes complexes sur vos dépôts, vous voudrez peut-être envisager une conception différente. Des méthodes comme get_most_popular_products ou find_products_by_order_id en particulier déclencheraient certainement notre sens de l’araignée. Architecture Orientée Événements : Utilisation des Événements pour Intégrer des Microservices et l'épilogue ont quelques conseils sur la gestion des requêtes complexes.
|
9.4.2. Une Nouvelle Méthode sur le Modèle de Domaine
Nous ajoutons la nouvelle méthode au modèle, qui effectue le changement de quantité et les désallocation(s) en ligne et publie un nouvel événement. Nous modifions également la fonction allocate existante pour publier un événement :
class Product:
...
def change_batch_quantity(self, ref: str, qty: int):
batch = next(b for b in self.batches if b.reference == ref)
batch._purchased_quantity = qty
while batch.available_quantity < 0:
line = batch.deallocate_one()
self.events.append(
events.AllocationRequired(line.orderid, line.sku, line.qty)
)
...
class Batch:
...
def deallocate_one(self) -> OrderLine:
return self._allocations.pop()Nous connectons notre nouveau gestionnaire :
HANDLERS = {
events.BatchCreated: [handlers.add_batch],
events.BatchQuantityChanged: [handlers.change_batch_quantity],
events.AllocationRequired: [handlers.allocate],
events.OutOfStock: [handlers.send_out_of_stock_notification],
} # type: Dict[Type[events.Event], List[Callable]]Et notre nouvelle exigence est entièrement implémentée.
9.5. Optionnel : Test Unitaire des Gestionnaires d’Événements en Isolation avec un Faux Bus de Messages
Notre test principal pour le flux de travail de réallocation est de bout en bout (voir l’exemple de code dans Développement Guidé par les Tests d’un Nouveau Gestionnaire). Il utilise le vrai bus de messages, et il teste tout le flux, où le gestionnaire d’événement BatchQuantityChanged déclenche la désallocation, et émet de nouveaux événements AllocationRequired, qui à leur tour sont gérés par leurs propres gestionnaires. Un test couvre une chaîne de plusieurs événements et gestionnaires.
Selon la complexité de votre chaîne d’événements, vous pouvez décider que vous voulez tester certains gestionnaires en isolation les uns des autres. Vous pouvez le faire en utilisant un bus de messages "factice".
Dans notre cas, nous intervenons en fait en modifiant la méthode publish_events() sur FakeUnitOfWork et en la découplant du vrai bus de messages, en la faisant à la place enregistrer les événements qu’elle voit :
class FakeUnitOfWorkWithFakeMessageBus(FakeUnitOfWork):
def __init__(self):
super().__init__()
self.events_published = [] # type: List[events.Event]
def publish_events(self):
for product in self.products.seen:
while product.events:
self.events_published.append(product.events.pop(0))
Maintenant, lorsque nous invoquons messagebus.handle() en utilisant le FakeUnitOfWorkWithFakeMessageBus, il exécute uniquement le gestionnaire pour cet événement. Nous pouvons donc écrire un test unitaire plus isolé : au lieu de vérifier tous les effets secondaires, nous vérifions simplement que BatchQuantityChanged conduit à AllocationRequired si la quantité tombe en dessous du total déjà alloué :
def test_reallocates_if_necessary_isolated():
uow = FakeUnitOfWorkWithFakeMessageBus()
# configuration du test comme avant
event_history = [
events.BatchCreated("batch1", "INDIFFERENT-TABLE", 50, None),
events.BatchCreated("batch2", "INDIFFERENT-TABLE", 50, date.today()),
events.AllocationRequired("order1", "INDIFFERENT-TABLE", 20),
events.AllocationRequired("order2", "INDIFFERENT-TABLE", 20),
]
for e in event_history:
messagebus.handle(e, uow)
[batch1, batch2] = uow.products.get(sku="INDIFFERENT-TABLE").batches
assert batch1.available_quantity == 10
assert batch2.available_quantity == 50
messagebus.handle(events.BatchQuantityChanged("batch1", 25), uow)
# assertion sur les nouveaux événements émis plutôt que sur les effets secondaires en aval
[reallocation_event] = uow.events_published
assert isinstance(reallocation_event, events.AllocationRequired)
assert reallocation_event.orderid in {"order1", "order2"}
assert reallocation_event.sku == "INDIFFERENT-TABLE"Que vous souhaitiez faire cela ou non dépend de la complexité de votre chaîne d’événements. Nous disons, commencez par des tests de bout en bout, et n’utilisez cette approche que si nécessaire.
9.6. Récapitulatif
Regardons en arrière ce que nous avons accompli, et réfléchissons aux raisons.
9.6.1. Qu’avons-nous Accompli ?
Les événements (events) sont de simples dataclasses qui définissent les structures de données pour les entrées et les messages internes au sein de notre système. C’est assez puissant d’un point de vue DDD, car les événements se traduisent souvent très bien en langage métier (cherchez event storming si vous ne l’avez pas déjà fait).
Les gestionnaires (handlers) sont la façon dont nous réagissons aux événements. Ils peuvent appeler vers le bas dans notre modèle ou appeler des services externes. Nous pouvons définir plusieurs gestionnaires pour un seul événement si nous le souhaitons. Les gestionnaires peuvent également déclencher d’autres événements. Cela nous permet d’être très granulaires sur ce que fait un gestionnaire et de vraiment respecter le SRP.
9.6.2. Pourquoi Avons-nous Accompli ?
Notre objectif continu avec ces patterns architecturaux est d’essayer de faire en sorte que la complexité de notre application croisse plus lentement que sa taille. Lorsque nous misons tout sur le bus de messages, comme toujours nous payons un prix en termes de complexité architecturale (voir Toute l’application est un bus de messages : les compromis), mais nous nous offrons un pattern qui peut gérer des exigences presque arbitrairement complexes sans nécessiter de changement conceptuel ou architectural supplémentaire dans notre façon de faire.
Ici, nous avons ajouté un cas d’usage assez compliqué (changer la quantité, désallouer, démarrer une nouvelle transaction, réallouer, publier une notification externe), mais architecturalement, il n’y a eu aucun coût en termes de complexité. Nous avons ajouté de nouveaux événements, de nouveaux gestionnaires et un nouvel adaptateur externe (pour l’email), qui sont tous des catégories existantes de choses dans notre architecture que nous comprenons et savons comment raisonner, et qui sont faciles à expliquer aux nouveaux venus. Nos pièces mobiles ont chacune un travail, elles sont connectées les unes aux autres de manières bien définies, et il n’y a pas d’effets secondaires inattendus.
| Avantages | Inconvénients |
|---|---|
|
|
Maintenant, vous vous demandez peut-être, d’où viennent ces événements BatchQuantityChanged ? La réponse est révélée dans quelques chapitres. Mais d’abord, parlons des événements versus commandes.
10. Commandes et Gestionnaire de Commandes
Dans le chapitre précédent, nous avons parlé de l’utilisation des événements (events) comme moyen de représenter les entrées de notre système, et nous avons transformé notre application en une machine de traitement de messages.
Pour y parvenir, nous avons converti toutes nos fonctions de cas d’usage (use case) en gestionnaires d’événements (event handlers). Lorsque l’API reçoit un POST pour créer un nouveau lot, elle construit un nouvel événement BatchCreated et le gère comme s’il s’agissait d’un événement interne. Cela peut sembler contre-intuitif. Après tout, le lot n’a pas encore été créé ; c’est pourquoi nous avons appelé l’API. Nous allons corriger cette verrue conceptuelle en introduisant les commandes (commands) et en montrant comment elles peuvent être gérées par le même bus de messages mais avec des règles légèrement différentes.
|
Le code de ce chapitre se trouve dans la branche chapter_10_commands sur GitHub : git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_10_commands # ou pour suivre, récupérez le chapitre précédent : git checkout chapter_09_all_messagebus |
10.1. Commandes et Événements
Comme les événements, les commandes sont un type de message — des instructions envoyées par une partie d’un système à une autre. Nous représentons généralement les commandes avec des structures de données simples et pouvons les gérer de la même manière que les événements.
Les différences entre commandes et événements sont cependant importantes.
Les commandes (commands) sont envoyées par un acteur à un autre acteur spécifique avec l’attente qu’une chose particulière se produira en conséquence. Lorsque nous soumettons un formulaire à un gestionnaire d’API, nous envoyons une commande. Nous nommons les commandes avec des expressions verbales à l’impératif comme "allouer le stock" ou "retarder l’expédition".
Les commandes capturent l’intention. Elles expriment notre souhait que le système fasse quelque chose. En conséquence, lorsqu’elles échouent, l’expéditeur doit recevoir des informations sur l’erreur.
Les événements (events) sont diffusés par un acteur à tous les auditeurs intéressés. Lorsque nous publions BatchQuantityChanged, nous ne savons pas qui va le récupérer. Nous nommons les événements avec des expressions verbales au passé comme "commande allouée au stock" ou "expédition retardée".
Nous utilisons souvent des événements pour diffuser la connaissance de commandes réussies.
Les événements capturent des faits sur des choses qui se sont produites dans le passé. Puisque nous ne savons pas qui gère un événement, les expéditeurs ne devraient pas se soucier de savoir si les récepteurs ont réussi ou échoué. Le Événements versus commandes récapitule les différences.
| Événement | Commande | |
|---|---|---|
Nommé |
Passé |
Mode impératif |
Gestion d’erreur |
Échouent indépendamment |
Échouent bruyamment |
Envoyé à |
Tous les auditeurs |
Un destinataire |
Quels types de commandes avons-nous dans notre système actuellement ?
class Command:
pass
@dataclass
class Allocate(Command): (1)
orderid: str
sku: str
qty: int
@dataclass
class CreateBatch(Command): (2)
ref: str
sku: str
qty: int
eta: Optional[date] = None
@dataclass
class ChangeBatchQuantity(Command): (3)
ref: str
qty: int| 1 | commands.Allocate remplacera events.AllocationRequired. |
| 2 | commands.CreateBatch remplacera events.BatchCreated. |
| 3 | commands.ChangeBatchQuantity remplacera events.BatchQuantityChanged. |
10.2. Différences dans la Gestion des Exceptions
Simplement changer les noms et les verbes c’est très bien, mais cela ne changera pas le comportement de notre système. Nous voulons traiter les événements et les commandes de manière similaire, mais pas exactement de la même manière. Voyons comment notre bus de messages change :
Message = Union[commands.Command, events.Event]
def handle( (1)
message: Message,
uow: unit_of_work.AbstractUnitOfWork,
):
results = []
queue = [message]
while queue:
message = queue.pop(0)
if isinstance(message, events.Event):
handle_event(message, queue, uow) (2)
elif isinstance(message, commands.Command):
cmd_result = handle_command(message, queue, uow) (2)
results.append(cmd_result)
else:
raise Exception(f"{message} was not an Event or Command")
return results| 1 | Il a toujours un point d’entrée principal handle() qui prend un message, qui peut être une commande ou un événement. |
| 2 | Nous distribuons les événements et les commandes à deux fonctions d’aide différentes, montrées ensuite. |
Voici comment nous gérons les événements :
def handle_event(
event: events.Event,
queue: List[Message],
uow: unit_of_work.AbstractUnitOfWork,
):
for handler in EVENT_HANDLERS[type(event)]: (1)
try:
logger.debug("handling event %s with handler %s", event, handler)
handler(event, uow=uow)
queue.extend(uow.collect_new_events())
except Exception:
logger.exception("Exception handling event %s", event)
continue (2)| 1 | Les événements vont vers un distributeur qui peut déléguer à plusieurs gestionnaires (handlers) par événement. |
| 2 | Il capture et enregistre les erreurs mais ne les laisse pas interrompre le traitement des messages. |
Et voici comment nous gérons les commandes :
def handle_command(
command: commands.Command,
queue: List[Message],
uow: unit_of_work.AbstractUnitOfWork,
):
logger.debug("handling command %s", command)
try:
handler = COMMAND_HANDLERS[type(command)] (1)
result = handler(command, uow=uow)
queue.extend(uow.collect_new_events())
return result (3)
except Exception:
logger.exception("Exception handling command %s", command)
raise (2)| 1 | Le distributeur de commandes attend un seul gestionnaire (handler) par commande. |
| 2 | Si des erreurs sont levées, elles échouent rapidement et remonteront. |
| 3 | return result n’est que temporaire ; comme mentionné dans Un Hack Temporaire Moche : Le Bus de Messages Doit Retourner des Résultats, c’est un hack temporaire pour permettre au bus de messages de retourner la référence de lot pour que l’API l’utilise. Nous corrigerons cela dans CQRS (Command Query Responsibility Segregation/Ségrégation des Responsabilités Commande-Requête). |
Nous changeons également le dictionnaire unique HANDLERS en dictionnaires différents pour les commandes et les événements. Les commandes ne peuvent avoir qu’un seul gestionnaire (handler), selon notre convention :
EVENT_HANDLERS = {
events.OutOfStock: [handlers.send_out_of_stock_notification],
} # type: Dict[Type[events.Event], List[Callable]]
COMMAND_HANDLERS = {
commands.Allocate: handlers.allocate,
commands.CreateBatch: handlers.add_batch,
commands.ChangeBatchQuantity: handlers.change_batch_quantity,
} # type: Dict[Type[commands.Command], Callable]10.3. Discussion : Événements, Commandes et Gestion d’Erreurs
Beaucoup de développeurs deviennent mal à l’aise à ce stade et demandent : "Que se passe-t-il lorsqu’un événement échoue à être traité ? Comment suis-je censé m’assurer que le système est dans un état cohérent ?" Si nous parvenons à traiter la moitié des événements pendant messagebus.handle avant qu’une erreur de mémoire insuffisante ne tue notre processus, comment atténuer les problèmes causés par les messages perdus ?
Commençons par le pire cas : nous échouons à gérer un événement, et le système est laissé dans un état incohérent. Quel type d’erreur causerait cela ? Souvent dans nos systèmes, nous pouvons nous retrouver dans un état incohérent lorsque seulement la moitié d’une opération est terminée.
Par exemple, nous pourrions allouer trois unités de DESIRABLE_BEANBAG à la commande d’un client mais échouer d’une manière ou d’une autre à réduire la quantité de stock restant. Cela causerait un état incohérent : les trois unités de stock sont à la fois allouées et disponibles, selon la façon dont vous le regardez. Plus tard, nous pourrions allouer ces mêmes poufs à un autre client, causant un casse-tête pour le support client.
Dans notre service d’allocation, cependant, nous avons déjà pris des mesures pour empêcher que cela se produise. Nous avons soigneusement identifié des agrégats (aggregates) qui agissent comme des limites de cohérence, et nous avons introduit un UoW qui gère le succès ou l’échec atomique d’une mise à jour d’un agrégat.
Par exemple, lorsque nous allouons du stock à une commande, notre limite de cohérence est l’agrégat Product. Cela signifie que nous ne pouvons pas accidentellement sur-allouer : soit une ligne de commande particulière est allouée au produit, soit elle ne l’est pas — il n’y a pas de place pour des états incohérents.
Par définition, nous n’exigeons pas que deux agrégats soient immédiatement cohérents, donc si nous échouons à traiter un événement et mettons à jour un seul agrégat, notre système peut toujours être rendu éventuellement cohérent. Nous ne devrions violer aucune contrainte du système.
Avec cet exemple à l’esprit, nous pouvons mieux comprendre la raison de diviser les messages en commandes et événements. Lorsqu’un utilisateur veut faire faire quelque chose au système, nous représentons sa demande comme une commande (command). Cette commande devrait modifier un seul agrégat (aggregate) et soit réussir, soit échouer dans sa totalité. Toute autre tenue de livres, nettoyage et notification que nous devons faire peut se produire via un événement (event). Nous n’exigeons pas que les gestionnaires d’événements réussissent pour que la commande soit réussie.
Examinons un autre exemple (d’un projet différent, imaginaire) pour voir pourquoi non.
Imaginez que nous construisons un site web de commerce électronique qui vend des produits de luxe coûteux. Notre département marketing veut récompenser les clients pour les visites répétées. Nous marquerons les clients comme VIP après qu’ils aient effectué leur troisième achat, et cela leur donnera droit à un traitement prioritaire et à des offres spéciales. Nos critères d’acceptation pour cette histoire se lisent comme suit :
Given a customer with two orders in their history,
When the customer places a third order,
Then they should be flagged as a VIP.
When a customer first becomes a VIP
Then we should send them an email to congratulate them
En utilisant les techniques que nous avons déjà discutées dans ce livre, nous décidons que nous voulons construire un nouvel agrégat History qui enregistre les commandes et peut déclencher des événements de domaine (domain events) lorsque les règles sont respectées. Nous structurerons le code comme ceci :
class History: # Aggregate
def __init__(self, customer_id: int):
self.orders = set() # Set[HistoryEntry]
self.customer_id = customer_id
def record_order(self, order_id: str, order_amount: int): (1)
entry = HistoryEntry(order_id, order_amount)
if entry in self.orders:
return
self.orders.add(entry)
if len(self.orders) == 3:
self.events.append(
CustomerBecameVIP(self.customer_id)
)
def create_order_from_basket(uow, cmd: CreateOrder): (2)
with uow:
order = Order.from_basket(cmd.customer_id, cmd.basket_items)
uow.orders.add(order)
uow.commit() # raises OrderCreated
def update_customer_history(uow, event: OrderCreated): (3)
with uow:
history = uow.order_history.get(event.customer_id)
history.record_order(event.order_id, event.order_amount)
uow.commit() # raises CustomerBecameVIP
def congratulate_vip_customer(uow, event: CustomerBecameVip): (4)
with uow:
customer = uow.customers.get(event.customer_id)
email.send(
customer.email_address,
f'Congratulations {customer.first_name}!'
)| 1 | L’agrégat History capture les règles indiquant quand un client devient VIP. Cela nous place dans une bonne position pour gérer les changements lorsque les règles deviennent plus complexes à l’avenir. |
| 2 | Notre premier gestionnaire crée une commande pour le client et déclenche un événement de domaine OrderCreated. |
| 3 | Notre deuxième gestionnaire met à jour l’objet History pour enregistrer qu’une commande a été créée. |
| 4 | Enfin, nous envoyons un email au client lorsqu’il devient VIP. |
En utilisant ce code, nous pouvons obtenir une certaine intuition sur la gestion des erreurs dans un système piloté par les événements.
Dans notre implémentation actuelle, nous déclenchons des événements sur un agrégat après avoir persisté notre état dans la base de données. Et si nous déclenchions ces événements avant de persister, et validions tous nos changements en même temps ? De cette façon, nous pourrions être sûrs que tout le travail est terminé. Ne serait-ce pas plus sûr ?
Que se passe-t-il cependant si le serveur de messagerie est légèrement surchargé ? Si tout le travail doit se terminer en même temps, un serveur de messagerie occupé peut nous empêcher de prendre l’argent pour les commandes.
Que se passe-t-il s’il y a un bug dans l’implémentation de l’agrégat History ? Devrions-nous échouer à prendre votre argent juste parce que nous ne pouvons pas vous reconnaître comme VIP ?
En séparant ces préoccupations, nous avons rendu possible que les choses échouent en isolation, ce qui améliore la fiabilité globale du système. La seule partie de ce code qui doit se terminer est le gestionnaire de commande qui crée une commande. C’est la seule partie qui intéresse un client, et c’est la partie que nos parties prenantes métier devraient prioriser.
Notez comment nous avons délibérément aligné nos limites transactionnelles au début et à la fin des processus métier. Les noms que nous utilisons dans le code correspondent au jargon utilisé par nos parties prenantes métier, et les gestionnaires que nous avons écrits correspondent aux étapes de nos critères d’acceptation en langage naturel. Cette concordance de noms et de structure nous aide à raisonner sur nos systèmes à mesure qu’ils deviennent plus grands et plus complexes.
10.4. Récupération d’Erreurs de Manière Synchrone
Nous espérons vous avoir convaincu qu’il est acceptable que les événements échouent indépendamment des commandes qui les ont déclenchés. Que devrions-nous faire alors pour nous assurer que nous pouvons récupérer des erreurs lorsqu’elles se produisent inévitablement ?
La première chose dont nous avons besoin est de savoir quand une erreur s’est produite, et pour cela nous nous fions généralement aux journaux (logs).
Regardons à nouveau la méthode handle_event de notre bus de messages :
def handle_event(
event: events.Event,
queue: List[Message],
uow: unit_of_work.AbstractUnitOfWork,
):
for handler in EVENT_HANDLERS[type(event)]:
try:
logger.debug("handling event %s with handler %s", event, handler)
handler(event, uow=uow)
queue.extend(uow.collect_new_events())
except Exception:
logger.exception("Exception handling event %s", event)
continueLorsque nous gérons un message dans notre système, la première chose que nous faisons est d’écrire une ligne de journal pour enregistrer ce que nous sommes sur le point de faire. Pour notre cas d’usage CustomerBecameVIP, les journaux pourraient se lire comme suit :
Handling event CustomerBecameVIP(customer_id=12345) with handler <function congratulate_vip_customer at 0x10ebc9a60>
Parce que nous avons choisi d’utiliser des dataclasses pour nos types de messages, nous obtenons un résumé joliment imprimé des données entrantes que nous pouvons copier et coller dans un shell Python pour recréer l’objet.
Lorsqu’une erreur se produit, nous pouvons utiliser les données journalisées soit pour reproduire le problème dans un test unitaire, soit pour rejouer le message dans le système.
La relecture manuelle fonctionne bien pour les cas où nous devons corriger un bug avant de pouvoir retraiter un événement, mais nos systèmes connaîtront toujours un certain niveau de fond d’échec transitoire. Cela inclut des choses comme les problèmes de réseau, les verrous de table et les courtes périodes d’indisponibilité causées par les déploiements.
Pour la plupart de ces cas, nous pouvons récupérer élégamment en réessayant. Comme dit le proverbe : "Si au début vous ne réussissez pas, réessayez l’opération avec une période d’attente exponentiellement croissante."
from tenacity import Retrying, RetryError, stop_after_attempt, wait_exponential (1)
...
def handle_event(
event: events.Event,
queue: List[Message],
uow: unit_of_work.AbstractUnitOfWork,
):
for handler in EVENT_HANDLERS[type(event)]:
try:
for attempt in Retrying( (2)
stop=stop_after_attempt(3),
wait=wait_exponential()
):
with attempt:
logger.debug("handling event %s with handler %s", event, handler)
handler(event, uow=uow)
queue.extend(uow.collect_new_events())
except RetryError as retry_failure:
logger.error(
"Failed to handle event %s times, giving up!",
retry_failure.last_attempt.attempt_number
)
continue| 1 | Tenacity est une bibliothèque Python qui implémente des patterns communs pour réessayer. |
| 2 | Ici, nous configurons notre bus de messages pour réessayer les opérations jusqu’à trois fois, avec une attente exponentiellement croissante entre les tentatives. |
Réessayer les opérations qui pourraient échouer est probablement le meilleur moyen d’améliorer la résilience de notre logiciel. Encore une fois, les patterns Unité de Travail (Unit of Work) et Gestionnaire de Commande (Command Handler) signifient que chaque tentative démarre d’un état cohérent et ne laissera pas les choses à moitié finies.
À un certain moment, indépendamment de tenacity, nous devrons abandonner l’essai de traitement du message. Construire des systèmes fiables avec des messages distribués est difficile, et nous devons survoler certains aspects délicats. Il y a des pointeurs vers plus de matériaux de référence dans l'épilogue.
|
10.5. Récapitulatif
Dans ce livre, nous avons décidé d’introduire le concept d’événements avant le concept de commandes, mais d’autres guides le font souvent dans l’autre sens. Rendre explicites les requêtes auxquelles notre système peut répondre en leur donnant un nom et leur propre structure de données est une chose assez fondamentale à faire. Vous verrez parfois des gens utiliser le nom Command Handler pattern pour décrire ce que nous faisons avec les Événements (Events), les Commandes (Commands) et le Bus de Messages (Message Bus).
Séparation des commandes et des événements : les compromis discute certaines des choses auxquelles vous devriez penser avant de vous lancer.
| Avantages | Inconvénients |
|---|---|
|
|
Dans Architecture Orientée Événements : Utilisation des Événements pour Intégrer des Microservices nous parlerons de l’utilisation des événements comme pattern d’intégration (integration).
11. Architecture Orientée Événements : Utilisation des Événements pour Intégrer des Microservices
Dans le chapitre précédent, nous n’avons jamais réellement parlé de comment nous recevrions les événements "quantité de lot modifiée", ni d’ailleurs comment nous pourrions notifier le monde extérieur des réallocations.
Nous avons un microservice avec une API web, mais qu’en est-il d’autres façons de parler à d’autres systèmes ? Comment saurons-nous si, disons, une expédition est retardée ou si la quantité est modifiée ? Comment dirons-nous au système d’entrepôt qu’une commande a été allouée et doit être envoyée à un client ?
Dans ce chapitre, nous aimerions montrer comment la métaphore des événements peut être étendue pour englober la façon dont nous gérons les messages entrants et sortants du système. En interne, le cœur de notre application est maintenant un processeur de messages. Suivons cette logique pour qu’elle devienne également un processeur de messages en externe. Comme montré dans Notre application est un processeur de messages, notre application recevra des événements de sources externes via un bus de messages externe (nous utiliserons les files d’attente Redis pub/sub comme exemple) et publiera ses sorties, sous forme d’événements, de retour là aussi.
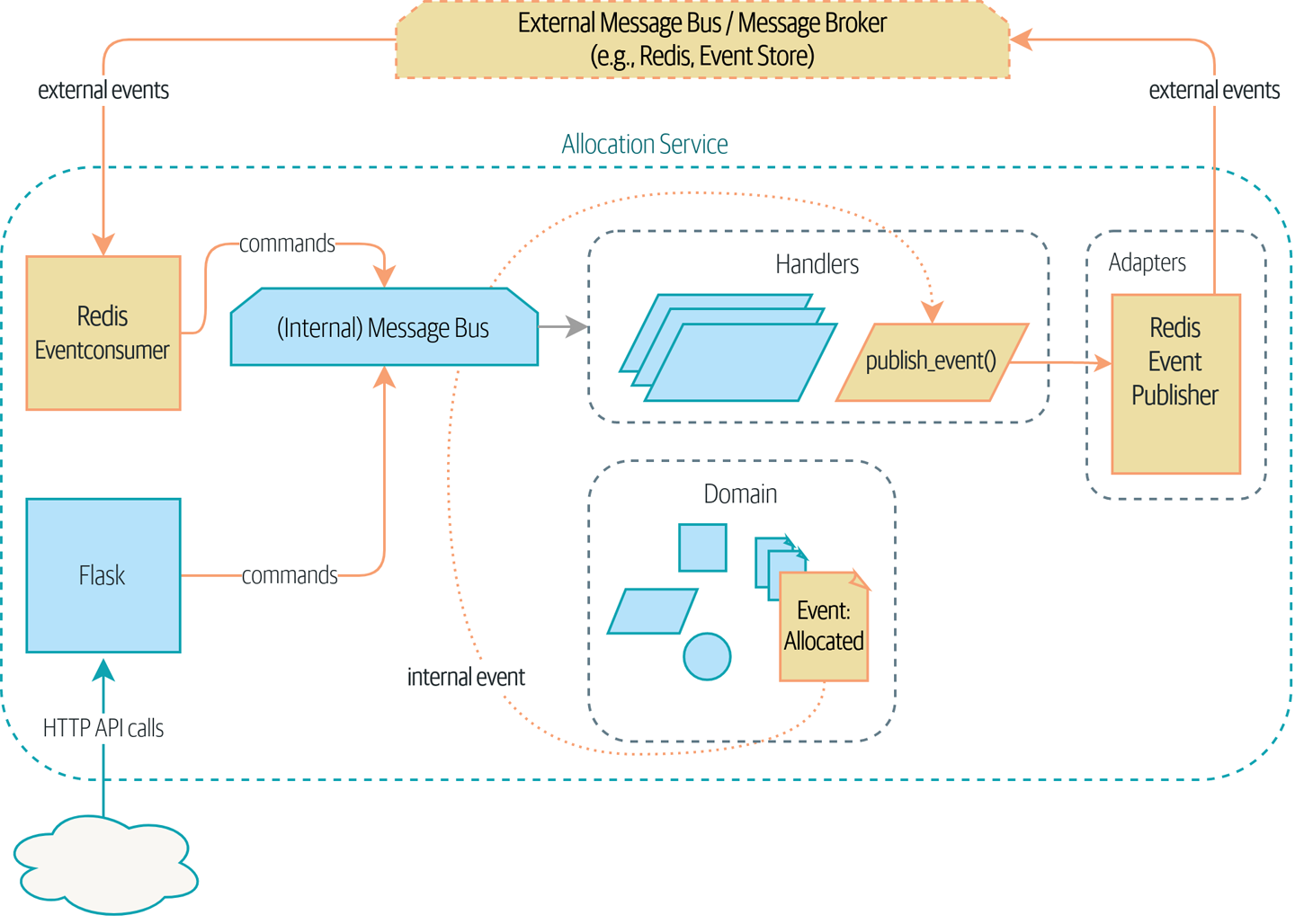
|
Le code de ce chapitre se trouve dans la branche chapter_11_external_events sur GitHub : git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_11_external_events # ou pour suivre, récupérez le chapitre précédent : git checkout chapter_10_commands |
11.1. Boule de Boue Distribuée, et Penser en Noms
Avant d’entrer dans le vif du sujet, parlons des alternatives. Nous parlons régulièrement à des ingénieurs qui essaient de construire une architecture de microservices. Souvent, ils migrent depuis une application existante, et leur premier instinct est de diviser leur système en noms.
Quels noms avons-nous introduits jusqu’à présent dans notre système ? Eh bien, nous avons des lots de stock, des commandes, des produits et des clients. Donc une tentative naïve de diviser le système aurait pu ressembler à Diagramme de contexte avec des services basés sur des noms (notez que nous avons nommé notre système d’après un nom, Batches, au lieu d'Allocation).
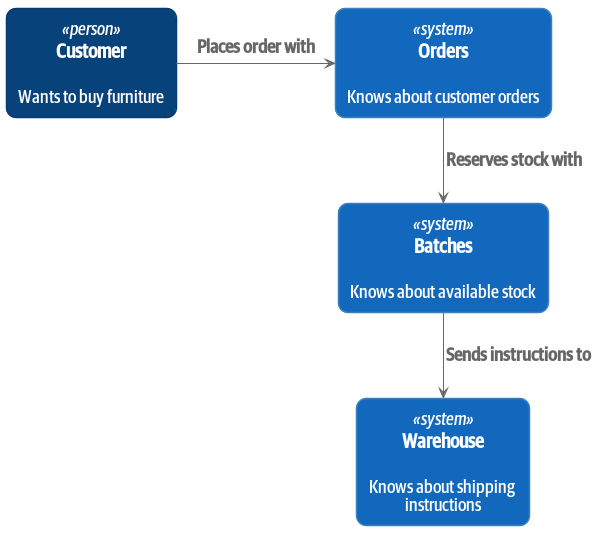
[plantuml, apwp_1102, config=plantuml.cfg] @startuml Batches Context Diagram !include images/C4_Context.puml System(batches, "Batches", "Knows about available stock") Person(customer, "Customer", "Wants to buy furniture") System(orders, "Orders", "Knows about customer orders") System(warehouse, "Warehouse", "Knows about shipping instructions") Rel_R(customer, orders, "Places order with") Rel_D(orders, batches, "Reserves stock with") Rel_D(batches, warehouse, "Sends instructions to") @enduml
Chaque "chose" dans notre système a un service associé, qui expose une API HTTP.
Parcourons un exemple de flux de chemin heureux dans Flux de commandes 1 : nos utilisateurs visitent un site web et peuvent choisir parmi des produits en stock. Lorsqu’ils ajoutent un article à leur panier, nous réserverons du stock pour eux. Lorsqu’une commande est complète, nous confirmons la réservation, ce qui nous amène à envoyer des instructions d’expédition à l’entrepôt. Disons également que si c’est la troisième commande du client, nous voulons mettre à jour le dossier client pour les marquer comme VIP.
[plantuml, apwp_1103, config=plantuml.cfg] @startuml scale 4 actor Customer entity Orders entity Batches entity Warehouse database CRM == Reservation == Customer -> Orders: Add product to basket Orders -> Batches: Reserve stock == Purchase == Customer -> Orders: Place order activate Orders Orders -> Batches: Confirm reservation Batches -> Warehouse: Dispatch goods Orders -> CRM: Update customer record deactivate Orders @enduml
Nous pouvons considérer chacune de ces étapes comme une commande (command) dans notre système : ReserveStock, ConfirmReservation, DispatchGoods, MakeCustomerVIP, etc.
Ce style d’architecture, où nous créons un microservice par table de base de données et traitons nos API HTTP comme des interfaces CRUD pour des modèles anémiques, est la façon initiale la plus courante pour les gens d’aborder la conception orientée services.
Cela fonctionne correctement pour les systèmes très simples, mais cela peut rapidement se dégrader en une boule de boue distribuée.
Pour voir pourquoi, considérons un autre cas. Parfois, lorsque le stock arrive à l’entrepôt, nous découvrons que des articles ont été endommagés par l’eau pendant le transit. Nous ne pouvons pas vendre des canapés endommagés par l’eau, donc nous devons les jeter et demander plus de stock à nos partenaires. Nous devons également mettre à jour notre modèle de stock, et cela pourrait signifier que nous devons réallouer la commande d’un client.
Où va cette logique ?
Eh bien, le système Warehouse sait que le stock a été endommagé, donc peut-être devrait-il posséder ce processus, comme montré dans Flux de commandes 2.
[plantuml, apwp_1104, config=plantuml.cfg] @startuml scale 4 actor w as "Warehouse worker" entity Warehouse entity Batches entity Orders database CRM w -> Warehouse: Report stock damage activate Warehouse Warehouse -> Batches: Decrease available stock Batches -> Batches: Reallocate orders Batches -> Orders: Update order status Orders -> CRM: Update order history deactivate Warehouse @enduml
Cela fonctionne également en quelque sorte, mais maintenant notre graphe de dépendances est un désordre. Pour allouer du stock, le service Orders pilote le système Batches, qui pilote Warehouse ; mais pour gérer les problèmes à l’entrepôt, notre système Warehouse pilote Batches, qui pilote Orders.
Multipliez cela par tous les autres flux de travail que nous devons fournir, et vous pouvez voir comment les services s’emmêlent rapidement.
11.2. Gestion des Erreurs dans les Systèmes Distribués
"Les choses cassent" est une loi universelle de l’ingénierie logicielle. Que se passe-t-il dans notre système lorsque l’une de nos requêtes échoue ? Disons qu’une erreur réseau se produit juste après que nous ayons pris la commande d’un utilisateur pour trois MISBEGOTTEN-RUG, comme montré dans Flux de commandes avec erreur.
Nous avons deux options ici : nous pouvons passer la commande de toute façon et la laisser non allouée, ou nous pouvons refuser de prendre la commande car l’allocation ne peut pas être garantie. L’état d’échec de notre service de lots a fait surface et affecte la fiabilité de notre service de commandes.
Lorsque deux choses doivent être modifiées ensemble, nous disons qu’elles sont couplées. Nous pouvons considérer cette cascade d’échecs comme une sorte de couplage temporel (temporal coupling) : chaque partie du système doit fonctionner en même temps pour qu’une partie quelconque fonctionne. À mesure que le système grandit, il y a une probabilité exponentiellement croissante qu’une partie soit dégradée.
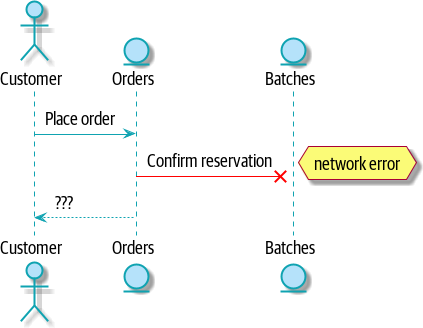
[plantuml, apwp_1105, config=plantuml.cfg] @startuml scale 4 actor Customer entity Orders entity Batches Customer -> Orders: Place order Orders -[#red]x Batches: Confirm reservation hnote right: network error Orders --> Customer: ??? @enduml
11.3. L’Alternative : Découplage Temporel Utilisant la Messagerie Asynchrone
Comment obtenir un couplage approprié ? Nous avons déjà vu une partie de la réponse, qui est que nous devrions penser en termes de verbes, pas de noms. Notre modèle de domaine consiste à modéliser un processus métier. Ce n’est pas un modèle de données statique sur une chose ; c’est un modèle d’un verbe.
Donc au lieu de penser à un système pour les commandes et un système pour les lots, nous pensons à un système pour commander et un système pour allouer, etc.
Lorsque nous séparons les choses de cette façon, il est un peu plus facile de voir quel système devrait être responsable de quoi. Lorsque nous pensons à commander, vraiment nous voulons nous assurer que lorsque nous passons une commande, la commande est passée. Tout le reste peut arriver plus tard, tant que cela arrive.
| Si cela vous semble familier, c’est normal ! Séparer les responsabilités est le même processus que nous avons suivi lors de la conception de nos agrégats (aggregates) et commandes (commands). |
Comme les agrégats, les microservices devraient être des limites de cohérence (consistency boundaries). Entre deux services, nous pouvons accepter la cohérence éventuelle, et cela signifie que nous n’avons pas besoin de nous appuyer sur des appels synchrones. Chaque service accepte des commandes (commands) du monde extérieur et déclenche des événements (events) pour enregistrer le résultat. D’autres services peuvent écouter ces événements pour déclencher les étapes suivantes dans le flux de travail.
Pour éviter l’anti-pattern de Boule de Boue Distribuée, au lieu d’appels d’API HTTP couplés temporellement, nous voulons utiliser la messagerie asynchrone pour intégrer nos systèmes. Nous voulons que nos messages BatchQuantityChanged arrivent comme messages externes depuis les systèmes en amont, et nous voulons que notre système publie des événements Allocated pour que les systèmes en aval les écoutent.
Pourquoi est-ce mieux ? Premièrement, parce que les choses peuvent échouer indépendamment, il est plus facile de gérer un comportement dégradé : nous pouvons toujours prendre des commandes si le système d’allocation a une mauvaise journée.
Deuxièmement, nous réduisons la force du couplage entre nos systèmes. Si nous devons changer l’ordre des opérations ou introduire de nouvelles étapes dans le processus, nous pouvons le faire localement.
11.4. Utilisation d’un Canal Redis Pub/Sub pour l’Intégration (Integration)
Voyons comment tout cela fonctionnera concrètement. Nous aurons besoin d’un moyen de faire sortir les événements d’un système et de les faire entrer dans un autre, comme notre bus de messages, mais pour les services. Cette infrastructure est souvent appelée un courtier de messages (message broker). Le rôle d’un courtier de messages est de prendre des messages des éditeurs et de les livrer aux abonnés.
Chez MADE.com, nous utilisons Event Store ; Kafka ou RabbitMQ sont des alternatives valides. Une solution légère basée sur les canaux pub/sub Redis peut également très bien fonctionner, et parce que Redis est beaucoup plus généralement familier aux gens, nous avons pensé l’utiliser pour ce livre.
| Nous passons sur la complexité impliquée dans le choix de la bonne plateforme de messagerie. Des préoccupations comme l’ordre des messages, la gestion des échecs et l’idempotence doivent toutes être réfléchies. Pour quelques pointeurs, voir Pièges. |
Notre nouveau flux ressemblera à Diagramme de séquence pour le flux de réallocation : Redis fournit l’événement BatchQuantityChanged qui lance tout le processus, et notre événement Allocated est publié de retour vers Redis à la fin.
[plantuml, apwp_1106, config=plantuml.cfg]
@startuml
scale 4
Redis -> MessageBus : BatchQuantityChanged event
group BatchQuantityChanged Handler + Unit of Work 1
MessageBus -> Domain_Model : change batch quantity
Domain_Model -> MessageBus : emit Allocate command(s)
end
group Allocate Handler + Unit of Work 2 (or more)
MessageBus -> Domain_Model : allocate
Domain_Model -> MessageBus : emit Allocated event(s)
end
MessageBus -> Redis : publish to line_allocated channel
@enduml
11.5. Développement Guidé par les Tests avec un Test de Bout en Bout
Voici comment nous pourrions commencer avec un test de bout en bout. Nous pouvons utiliser notre API existante pour créer des lots, puis nous testerons les messages entrants et sortants :
def test_change_batch_quantity_leading_to_reallocation():
# commencer avec deux lots et une commande allouée à l'un d'eux (1)
orderid, sku = random_orderid(), random_sku()
earlier_batch, later_batch = random_batchref("old"), random_batchref("newer")
api_client.post_to_add_batch(earlier_batch, sku, qty=10, eta="2011-01-01") (2)
api_client.post_to_add_batch(later_batch, sku, qty=10, eta="2011-01-02")
response = api_client.post_to_allocate(orderid, sku, 10) (2)
assert response.json()["batchref"] == earlier_batch
subscription = redis_client.subscribe_to("line_allocated") (3)
# changer la quantité sur le lot alloué pour qu'elle soit inférieure à notre commande (1)
redis_client.publish_message( (3)
"change_batch_quantity",
{"batchref": earlier_batch, "qty": 5},
)
# attendre jusqu'à ce que nous voyions un message disant que la commande a été réallouée (1)
messages = []
for attempt in Retrying(stop=stop_after_delay(3), reraise=True): (4)
with attempt:
message = subscription.get_message(timeout=1)
if message:
messages.append(message)
print(messages)
data = json.loads(messages[-1]["data"])
assert data["orderid"] == orderid
assert data["batchref"] == later_batch| 1 | Vous pouvez lire l’histoire de ce qui se passe dans ce test à partir des commentaires : nous voulons envoyer un événement dans le système qui cause la réallocation d’une ligne de commande, et nous voyons cette réallocation sortir comme un événement dans Redis également. |
| 2 | api_client est un petit helper que nous avons refactorisé pour partager entre nos deux types de tests ; il enveloppe nos appels à requests.post. |
| 3 | redis_client est un autre petit helper de test, dont les détails n’ont pas vraiment d’importance ; son travail est de pouvoir envoyer et recevoir des messages de divers canaux Redis. Nous utiliserons un canal appelé change_batch_quantity pour envoyer notre demande de changement de quantité pour un lot, et nous écouterons un autre canal appelé line_allocated pour surveiller la réallocation attendue. |
| 4 | En raison de la nature asynchrone du système testé, nous devons utiliser à nouveau la bibliothèque tenacity pour ajouter une boucle de réessai — premièrement, parce qu’il peut prendre un certain temps pour que notre nouveau message line_allocated arrive, mais aussi parce que ce ne sera pas le seul message sur ce canal. |
11.5.1. Redis Est un Autre Adaptateur Mince Autour de Notre Bus de Messages
Notre écouteur Redis pub/sub (nous l’appelons un consommateur d’événements) ressemble beaucoup à Flask : il traduit du monde extérieur vers nos événements :
r = redis.Redis(**config.get_redis_host_and_port())
def main():
orm.start_mappers()
pubsub = r.pubsub(ignore_subscribe_messages=True)
pubsub.subscribe("change_batch_quantity") (1)
for m in pubsub.listen():
handle_change_batch_quantity(m)
def handle_change_batch_quantity(m):
logging.debug("handling %s", m)
data = json.loads(m["data"]) (2)
cmd = commands.ChangeBatchQuantity(ref=data["batchref"], qty=data["qty"]) (2)
messagebus.handle(cmd, uow=unit_of_work.SqlAlchemyUnitOfWork())| 1 | main() nous abonne au canal change_batch_quantity au chargement. |
| 2 | Notre travail principal en tant que point d’entrée au système est de désérialiser le JSON, le convertir en une Command, et le passer à la couche de service — tout comme l’adaptateur Flask le fait. |
Nous construisons également un nouvel adaptateur en aval pour faire le travail opposé — convertir les événements de domaine (domain events) en événements publics :
r = redis.Redis(**config.get_redis_host_and_port())
def publish(channel, event: events.Event): (1)
logging.debug("publishing: channel=%s, event=%s", channel, event)
r.publish(channel, json.dumps(asdict(event)))| 1 | Nous prenons un canal codé en dur ici, mais vous pourriez également stocker un mappage entre les classes/noms d’événements et le canal approprié, permettant à un ou plusieurs types de messages d’aller vers différents canaux. |
11.5.2. Notre Nouvel Événement Sortant
Voici à quoi ressemblera l’événement Allocated :
@dataclass
class Allocated(Event):
orderid: str
sku: str
qty: int
batchref: strIl capture tout ce que nous devons savoir sur une allocation : les détails de la ligne de commande, et à quel lot elle a été allouée.
Nous l’ajoutons dans la méthode allocate() de notre modèle (après avoir ajouté un test d’abord, naturellement) :
class Product:
...
def allocate(self, line: OrderLine) -> str:
...
batch.allocate(line)
self.version_number += 1
self.events.append(
events.Allocated(
orderid=line.orderid,
sku=line.sku,
qty=line.qty,
batchref=batch.reference,
)
)
return batch.reference
Le gestionnaire (handler) pour ChangeBatchQuantity existe déjà, donc tout ce que nous devons ajouter est un gestionnaire qui publie l’événement sortant :
HANDLERS = {
events.Allocated: [handlers.publish_allocated_event],
events.OutOfStock: [handlers.send_out_of_stock_notification],
} # type: Dict[Type[events.Event], List[Callable]]La publication de l’événement utilise notre fonction helper du wrapper Redis :
def publish_allocated_event(
event: events.Allocated,
uow: unit_of_work.AbstractUnitOfWork,
):
redis_eventpublisher.publish("line_allocated", event)11.6. Événements Internes Versus Externes
C’est une bonne idée de garder claire la distinction entre événements internes et externes. Certains événements peuvent venir de l’extérieur, et certains événements peuvent être améliorés et publiés en externe, mais pas tous. C’est particulièrement important si vous vous lancez dans l’event sourcing (très certainement un sujet pour un autre livre, cependant).
| Les événements sortants sont l’un des endroits où il est important d’appliquer la validation. Voir Validation pour quelques philosophies et exemples de validation. |
11.7. Récapitulatif
Les événements (events) peuvent venir de l’extérieur, mais ils peuvent également être publiés en externe — notre gestionnaire (handler) publish convertit un événement en un message sur un canal Redis. Nous utilisons des événements pour parler au monde extérieur. Ce type de découplage temporel nous achète beaucoup de flexibilité dans nos intégrations d’applications, mais comme toujours, cela a un coût.
La notification par événement est agréable car elle implique un faible niveau de couplage, et est assez simple à mettre en place. Elle peut devenir problématique, cependant, s'il existe réellement un flux logique qui s'étend sur diverses notifications d'événements...Il peut être difficile de voir un tel flux car il n'est explicite dans aucun texte de programme....Cela peut rendre le débogage et la modification difficiles.
Martin Fowler, "What do you mean by 'Event-Driven'"
Intégration de microservices basée sur les événements : les compromis montre quelques compromis à considérer.
| Avantages | Inconvénients |
|---|---|
|
|
Plus généralement, si vous passez d’un modèle de messagerie synchrone à un modèle asynchrone, vous ouvrez également toute une série de problèmes liés à la fiabilité des messages et à la cohérence éventuelle. Lisez la suite dans Pièges.
12. CQRS (Command Query Responsibility Segregation/Ségrégation des Responsabilités Commande-Requête)
Dans ce chapitre, nous allons commencer par une intuition assez peu controversée : les lectures (requêtes) et les écritures (commandes) sont différentes, donc elles devraient être traitées différemment (ou avoir leurs responsabilités séparées, si vous préférez). Ensuite, nous allons pousser cette intuition aussi loin que possible.
Si vous êtes comme Harry, tout cela semblera extrême au début, mais espérons que nous pourrons argumenter que ce n’est pas totalement déraisonnable.
Séparer les lectures des écritures montre où nous pourrions finir.
|
Le code pour ce chapitre se trouve dans la branche chapter_12_cqrs sur GitHub. git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_12_cqrs # or to code along, checkout the previous chapter: git checkout chapter_11_external_events |
Mais d’abord, pourquoi se donner cette peine ?
12.1. Les Modèles de Domaine Sont Pour l’Écriture
Nous avons passé beaucoup de temps dans ce livre à parler de comment construire des logiciels qui appliquent les règles de notre domaine. Ces règles, ou contraintes, seront différentes pour chaque application, et elles constituent le cœur intéressant de nos systèmes.
Dans ce livre, nous avons défini des contraintes explicites comme "Vous ne pouvez pas allouer plus de stock qu’il n’y en a de disponible," ainsi que des contraintes implicites comme "Chaque ligne de commande est allouée à un seul batch."
Nous avons écrit ces règles sous forme de tests unitaires au début du livre :
def test_allocating_to_a_batch_reduces_the_available_quantity():
batch = Batch("batch-001", "SMALL-TABLE", qty=20, eta=date.today())
line = OrderLine("order-ref", "SMALL-TABLE", 2)
batch.allocate(line)
assert batch.available_quantity == 18
...
def test_cannot_allocate_if_available_smaller_than_required():
small_batch, large_line = make_batch_and_line("ELEGANT-LAMP", 2, 20)
assert small_batch.can_allocate(large_line) is FalsePour appliquer ces règles correctement, nous devions nous assurer que les opérations étaient cohérentes, et donc nous avons introduit des patterns comme Unit of Work et Aggregate qui nous aident à valider de petits morceaux de travail.
Pour communiquer les changements entre ces petits morceaux, nous avons introduit le pattern Domain Events pour pouvoir écrire des règles comme "Quand du stock est endommagé ou perdu, ajuster la quantité disponible sur le batch, et réallouer les commandes si nécessaire."
Toute cette complexité existe pour que nous puissions appliquer des règles quand nous changeons l' état de notre système. Nous avons construit un ensemble flexible d’outils pour écrire des données.
Mais qu’en est-il des lectures ?
12.2. La Plupart des Utilisateurs ne Vont pas Acheter vos Meubles
Chez MADE.com, nous avons un système très similaire au service d’allocation. Dans une journée chargée, nous pourrions traiter cent commandes en une heure, et nous avons un gros système complexe pour allouer du stock à ces commandes.
Mais dans cette même journée chargée, nous pourrions avoir cent vues de produit par seconde. Chaque fois que quelqu’un visite une page produit, ou une page de liste de produits, nous devons déterminer si le produit est toujours en stock et combien de temps il nous faudra pour le livrer.
Le domaine est le même—nous nous préoccupons des batchs de stock, et de leur date d’arrivée, et de la quantité qui est encore disponible—mais le pattern d’accès est très différent. Par exemple, nos clients ne remarqueront pas si la requête est en retard de quelques secondes, mais si notre service d’allocation est incohérent, nous allons faire un gâchis de leurs commandes. Nous pouvons profiter de cette différence en rendant nos lectures finalement cohérentes afin de les rendre plus performantes.
Nous pouvons considérer ces exigences comme formant deux moitiés d’un système : le côté lecture et le côté écriture, montré dans Lecture versus écriture.
Pour le côté écriture, nos patterns architecturaux de domaine sophistiqués nous aident à faire évoluer notre système au fil du temps, mais la complexité que nous avons construite jusqu’à présent n’apporte rien pour la lecture des données. La couche de service, l’unité de travail, et le modèle de domaine astucieux ne sont que du ballast.
| Côté Lecture | Côté Écriture | |
|---|---|---|
Comportement |
Lecture simple |
Logique métier complexe |
Mise en cache |
Hautement cacheable |
Non cacheable |
Cohérence |
Peut être périmé |
Doit être transactionnellement cohérent |
12.3. Post/Redirect/Get et CQS
Si vous faites du développement web, vous connaissez probablement le pattern Post/Redirect/Get. Dans cette technique, un endpoint web accepte un POST HTTP et répond avec une redirection pour voir le résultat. Par exemple, nous pourrions accepter un POST vers /batches pour créer un nouveau batch et rediriger l’utilisateur vers /batches/123 pour voir leur batch nouvellement créé.
Cette approche résout les problèmes qui surviennent quand les utilisateurs rafraîchissent la page de résultats dans leur navigateur ou essaient de mettre en signet une page de résultats. Dans le cas d’un rafraîchissement, cela peut conduire à ce que nos utilisateurs soumettent deux fois les données et donc achètent deux canapés quand ils n’en avaient besoin que d’un. Dans le cas d’un signet, nos clients malheureux finiront avec une page cassée quand ils essaieront de faire un GET sur un endpoint POST.
Ces deux problèmes surviennent parce que nous retournons des données en réponse à une opération d' écriture. Post/Redirect/Get contourne le problème en séparant les phases de lecture et d' écriture de notre opération.
Cette technique est un exemple simple de séparation commande-requête (CQS).[31] Nous suivons une règle simple : les fonctions doivent soit modifier l’état soit répondre à des questions, mais jamais les deux. Cela rend le logiciel plus facile à raisonner : nous devrions toujours être capables de demander "Les lumières sont-elles allumées ?" sans actionner l’interrupteur.
| Lors de la construction d’APIs, nous pouvons appliquer la même technique de conception en retournant un 201 Created, ou un 202 Accepted, avec un en-tête Location contenant l’URI de nos nouvelles ressources. Ce qui est important ici n’est pas le code de statut que nous utilisons mais la séparation logique du travail en une phase d’écriture et une phase de requête. |
Comme vous le verrez, nous pouvons utiliser le principe CQS pour rendre nos systèmes plus rapides et plus
scalables, mais d’abord, corrigeons la violation de CQS dans notre code existant. Il y a longtemps,
nous avons introduit un endpoint allocate qui prend une commande et appelle notre
couche de service pour allouer du stock. À la fin de l’appel, nous retournons un 200
OK et l’ID du batch. Cela a conduit à des défauts de conception laids pour que nous puissions obtenir
les données dont nous avons besoin. Changeons-le pour retourner un simple message OK et à la place
fournir un nouveau endpoint en lecture seule pour récupérer l’état d’allocation :
@pytest.mark.usefixtures("postgres_db")
@pytest.mark.usefixtures("restart_api")
def test_happy_path_returns_202_and_batch_is_allocated():
orderid = random_orderid()
sku, othersku = random_sku(), random_sku("other")
earlybatch = random_batchref(1)
laterbatch = random_batchref(2)
otherbatch = random_batchref(3)
api_client.post_to_add_batch(laterbatch, sku, 100, "2011-01-02")
api_client.post_to_add_batch(earlybatch, sku, 100, "2011-01-01")
api_client.post_to_add_batch(otherbatch, othersku, 100, None)
r = api_client.post_to_allocate(orderid, sku, qty=3)
assert r.status_code == 202
r = api_client.get_allocation(orderid)
assert r.ok
assert r.json() == [
{"sku": sku, "batchref": earlybatch},
]
@pytest.mark.usefixtures("postgres_db")
@pytest.mark.usefixtures("restart_api")
def test_unhappy_path_returns_400_and_error_message():
unknown_sku, orderid = random_sku(), random_orderid()
r = api_client.post_to_allocate(
orderid, unknown_sku, qty=20, expect_success=False
)
assert r.status_code == 400
assert r.json()["message"] == f"Invalid sku {unknown_sku}"
r = api_client.get_allocation(orderid)
assert r.status_code == 404OK, à quoi pourrait ressembler l’application Flask ?
from allocation import views
...
@app.route("/allocations/<orderid>", methods=["GET"])
def allocations_view_endpoint(orderid):
uow = unit_of_work.SqlAlchemyUnitOfWork()
result = views.allocations(orderid, uow) (1)
if not result:
return "not found", 404
return jsonify(result), 200| 1 | D’accord, un views.py, très bien ; nous pouvons garder les choses en lecture seule là-dedans, et ce sera un vrai views.py, pas comme celui de Django, quelque chose qui sait comment construire des vues en lecture seule de nos données… |
12.4. Accrochez-vous, Mesdames et Messieurs
Hmm, nous pouvons probablement juste ajouter une méthode list à notre objet repository existant :
from allocation.service_layer import unit_of_work
def allocations(orderid: str, uow: unit_of_work.SqlAlchemyUnitOfWork):
with uow:
results = uow.session.execute(
"""
SELECT ol.sku, b.reference
FROM allocations AS a
JOIN batches AS b ON a.batch_id = b.id
JOIN order_lines AS ol ON a.orderline_id = ol.id
WHERE ol.orderid = :orderid
""",
dict(orderid=orderid),
)
return [{"sku": sku, "batchref": batchref} for sku, batchref in results]Excusez-moi ? Du SQL brut ?
Si vous êtes comme Harry rencontrant ce pattern pour la première fois, vous vous demanderez ce que Bob a bien pu fumer. Nous faisons du SQL fait maison maintenant, et nous convertissons des lignes de base de données directement en dicts ? Après tous les efforts que nous avons mis à construire un beau modèle de domaine ? Et qu’en est-il du pattern Repository ? N’est-ce pas censé être notre abstraction autour de la base de données ? Pourquoi ne pas le réutiliser ?
Eh bien, explorons d’abord cette alternative apparemment plus simple, et voyons à quoi elle ressemble en pratique.
Nous garderons toujours notre vue dans un module views.py séparé ; appliquer une distinction claire entre les lectures et les écritures dans votre application est toujours une bonne idée. Nous appliquons la séparation commande-requête, et il est facile de voir quel code modifie l’état (les gestionnaires d’événements) et quel code récupère simplement l’état en lecture seule (les vues).
| Séparer vos vues en lecture seule de vos gestionnaires de commandes et d’événements qui modifient l’état est probablement une bonne idée, même si vous ne voulez pas aller jusqu’au CQRS complet. |
12.5. Tester les Vues CQRS
Avant de nous lancer dans l’exploration de diverses options, parlons des tests. Quelles que soient les approches que vous décidez d’adopter, vous allez probablement avoir besoin d’au moins un test d’intégration. Quelque chose comme ceci :
def test_allocations_view(sqlite_session_factory):
uow = unit_of_work.SqlAlchemyUnitOfWork(sqlite_session_factory)
messagebus.handle(commands.CreateBatch("sku1batch", "sku1", 50, None), uow) (1)
messagebus.handle(commands.CreateBatch("sku2batch", "sku2", 50, today), uow)
messagebus.handle(commands.Allocate("order1", "sku1", 20), uow)
messagebus.handle(commands.Allocate("order1", "sku2", 20), uow)
# add a spurious batch and order to make sure we're getting the right ones
messagebus.handle(commands.CreateBatch("sku1batch-later", "sku1", 50, today), uow)
messagebus.handle(commands.Allocate("otherorder", "sku1", 30), uow)
messagebus.handle(commands.Allocate("otherorder", "sku2", 10), uow)
assert views.allocations("order1", uow) == [
{"sku": "sku1", "batchref": "sku1batch"},
{"sku": "sku2", "batchref": "sku2batch"},
]| 1 | Nous faisons la configuration pour le test d’intégration en utilisant le point d’entrée public vers notre application, le bus de messages. Cela garde nos tests découplés de tous les détails d’implémentation/infrastructure sur la façon dont les choses sont stockées. |
12.6. Alternative "Évidente" 1 : Utiliser le Repository Existant
Que diriez-vous d’ajouter une méthode auxiliaire à notre repository products ?
from allocation import unit_of_work
def allocations(orderid: str, uow: unit_of_work.AbstractUnitOfWork):
with uow:
products = uow.products.for_order(orderid=orderid) (1)
batches = [b for p in products for b in p.batches] (2)
return [
{'sku': b.sku, 'batchref': b.reference}
for b in batches
if orderid in b.orderids (3)
]| 1 | Notre repository retourne des objets Product, et nous devons trouver tous les
produits pour les SKUs dans une commande donnée, donc nous allons construire une nouvelle méthode auxiliaire
appelée .for_order() sur le repository. |
| 2 | Maintenant nous avons des produits mais nous voulons en fait des références de batch, donc nous obtenons tous les batchs possibles avec une liste en compréhension. |
| 3 | Nous filtrons à nouveau pour obtenir juste les batchs pour notre commande
spécifique. Cela, à son tour, repose sur nos objets Batch étant capables de nous dire
quels IDs de commande il a alloués. |
Nous implémentons cela en dernier en utilisant une propriété .orderid :
class Batch:
...
@property
def orderids(self):
return {l.orderid for l in self._allocations}Vous pouvez commencer à voir que réutiliser nos classes de repository et de modèle de domaine existantes n’est pas aussi simple que vous auriez pu le supposer. Nous avons dû ajouter de nouvelles méthodes auxiliaires aux deux, et nous faisons beaucoup de boucles et de filtrage en Python, ce qui est un travail qui serait fait beaucoup plus efficacement par la base de données.
Donc oui, du côté positif nous réutilisons nos abstractions existantes, mais du côté négatif, tout cela semble assez maladroit.
12.7. Votre Modèle de Domaine n’est Pas Optimisé pour les Opérations de Lecture
Ce que nous voyons ici sont les effets d’avoir un modèle de domaine qui est conçu principalement pour les opérations d’écriture, alors que nos exigences pour les lectures sont souvent conceptuellement assez différentes.
C’est la justification philosophique du CQRS. Comme nous l’avons dit auparavant, un modèle de domaine n’est pas un modèle de données—nous essayons de capturer la façon dont l' entreprise fonctionne : workflow, règles autour des changements d’état, messages échangés ; préoccupations sur la façon dont le système réagit aux événements externes et aux entrées utilisateur. La plupart de ces choses sont totalement non pertinentes pour les opérations en lecture seule.
| Cette justification pour CQRS est liée à la justification pour le pattern de Modèle de Domaine. Si vous construisez une simple application CRUD, les lectures et les écritures vont être étroitement liées, donc vous n’avez pas besoin d’un modèle de domaine ou de CQRS. Mais plus votre domaine est complexe, plus vous avez de chances d’avoir besoin des deux. |
Pour faire un point facile, vos classes de domaine auront plusieurs méthodes pour modifier l’état, et vous n’en aurez besoin d’aucune pour les opérations en lecture seule.
Au fur et à mesure que la complexité de votre modèle de domaine grandit, vous vous trouverez à faire de plus en plus de choix sur la façon de structurer ce modèle, ce qui le rend de plus en plus maladroit à utiliser pour les opérations de lecture.
12.8. Alternative "Évidente" 2 : Utiliser l’ORM
Vous pensez peut-être, OK, si notre repository est maladroit, et travailler avec
Products est maladroit, alors je peux au moins utiliser mon ORM et travailler avec Batches.
C’est pour ça qu’il est fait !
from allocation import unit_of_work, model
def allocations(orderid: str, uow: unit_of_work.AbstractUnitOfWork):
with uow:
batches = uow.session.query(model.Batch).join(
model.OrderLine, model.Batch._allocations
).filter(
model.OrderLine.orderid == orderid
)
return [
{"sku": b.sku, "batchref": b.batchref}
for b in batches
]Mais est-ce que c’est vraiment plus facile à écrire ou à comprendre que la version SQL brut de l’exemple de code dans Accrochez-vous, Mesdames et Messieurs ? Ça ne semble peut-être pas si mal là-haut, mais nous pouvons vous dire que ça a pris plusieurs tentatives, et beaucoup de fouille dans la documentation SQLAlchemy. SQL est juste SQL.
Mais l’ORM peut aussi nous exposer à des problèmes de performance.
12.9. SELECT N+1 et Autres Considérations de Performance
Le problème dit SELECT N+1
est un problème de performance courant avec les ORMs : lors de la récupération d’une liste d'
objets, votre ORM effectuera souvent une requête initiale pour, disons, obtenir tous les IDs
des objets dont il a besoin, puis émettra des requêtes individuelles pour chaque objet pour
récupérer leurs attributs. C’est particulièrement probable s’il y a des relations de clé étrangère sur vos objets.
En toute équité, nous devons dire que SQLAlchemy est assez bon pour éviter
le problème SELECT N+1. Il ne le montre pas dans l’exemple précédent, et
vous pouvez demander le chargement anticipé (eager loading)
explicitement pour l’éviter quand vous traitez avec des objets joints.
|
Au-delà de SELECT N+1, vous pouvez avoir d’autres raisons de vouloir découpler la
façon dont vous persistez les changements d’état de la façon dont vous récupérez l’état actuel.
Un ensemble de tables relationnelles entièrement normalisées est un bon moyen de s’assurer que
les opérations d’écriture ne causent jamais de corruption de données. Mais récupérer des données en utilisant beaucoup
de jointures peut être lent. Il est courant dans de tels cas d’ajouter des vues dénormalisées,
construire des répliques en lecture, ou même ajouter des couches de cache.
12.10. Il est Temps de Sauter Complètement le Requin
Sur cette note : vous avons-nous convaincus que notre version SQL brut n’est pas si bizarre qu’elle ne le semblait au premier abord ? Peut-être exagérions-nous pour l’effet ? Attendez un peu.
Donc, raisonnable ou non, cette requête SQL codée en dur est plutôt laide, non ? Et si nous la rendions plus jolie…
def allocations(orderid: str, uow: unit_of_work.SqlAlchemyUnitOfWork):
with uow:
results = uow.session.execute(
"""
SELECT sku, batchref FROM allocations_view WHERE orderid = :orderid
""",
dict(orderid=orderid),
)
...…en gardant un magasin de données totalement séparé et dénormalisé pour notre modèle de vue ?
allocations_view = Table(
"allocations_view",
metadata,
Column("orderid", String(255)),
Column("sku", String(255)),
Column("batchref", String(255)),
)OK, des requêtes SQL plus jolies ne seraient pas une justification pour quoi que ce soit vraiment, mais construire une copie dénormalisée de vos données qui est optimisée pour les opérations de lecture n’est pas rare, une fois que vous avez atteint les limites de ce que vous pouvez faire avec des index.
Même avec des index bien réglés, une base de données relationnelle utilise beaucoup de CPU pour effectuer
des jointures. Les requêtes les plus rapides seront toujours SELECT * from mytable WHERE key = :value.
Plus que la vitesse brute, cette approche nous apporte de l’échelle. Quand nous écrivons des données dans une base de données relationnelle, nous devons nous assurer que nous obtenons un verrou sur les lignes que nous changeons pour ne pas rencontrer de problèmes de cohérence.
Si plusieurs clients changent des données en même temps, nous aurons d’étranges conditions de course (race conditions). Quand nous lisons des données, cependant, il n’y a pas de limite au nombre de clients qui peuvent s’exécuter simultanément. Pour cette raison, les magasins en lecture seule peuvent être mis à l’échelle horizontalement.
| Parce que les répliques en lecture peuvent être incohérentes, il n’y a pas de limite au nombre que nous pouvons avoir. Si vous avez du mal à mettre à l’échelle un système avec un magasin de données complexe, demandez-vous si vous pourriez construire un modèle de lecture plus simple. |
Garder le modèle de lecture à jour est le défi ! Les vues de base de données (matérialisées ou non) et les triggers sont une solution courante, mais cela vous limite à votre base de données. Nous aimerions vous montrer comment réutiliser notre architecture pilotée par les événements à la place.
12.10.1. Mettre à Jour une Table de Modèle de Lecture en Utilisant un Gestionnaire d’Événements
Nous ajoutons un second gestionnaire à l’événement Allocated :
EVENT_HANDLERS = {
events.Allocated: [
handlers.publish_allocated_event,
handlers.add_allocation_to_read_model,
],Voici à quoi ressemble notre code de mise à jour du modèle de vue :
def add_allocation_to_read_model(
event: events.Allocated,
uow: unit_of_work.SqlAlchemyUnitOfWork,
):
with uow:
uow.session.execute(
"""
INSERT INTO allocations_view (orderid, sku, batchref)
VALUES (:orderid, :sku, :batchref)
""",
dict(orderid=event.orderid, sku=event.sku, batchref=event.batchref),
)
uow.commit()Croyez-le ou non, cela fonctionnera à peu près ! Et cela fonctionnera contre les mêmes tests d’intégration que le reste de nos options.
OK, vous devrez aussi gérer Deallocated :
events.Deallocated: [
handlers.remove_allocation_from_read_model,
handlers.reallocate
],
...
def remove_allocation_from_read_model(
event: events.Deallocated,
uow: unit_of_work.SqlAlchemyUnitOfWork,
):
with uow:
uow.session.execute(
"""
DELETE FROM allocations_view
WHERE orderid = :orderid AND sku = :sku
...Diagramme de séquence pour le modèle de lecture montre le flux à travers les deux requêtes.
[plantuml, apwp_1202, config=plantuml.cfg]
@startuml
scale 4
!pragma teoz true
actor User order 1
boundary Flask order 2
participant MessageBus order 3
participant "Domain Model" as Domain order 4
participant View order 9
database DB order 10
User -> Flask: POST to allocate Endpoint
Flask -> MessageBus : Allocate Command
group UoW/transaction 1
MessageBus -> Domain : allocate()
MessageBus -> DB: commit write model
end
group UoW/transaction 2
Domain -> MessageBus : raise Allocated event(s)
MessageBus -> DB : update view model
end
Flask -> User: 202 OK
User -> Flask: GET allocations endpoint
Flask -> View: get allocations
View -> DB: SELECT on view model
DB -> View: some allocations
& View -> Flask: some allocations
& Flask -> User: some allocations
@enduml
Dans Diagramme de séquence pour le modèle de lecture, vous pouvez voir deux transactions dans l’opération POST/écriture, une pour mettre à jour le modèle d’écriture et une pour mettre à jour le modèle de lecture, que l’opération GET/lecture peut utiliser.
12.11. Changer Notre Implémentation de Modèle de Lecture est Facile
Voyons la flexibilité que notre modèle piloté par les événements nous apporte en action, en voyant ce qui se passe si nous décidons un jour de vouloir implémenter un modèle de lecture en utilisant un moteur de stockage totalement séparé, Redis.
Regardez simplement :
def add_allocation_to_read_model(event: events.Allocated, _):
redis_eventpublisher.update_readmodel(event.orderid, event.sku, event.batchref)
def remove_allocation_from_read_model(event: events.Deallocated, _):
redis_eventpublisher.update_readmodel(event.orderid, event.sku, None)Les helpers dans notre module Redis sont des one-liners :
def update_readmodel(orderid, sku, batchref):
r.hset(orderid, sku, batchref)
def get_readmodel(orderid):
return r.hgetall(orderid)(Peut-être que le nom redis_eventpublisher.py est maintenant mal choisi, mais vous voyez l’idée.)
Et la vue elle-même change très légèrement pour s’adapter à son nouveau backend :
def allocations(orderid: str):
batches = redis_eventpublisher.get_readmodel(orderid)
return [
{"batchref": b.decode(), "sku": s.decode()}
for s, b in batches.items()
]Et les mêmes tests d’intégration que nous avions avant passent toujours, parce qu’ils sont écrits à un niveau d’abstraction qui est découplé de l' implémentation : la configuration met des messages sur le bus de messages, et les assertions sont contre notre vue.
| Les gestionnaires d’événements sont un excellent moyen de gérer les mises à jour d’un modèle de lecture, si vous décidez d’en avoir besoin. Ils facilitent aussi le changement de l' implémentation de ce modèle de lecture à une date ultérieure. |
12.12. Récapitulation
Compromis des diverses options de modèle de vue propose quelques avantages et inconvénients pour chacune de nos options.
Il se trouve que le service d’allocation chez MADE.com utilise bien du CQRS "complet", avec un modèle de lecture stocké dans Redis, et même une deuxième couche de cache fournie par Varnish. Mais ses cas d’utilisation sont assez différents de ce que nous avons montré ici. Pour le type de service d’allocation que nous construisons, il semble peu probable que vous ayez besoin d’utiliser un modèle de lecture séparé et des gestionnaires d’événements pour le mettre à jour.
Mais au fur et à mesure que votre modèle de domaine devient plus riche et plus complexe, un modèle de lecture simplifié devient de plus en plus convaincant.
| Option | Avantages | Inconvénients |
|---|---|---|
Utiliser simplement des repositories |
Approche simple et cohérente. |
Attendez-vous à des problèmes de performance avec des patterns de requête complexes. |
Utiliser des requêtes personnalisées avec votre ORM |
Permet la réutilisation de la configuration DB et des définitions de modèle. |
Ajoute un autre langage de requête avec ses propres bizarreries et syntaxe. |
Utiliser du SQL fait maison pour interroger vos tables de modèle normales |
Offre un contrôle fin sur la performance avec une syntaxe de requête standard. |
Les changements au schéma DB doivent être faits à vos requêtes fait maison et à vos définitions ORM. Les schémas hautement normalisés peuvent encore avoir des limitations de performance. |
Ajouter des tables supplémentaires (dénormalisées) à votre DB comme modèle de lecture |
Une table dénormalisée peut être beaucoup plus rapide à interroger. Si nous mettons à jour les tables normalisées et dénormalisées dans la même transaction, nous aurons toujours de bonnes garanties de cohérence des données |
Cela ralentira légèrement les écritures |
Créer des magasins de lecture séparés avec des événements |
Les copies en lecture seule sont faciles à mettre à l’échelle. Les vues peuvent être construites quand les données changent pour que les requêtes soient aussi simples que possible. |
Technique complexe. Harry sera à jamais suspicieux de vos goûts et motivations. |
Souvent, vos opérations de lecture agiront sur les mêmes objets conceptuels que votre modèle d’écriture, donc utiliser l’ORM, ajouter quelques méthodes de lecture à vos repositories, et utiliser des classes de modèle de domaine pour vos opérations de lecture est très bien.
Dans notre exemple de livre, les opérations de lecture agissent sur des entités conceptuelles assez différentes
de notre modèle de domaine. Le service d’allocation pense en termes de
Batches pour un seul SKU, mais les utilisateurs se soucient des allocations pour une commande entière,
avec plusieurs SKUs, donc utiliser l’ORM finit par être un peu maladroit. Nous serions
assez tentés d’aller avec la vue SQL brut que nous avons montrée au tout début du
chapitre.
Sur cette note, avançons vers notre dernier chapitre.
13. Injection de Dépendances (Dependency Injection) (et Amorçage)
L’Injection de Dépendances (Dependency Injection, DI) est regardée avec suspicion dans le monde Python. Et nous nous en sommes très bien sortis sans elle jusqu’à présent dans le code d’exemple pour ce livre !
Dans ce chapitre, nous allons explorer certains des points de douleur dans notre code qui nous amènent à considérer l’utilisation de la DI, et nous présenterons quelques options pour savoir comment le faire, vous laissant choisir celle que vous pensez être la plus Pythonique.
Nous ajouterons également un nouveau composant à notre architecture appelé bootstrap.py; il sera en charge de l’injection de dépendances, ainsi que d’autres activités d’initialisation dont nous avons souvent besoin. Nous expliquerons pourquoi ce genre de chose est appelé une racine de composition (composition root) dans les langages OO, et pourquoi script d’amorçage (bootstrap) convient tout à fait à nos objectifs.
Sans bootstrap : les points d’entrée font beaucoup montre à quoi ressemble notre application sans un bootstrapper : les points d’entrée font beaucoup d’initialisation et de passage de notre dépendance principale, l’UoW.
|
Si vous ne l’avez pas encore fait, il vaut la peine de lire Une Brève Digression : Sur le Couplage et les Abstractions avant de continuer avec ce chapitre, en particulier la discussion sur la gestion des dépendances fonctionnelle versus orientée objet. |
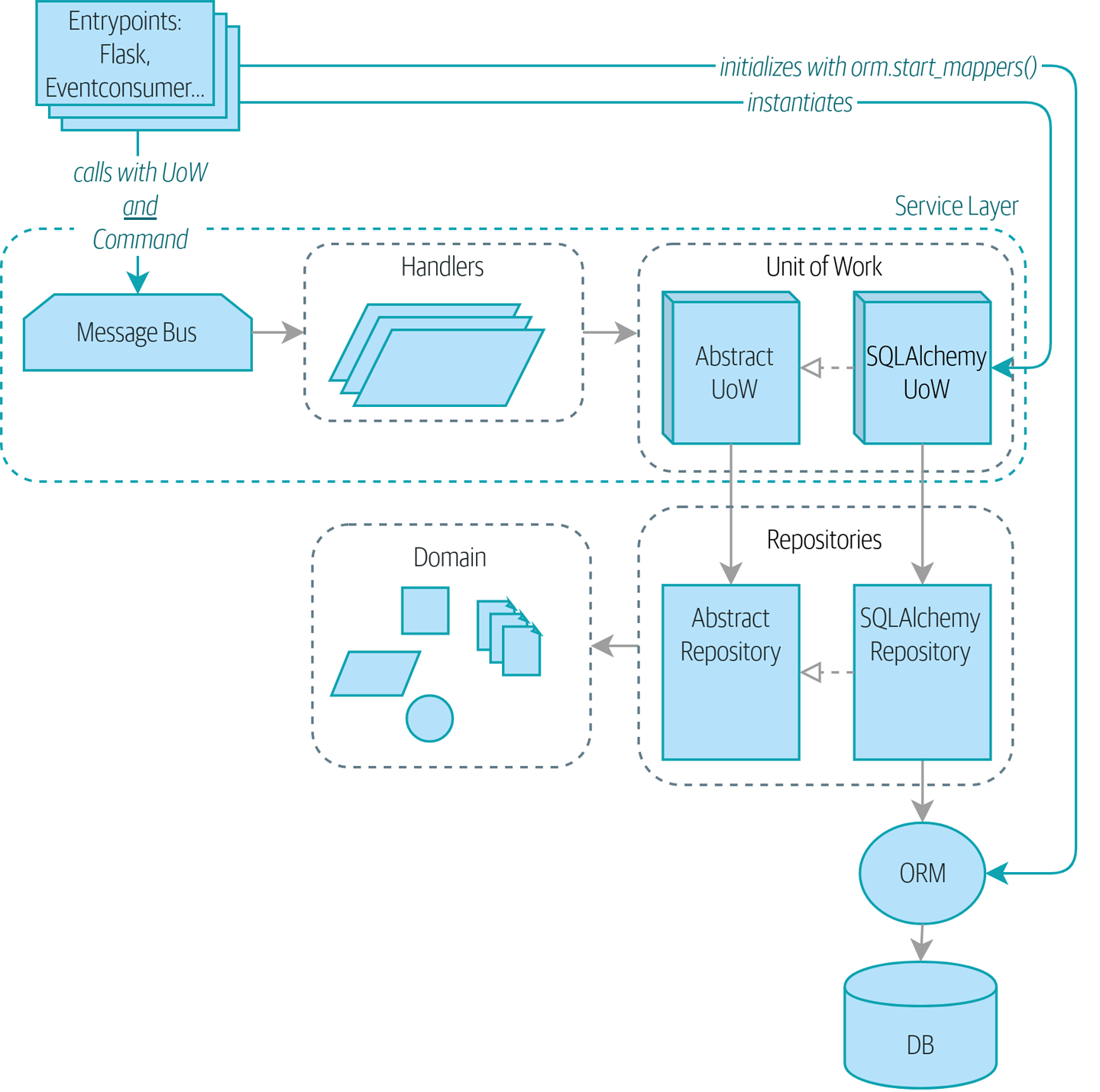
|
Le code pour ce chapitre se trouve dans la branche chapter_13_dependency_injection sur GitHub : git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_13_dependency_injection # or to code along, checkout the previous chapter: git checkout chapter_12_cqrs |
Le Bootstrap prend en charge tout cela en un seul endroit montre notre bootstrapper prenant en charge ces responsabilités.
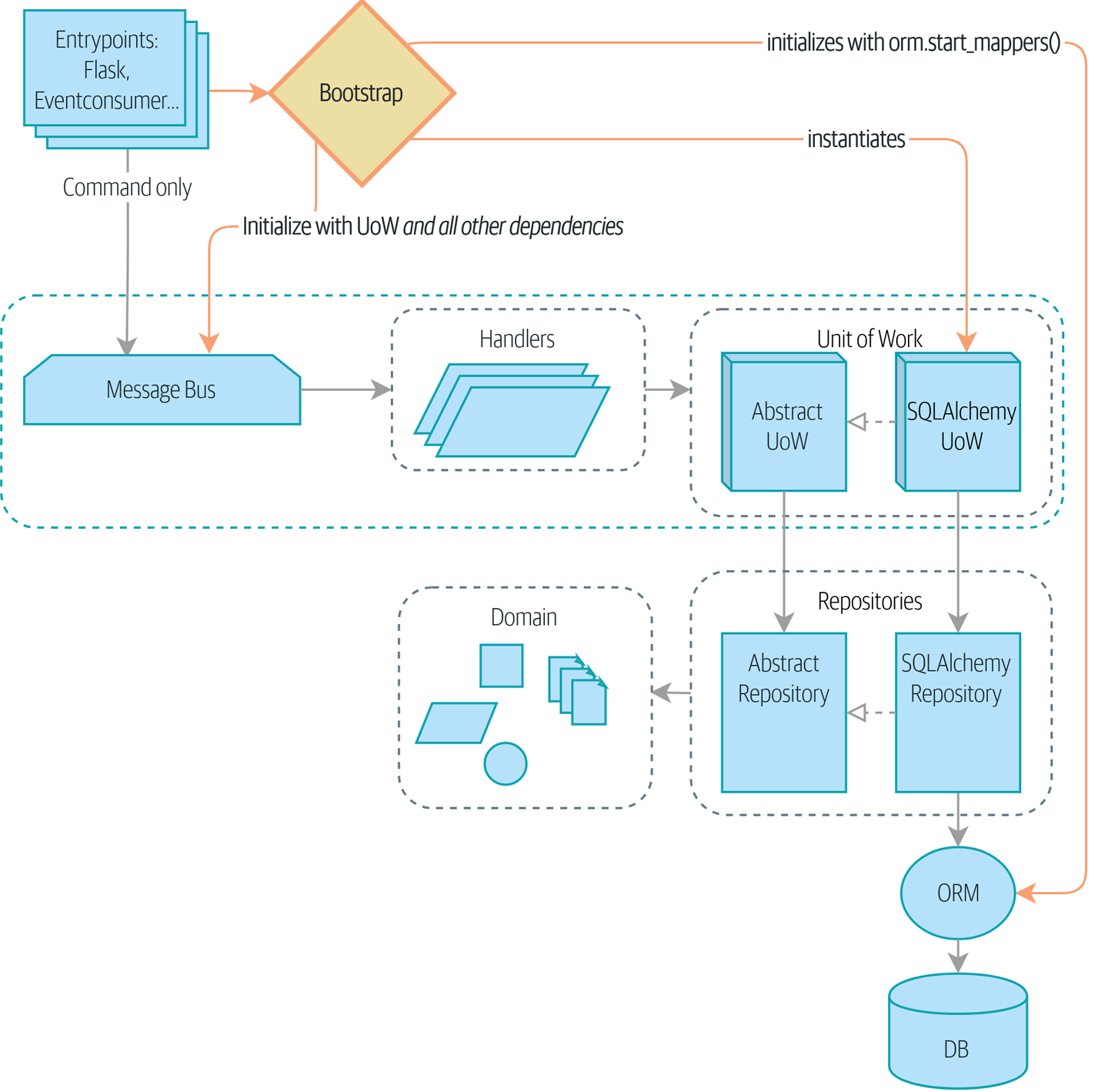
13.1. Dépendances Implicites versus Explicites
Selon votre type de cerveau particulier, vous pouvez avoir un léger sentiment de malaise au fond de votre esprit à ce stade. Mettons-le au grand jour . Nous vous avons montré deux façons de gérer les dépendances et de les tester.
Pour notre dépendance à la base de données, nous avons construit un cadre soigneux de dépendances explicites et des options faciles pour les remplacer dans les tests. Nos fonctions de gestionnaire principales déclarent une dépendance explicite sur l’UoW :
def allocate(
cmd: commands.Allocate,
uow: unit_of_work.AbstractUnitOfWork,
):Et cela facilite l’échange d’un faux UoW dans nos tests de couche de service :
uow = FakeUnitOfWork()
messagebus.handle([...], uow)L’UoW lui-même déclare une dépendance explicite sur la fabrique de session :
class SqlAlchemyUnitOfWork(AbstractUnitOfWork):
def __init__(self, session_factory=DEFAULT_SESSION_FACTORY):
self.session_factory = session_factory
...Nous en profitons dans nos tests d’intégration pour pouvoir parfois utiliser SQLite au lieu de Postgres :
def test_rolls_back_uncommitted_work_by_default(sqlite_session_factory):
uow = unit_of_work.SqlAlchemyUnitOfWork(sqlite_session_factory) (1)| 1 | Les tests d’intégration échangent la session_factory Postgres par défaut pour une
SQLite. |
13.2. Les Dépendances Explicites ne Sont-elles pas Totalement Bizarres et à la Java ?
Si vous êtes habitué à la façon dont les choses se passent normalement en Python, vous penserez que tout cela est un peu bizarre. La façon standard de faire les choses est de déclarer notre dépendance implicitement en l’important simplement, et ensuite si nous avons besoin de la changer pour les tests, nous pouvons monkeypatcher, comme il se doit dans les langages dynamiques :
from allocation.adapters import email, redis_eventpublisher (1)
...
def send_out_of_stock_notification(
event: events.OutOfStock,
uow: unit_of_work.AbstractUnitOfWork,
):
email.send( (2)
"stock@made.com",
f"Out of stock for {event.sku}",
)| 1 | Import codé en dur |
| 2 | Appelle directement l’expéditeur d’email spécifique |
Pourquoi polluer notre code d’application avec des arguments inutiles juste pour le
bien de nos tests ? mock.patch rend le monkeypatching agréable et facile :
with mock.patch("allocation.adapters.email.send") as mock_send_mail:
...Le problème est que nous avons fait en sorte que ça paraisse facile parce que notre exemple jouet n'
envoie pas de vrais emails (email.send_mail fait juste un print), mais dans la vraie vie,
vous finiriez par devoir appeler mock.patch pour chaque test unique qui pourrait
causer une notification de rupture de stock. Si vous avez travaillé sur des bases de code avec beaucoup de
mocks utilisés pour prévenir des effets secondaires indésirables, vous saurez à quel point ce
boilerplate mocky devient ennuyeux.
Et vous saurez que les mocks nous couplent étroitement à l’implémentation. En
choisissant de monkeypatcher email.send_mail, nous sommes liés à faire import email,
et si nous voulons jamais faire from email import send_mail, un refactoring trivial,
nous devrions changer tous nos mocks.
Donc c’est un compromis. Oui, déclarer des dépendances explicites est inutile, strictement parlant, et les utiliser rendrait notre code d’application marginalement plus complexe. Mais en retour, nous obtiendrions des tests qui sont plus faciles à écrire et à gérer.
En plus de cela, déclarer une dépendance explicite est un exemple du principe d’inversion de dépendance—plutôt que d’avoir une dépendance (implicite) sur un détail spécifique, nous avons une dépendance (explicite) sur une abstraction :
L’explicite est meilleur que l’implicite.
def send_out_of_stock_notification(
event: events.OutOfStock,
send_mail: Callable,
):
send_mail(
"stock@made.com",
f"Out of stock for {event.sku}",
)Mais si nous changeons pour déclarer toutes ces dépendances explicitement, qui va
les injecter, et comment ? Jusqu’à présent, nous avons vraiment eu affaire seulement au passage de l'
UoW : nos tests utilisent FakeUnitOfWork, tandis que Flask et Redis eventconsumer
entrypoints utilisent le vrai UoW, et le bus de messages les transmet à nos gestionnaires de
commandes. Si nous ajoutons de vraies et fausses classes d’email, qui va les créer et
les transmettre ?
Cela doit se produire aussi tôt que possible dans le cycle de vie du processus, donc l’endroit le plus évident est dans nos points d’entrée. Cela signifierait du cruft supplémentaire (dupliqué) dans Flask et Redis, et dans nos tests. Et nous devrions aussi ajouter la responsabilité de transmettre les dépendances au bus de messages, qui a déjà un travail à faire ; cela ressemble à une violation du SRP.
Au lieu de cela, nous allons nous tourner vers un pattern appelé Racine de Composition (Composition Root) (un script d’amorçage pour vous et moi),[32] et nous ferons un peu de "DI manuelle" (injection de dépendances sans un framework). Voir Bootstrapper entre les points d’entrée et le bus de messages.[33]

[ditaa, apwp_1303]
+---------------+
| Entrypoints |
| (Flask/Redis) |
+---------------+
|
| call
V
/--------------\
| | prepares handlers with correct dependencies injected in
| Bootstrapper | (test bootstrapper will use fakes, prod one will use real)
| |
\--------------/
|
| pass injected handlers to
V
/---------------\
| Message Bus |
+---------------+
|
| dispatches events and commands to injected handlers
|
V
13.3. Préparer les Gestionnaires : DI Manuelle avec des Fermetures et des Partielles
Une façon de transformer une fonction avec des dépendances en une qui est prête à être appelée plus tard avec ces dépendances déjà injectées est d’utiliser des fermetures ou des fonctions partielles pour composer la fonction avec ses dépendances :
# existing allocate function, with abstract uow dependency
def allocate(
cmd: commands.Allocate,
uow: unit_of_work.AbstractUnitOfWork,
):
line = OrderLine(cmd.orderid, cmd.sku, cmd.qty)
with uow:
...
# bootstrap script prepares actual UoW
def bootstrap(..):
uow = unit_of_work.SqlAlchemyUnitOfWork()
# prepare a version of the allocate fn with UoW dependency captured in a closure
allocate_composed = lambda cmd: allocate(cmd, uow)
# or, equivalently (this gets you a nicer stack trace)
def allocate_composed(cmd):
return allocate(cmd, uow)
# alternatively with a partial
import functools
allocate_composed = functools.partial(allocate, uow=uow) (1)
# later at runtime, we can call the partial function, and it will have
# the UoW already bound
allocate_composed(cmd)| 1 | La différence entre les fermetures (lambdas ou fonctions nommées) et
functools.partial est que les premières utilisent
la liaison tardive des variables,
ce qui peut être une source de confusion si l’une des dépendances est mutable.
|
Voici le même pattern à nouveau pour le gestionnaire send_out_of_stock_notification(),
qui a des dépendances différentes :
def send_out_of_stock_notification(
event: events.OutOfStock,
send_mail: Callable,
):
send_mail(
"stock@made.com",
...
# prepare a version of the send_out_of_stock_notification with dependencies
sosn_composed = lambda event: send_out_of_stock_notification(event, email.send_mail)
...
# later, at runtime:
sosn_composed(event) # will have email.send_mail already injected in13.4. Une Alternative Utilisant des Classes
Les fermetures et les fonctions partielles sembleront familières aux personnes qui ont fait un peu de programmation fonctionnelle. Voici une alternative utilisant des classes, qui peut plaire à d’autres. Cela nécessite cependant de réécrire toutes nos fonctions de gestionnaire comme des classes :
# we replace the old `def allocate(cmd, uow)` with:
class AllocateHandler:
def __init__(self, uow: unit_of_work.AbstractUnitOfWork): (2)
self.uow = uow
def __call__(self, cmd: commands.Allocate): (1)
line = OrderLine(cmd.orderid, cmd.sku, cmd.qty)
with self.uow:
# rest of handler method as before
...
# bootstrap script prepares actual UoW
uow = unit_of_work.SqlAlchemyUnitOfWork()
# then prepares a version of the allocate fn with dependencies already injected
allocate = AllocateHandler(uow)
...
# later at runtime, we can call the handler instance, and it will have
# the UoW already injected
allocate(cmd)| 1 | La classe est conçue pour produire une fonction appelable, donc elle a une méthode __call__. |
| 2 | Mais nous utilisons le init pour déclarer les dépendances dont elle
a besoin. Ce genre de chose semblera familier si vous avez déjà fait des
descripteurs basés sur des classes, ou un gestionnaire de contexte basé sur une classe qui prend
des arguments. |
Utilisez celle avec laquelle vous et votre équipe vous sentez le plus à l’aise.
13.5. Un Script d’Amorçage (Bootstrap)
Nous voulons que notre script d’amorçage fasse ce qui suit :
-
Déclarer les dépendances par défaut mais nous permettre de les remplacer
-
Faire les choses d'"init" dont nous avons besoin pour démarrer notre application
-
Injecter toutes les dépendances dans nos gestionnaires
-
Nous retourner l’objet central de notre application, le bus de messages
Voici une première version :
def bootstrap(
start_orm: bool = True, (1)
uow: unit_of_work.AbstractUnitOfWork = unit_of_work.SqlAlchemyUnitOfWork(), (2)
send_mail: Callable = email.send,
publish: Callable = redis_eventpublisher.publish,
) -> messagebus.MessageBus:
if start_orm:
orm.start_mappers() (1)
dependencies = {"uow": uow, "send_mail": send_mail, "publish": publish}
injected_event_handlers = { (3)
event_type: [
inject_dependencies(handler, dependencies)
for handler in event_handlers
]
for event_type, event_handlers in handlers.EVENT_HANDLERS.items()
}
injected_command_handlers = { (3)
command_type: inject_dependencies(handler, dependencies)
for command_type, handler in handlers.COMMAND_HANDLERS.items()
}
return messagebus.MessageBus( (4)
uow=uow,
event_handlers=injected_event_handlers,
command_handlers=injected_command_handlers,
)| 1 | orm.start_mappers() est notre exemple de travail d’initialisation qui doit
être fait une fois au début d’une application. Un autre exemple courant est
la configuration du module logging.
|
| 2 | Nous pouvons utiliser les valeurs par défaut des arguments pour définir quelles sont les valeurs par défaut normales/de production
|
| 3 | Nous construisons nos versions injectées des mappages de gestionnaires en utilisant
une fonction appelée inject_dependencies(), que nous montrerons ensuite. |
| 4 | Nous retournons un bus de messages configuré prêt à l’emploi. |
Voici comment nous injectons des dépendances dans une fonction de gestionnaire en l’inspectant :
def inject_dependencies(handler, dependencies):
params = inspect.signature(handler).parameters (1)
deps = {
name: dependency
for name, dependency in dependencies.items() (2)
if name in params
}
return lambda message: handler(message, **deps) (3)| 1 | Nous inspectons les arguments de notre gestionnaire de commande/événement. |
| 2 | Nous les faisons correspondre par nom à nos dépendances. |
| 3 | Nous les injectons comme kwargs pour produire une partielle. |
13.6. Le Bus de Messages Reçoit les Gestionnaires à l’Exécution
Notre bus de messages ne sera plus statique ; il doit avoir les gestionnaires déjà injectés qui lui sont donnés. Donc nous le transformons d’un module en une classe configurable :
class MessageBus: (1)
def __init__(
self,
uow: unit_of_work.AbstractUnitOfWork,
event_handlers: Dict[Type[events.Event], List[Callable]], (2)
command_handlers: Dict[Type[commands.Command], Callable], (2)
):
self.uow = uow
self.event_handlers = event_handlers
self.command_handlers = command_handlers
def handle(self, message: Message): (3)
self.queue = [message] (4)
while self.queue:
message = self.queue.pop(0)
if isinstance(message, events.Event):
self.handle_event(message)
elif isinstance(message, commands.Command):
self.handle_command(message)
else:
raise Exception(f"{message} was not an Event or Command")| 1 | Le bus de messages devient une classe… |
| 2 | …à laquelle on donne ses gestionnaires déjà injectés de dépendances. |
| 3 | La fonction principale handle() est sensiblement la même, avec juste quelques attributs et méthodes déplacés sur self. |
| 4 | Utiliser self.queue comme ceci n’est pas thread-safe, ce qui pourrait
être un problème si vous utilisez des threads, parce que l’instance du bus est globale
dans le contexte de l’application Flask comme nous l’avons écrit. C’est juste quelque chose à surveiller. |
Qu’est-ce qui change d’autre dans le bus ?
def handle_event(self, event: events.Event):
for handler in self.event_handlers[type(event)]: (1)
try:
logger.debug("handling event %s with handler %s", event, handler)
handler(event) (2)
self.queue.extend(self.uow.collect_new_events())
except Exception:
logger.exception("Exception handling event %s", event)
continue
def handle_command(self, command: commands.Command):
logger.debug("handling command %s", command)
try:
handler = self.command_handlers[type(command)] (1)
handler(command) (2)
self.queue.extend(self.uow.collect_new_events())
except Exception:
logger.exception("Exception handling command %s", command)
raise| 1 | handle_event et handle_command sont sensiblement les mêmes, mais au lieu
d’indexer dans un dict statique EVENT_HANDLERS ou COMMAND_HANDLERS, ils
utilisent les versions sur self. |
| 2 | Au lieu de passer un UoW dans le gestionnaire, nous attendons que les gestionnaires aient déjà toutes leurs dépendances, donc tout ce dont ils ont besoin est un seul argument, l’événement ou la commande spécifique. |
13.7. Utiliser Bootstrap dans Nos Points d’Entrée
Dans les points d’entrée de notre application, nous appelons maintenant simplement bootstrap.bootstrap()
et obtenons un bus de messages prêt à l’emploi, plutôt que de configurer un UoW et le
reste :
-from allocation import views
+from allocation import bootstrap, views
app = Flask(__name__)
-orm.start_mappers() (1)
+bus = bootstrap.bootstrap()
@app.route("/add_batch", methods=["POST"])
@@ -19,8 +16,7 @@ def add_batch():
cmd = commands.CreateBatch(
request.json["ref"], request.json["sku"], request.json["qty"], eta
)
- uow = unit_of_work.SqlAlchemyUnitOfWork() (2)
- messagebus.handle(cmd, uow)
+ bus.handle(cmd) (3)
return "OK", 201| 1 | Nous n’avons plus besoin d’appeler start_orm() ; les étapes d’initialisation du script de bootstrap
s’en chargeront. |
| 2 | Nous n’avons plus besoin de construire explicitement un type particulier d’UoW ; les valeurs par défaut du script de bootstrap s’en occupent. |
| 3 | Et notre bus de messages est maintenant une instance spécifique plutôt que le module global.[34] |
13.8. Initialiser la DI dans Nos Tests
Dans les tests, nous pouvons utiliser bootstrap.bootstrap() avec des valeurs par défaut remplacées pour obtenir un
bus de messages personnalisé. Voici un exemple dans un test d’intégration :
@pytest.fixture
def sqlite_bus(sqlite_session_factory):
bus = bootstrap.bootstrap(
start_orm=True, (1)
uow=unit_of_work.SqlAlchemyUnitOfWork(sqlite_session_factory), (2)
send_mail=lambda *args: None, (3)
publish=lambda *args: None, (3)
)
yield bus
clear_mappers()
def test_allocations_view(sqlite_bus):
sqlite_bus.handle(commands.CreateBatch("sku1batch", "sku1", 50, None))
sqlite_bus.handle(commands.CreateBatch("sku2batch", "sku2", 50, today))
...
assert views.allocations("order1", sqlite_bus.uow) == [
{"sku": "sku1", "batchref": "sku1batch"},
{"sku": "sku2", "batchref": "sku2batch"},
]| 1 | Nous voulons toujours démarrer l’ORM… |
| 2 | …parce que nous allons utiliser un vrai UoW, bien qu’avec une base de données en mémoire. |
| 3 | Mais nous n’avons pas besoin d’envoyer d’email ou de publier, donc nous en faisons des noops. |
Dans nos tests unitaires, en revanche, nous pouvons réutiliser notre FakeUnitOfWork :
def bootstrap_test_app():
return bootstrap.bootstrap(
start_orm=False, (1)
uow=FakeUnitOfWork(), (2)
send_mail=lambda *args: None, (3)
publish=lambda *args: None, (3)
)| 1 | Pas besoin de démarrer l’ORM… |
| 2 | …parce que le faux UoW n’en utilise pas. |
| 3 | Nous voulons aussi simuler nos adaptateurs email et Redis. |
Donc cela élimine un peu de duplication, et nous avons déplacé un tas de configuration et de valeurs par défaut sensées en un seul endroit.
13.9. Construire un Adaptateur "Proprement" : Un Exemple Pratique
Pour vraiment avoir une idée de comment tout cela fonctionne, travaillons sur un exemple de comment vous pourriez "proprement" construire un adaptateur et faire l’injection de dépendances pour lui.
Pour le moment, nous avons deux types de dépendances :
uow: unit_of_work.AbstractUnitOfWork, (1)
send_mail: Callable, (2)
publish: Callable, (2)| 1 | L’UoW a une classe de base abstraite. C’est l’option lourde pour déclarer et gérer votre dépendance externe. Nous l’utiliserions dans le cas où la dépendance est relativement complexe. |
| 2 | Notre expéditeur d’email et éditeur pub/sub sont définis comme des fonctions. Cela fonctionne très bien pour les dépendances simples. |
Voici quelques-unes des choses que nous nous trouvons à injecter au travail :
-
Un client de système de fichiers S3
-
Un client de magasin clé/valeur
-
Un objet de session
requests
La plupart d’entre eux auront des API plus complexes que vous ne pouvez pas capturer comme une seule fonction : lecture et écriture, GET et POST, et ainsi de suite.
Même si c’est simple, utilisons send_mail comme exemple pour parler
de la façon dont vous pourriez définir une dépendance plus complexe.
13.9.1. Définir les Implémentations Abstraites et Concrètes
Nous allons imaginer une API de notifications plus générique. Ça pourrait être email, ça pourrait être SMS, ça pourrait être des posts Slack un jour.
class AbstractNotifications(abc.ABC):
@abc.abstractmethod
def send(self, destination, message):
raise NotImplementedError
...
class EmailNotifications(AbstractNotifications):
def __init__(self, smtp_host=DEFAULT_HOST, port=DEFAULT_PORT):
self.server = smtplib.SMTP(smtp_host, port=port)
self.server.noop()
def send(self, destination, message):
msg = f"Subject: allocation service notification\n{message}"
self.server.sendmail(
from_addr="allocations@example.com",
to_addrs=[destination],
msg=msg,
)Nous changeons la dépendance dans le script de bootstrap :
def bootstrap(
start_orm: bool = True,
uow: unit_of_work.AbstractUnitOfWork = unit_of_work.SqlAlchemyUnitOfWork(),
- send_mail: Callable = email.send,
+ notifications: AbstractNotifications = EmailNotifications(),
publish: Callable = redis_eventpublisher.publish,
) -> messagebus.MessageBus:13.9.2. Faire une Version Fausse pour Vos Tests
Nous travaillons et définissons une version fausse pour les tests unitaires :
class FakeNotifications(notifications.AbstractNotifications):
def __init__(self):
self.sent = defaultdict(list) # type: Dict[str, List[str]]
def send(self, destination, message):
self.sent[destination].append(message)
...Et nous l’utilisons dans nos tests :
def test_sends_email_on_out_of_stock_error(self):
fake_notifs = FakeNotifications()
bus = bootstrap.bootstrap(
start_orm=False,
uow=FakeUnitOfWork(),
notifications=fake_notifs,
publish=lambda *args: None,
)
bus.handle(commands.CreateBatch("b1", "POPULAR-CURTAINS", 9, None))
bus.handle(commands.Allocate("o1", "POPULAR-CURTAINS", 10))
assert fake_notifs.sent["stock@made.com"] == [
f"Out of stock for POPULAR-CURTAINS",
]13.9.3. Déterminer Comment Tester en Intégration la Vraie Chose
Maintenant nous testons la vraie chose, généralement avec un test de bout en bout ou d’intégration . Nous avons utilisé MailHog comme un serveur email vraiment-faux pour notre environnement de développement Docker :
version: "3"
services:
redis_pubsub:
build:
context: .
dockerfile: Dockerfile
image: allocation-image
...
api:
image: allocation-image
...
postgres:
image: postgres:9.6
...
redis:
image: redis:alpine
...
mailhog:
image: mailhog/mailhog
ports:
- "11025:1025"
- "18025:8025"
Dans nos tests d’intégration, nous utilisons la vraie classe EmailNotifications,
parlant au serveur MailHog dans le cluster Docker :
@pytest.fixture
def bus(sqlite_session_factory):
bus = bootstrap.bootstrap(
start_orm=True,
uow=unit_of_work.SqlAlchemyUnitOfWork(sqlite_session_factory),
notifications=notifications.EmailNotifications(), (1)
publish=lambda *args: None,
)
yield bus
clear_mappers()
def get_email_from_mailhog(sku): (2)
host, port = map(config.get_email_host_and_port().get, ["host", "http_port"])
all_emails = requests.get(f"http://{host}:{port}/api/v2/messages").json()
return next(m for m in all_emails["items"] if sku in str(m))
def test_out_of_stock_email(bus):
sku = random_sku()
bus.handle(commands.CreateBatch("batch1", sku, 9, None)) (3)
bus.handle(commands.Allocate("order1", sku, 10))
email = get_email_from_mailhog(sku)
assert email["Raw"]["From"] == "allocations@example.com" (4)
assert email["Raw"]["To"] == ["stock@made.com"]
assert f"Out of stock for {sku}" in email["Raw"]["Data"]| 1 | Nous utilisons notre bootstrapper pour construire un bus de messages qui parle à la vraie classe de notifications. |
| 2 | Nous déterminons comment récupérer les emails de notre serveur email "réel". |
| 3 | Nous utilisons le bus pour faire notre configuration de test. |
| 4 | Contre toute attente, cela a en fait fonctionné, à peu près du premier coup ! |
Et c’est tout vraiment.
13.10. Récapitulation
-
Une fois que vous avez plus d’un adaptateur, vous commencerez à ressentir beaucoup de douleur en passant les dépendances manuellement, à moins que vous ne fassiez une sorte d' injection de dépendances.
-
Configurer l’injection de dépendances n’est qu’une des nombreuses activités typiques de configuration/initialisation que vous devez faire une seule fois quand vous démarrez votre application. Rassembler tout cela dans un script de bootstrap est souvent une bonne idée.
-
Le script de bootstrap est aussi un bon endroit pour fournir une configuration par défaut sensée pour vos adaptateurs, et comme un endroit unique pour remplacer ces adaptateurs par des faux pour vos tests.
-
Un framework d’injection de dépendances peut être utile si vous vous trouvez à avoir besoin de faire de la DI à plusieurs niveaux—si vous avez des dépendances chaînées de composants qui ont tous besoin de DI, par exemple.
-
Ce chapitre a également présenté un exemple pratique de changement d’une dépendance implicite/simple en un adaptateur "propre", en factorisant une ABC, en définissant ses implémentations réelles et fausses, et en réfléchissant aux tests d’intégration.
C’étaient les derniers patterns que nous voulions couvrir, ce qui nous amène à la fin de Architecture Événementielle. Dans l’épilogue, nous essaierons de vous donner quelques pointeurs pour appliquer ces techniques dans le Monde RéelTM.
Appendix A: Épilogue
Et Maintenant ?
Ouf ! Nous avons couvert beaucoup de terrain dans ce livre, et pour la plupart de notre public toutes ces idées sont nouvelles. Dans cet esprit, nous ne pouvons espérer faire de vous des experts dans ces techniques. Tout ce que nous pouvons vraiment faire est de vous montrer les idées générales, et juste assez de code pour que vous puissiez aller de l’avant et écrire quelque chose à partir de zéro.
Le code que nous avons montré dans ce livre n’est pas du code de production éprouvé : c’est un ensemble de blocs Lego avec lesquels vous pouvez jouer pour construire votre première maison, vaisseau spatial, et gratte-ciel.
Cela nous laisse deux grandes tâches. Nous voulons parler de comment commencer à appliquer ces idées pour de vrai dans un système existant, et nous devons vous avertir de certaines choses que nous avons dû sauter. Nous vous avons donné tout un nouvel arsenal de façons de vous tirer dans le pied, donc nous devrions discuter de quelques règles de sécurité de base avec les armes à feu.
Comment Puis-je Arriver Là Depuis Ici ?
Il y a de fortes chances que beaucoup d’entre vous pensent quelque chose comme ceci :
"OK Bob et Harry, tout cela est bien beau, et si jamais je suis embauché pour travailler sur un nouveau service vierge, je sais quoi faire. Mais en attendant, je suis ici avec ma grosse boule de boue Django, et je ne vois aucun moyen d’arriver à votre modèle agréable, propre, parfait, intact et simpliste. Pas depuis ici."
Nous vous entendons. Une fois que vous avez déjà construit une grosse boule de boue, il est difficile de savoir comment commencer à améliorer les choses. Vraiment, nous devons nous attaquer aux choses étape par étape.
Avant tout : quel problème essayez-vous de résoudre ? Le logiciel est-il trop difficile à changer ? La performance est-elle inacceptable ? Avez-vous des bugs étranges et inexplicables ?
Avoir un objectif clair en tête vous aidera à prioriser le travail qui doit être fait et, surtout, communiquer les raisons de le faire au reste de l’équipe. Les entreprises ont tendance à avoir des approches pragmatiques de la dette technique et du refactoring, tant que les ingénieurs peuvent faire un argument raisonné pour réparer les choses.
| Faire des changements complexes à un système est souvent une vente plus facile si vous le liez au travail de fonctionnalité. Peut-être que vous lancez un nouveau produit ou ouvrez votre service à de nouveaux marchés ? C’est le bon moment pour dépenser des ressources d’ingénierie pour réparer les fondations. Avec un projet de six mois à livrer, il est plus facile de faire l’argument pour trois semaines de travail de nettoyage. Bob se réfère à cela comme taxe d’architecture. |
Séparer les Responsabilités Enchevêtrées
Au début du livre, nous avons dit que la principale caractéristique d’une grosse boule de boue est l’homogénéité : chaque partie du système se ressemble, parce que nous n’avons pas été clairs sur les responsabilités de chaque composant. Pour réparer cela, nous devrons commencer à séparer les responsabilités et introduire des limites claires. Une des premières choses que nous pouvons faire est de commencer à construire une Couche de Service (Service Layer) (Domaine d’un système de collaboration).
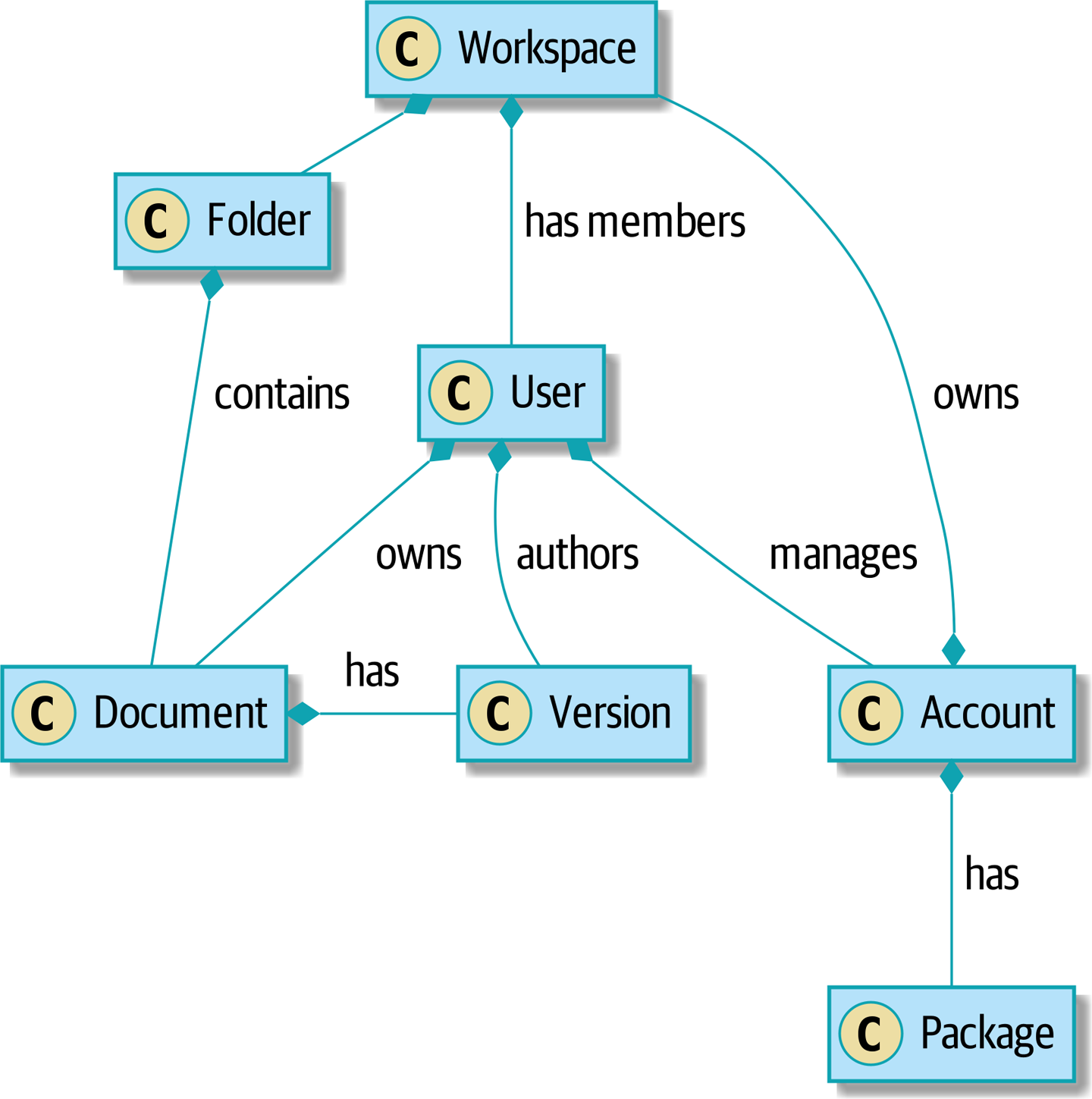
[plantuml, apwp_ep01, config=plantuml.cfg] @startuml scale 4 hide empty members Workspace *- Folder : contains Account *- Workspace : owns Account *-- Package : has User *-- Account : manages Workspace *-- User : has members User *-- Document : owns Folder *-- Document : contains Document *- Version: has User *-- Version: authors @enduml
C’était le système dans lequel Bob a d’abord appris comment démanteler une boule de boue, et c’était un sacré morceau. Il y avait de la logique partout—dans les pages web, dans les objets manager, dans les helpers, dans les grosses classes de service que nous avions écrites pour abstraire les managers et helpers, et dans des objets de commande complexes que nous avions écrits pour démanteler les services.
Si vous travaillez dans un système qui a atteint ce point, la situation peut sembler désespérée, mais il n’est jamais trop tard pour commencer à désherber un jardin envahi. Finalement, nous avons embauché un architecte qui savait ce qu’il faisait, et il nous a aidés à reprendre les choses en main.
Commencez par déterminer les Cas d’Usage (Use Cases) de votre système. Si vous avez une interface utilisateur, quelles actions effectue-t-elle ? Si vous avez un composant de traitement backend, peut-être que chaque tâche cron ou Celery est un seul cas d’usage. Chacun de vos cas d’usage doit avoir un nom impératif : Appliquer des Frais de Facturation, Nettoyer les Comptes Abandonnés, ou Émettre un Bon de Commande, par exemple.
Dans notre cas, la plupart de nos cas d’usage faisaient partie des classes manager et avaient des noms comme Créer un Espace de Travail ou Supprimer une Version de Document. Chaque cas d’usage était invoqué depuis un frontend web.
Nous visons à créer une seule fonction ou classe pour chacune de ces opérations supportées qui s’occupe d'orchestrer le travail à faire. Chaque cas d’usage devrait faire ce qui suit :
-
Démarrer sa propre transaction de base de données si nécessaire
-
Récupérer toutes les données requises
-
Vérifier toutes les préconditions (voir le pattern Ensure dans Validation)
-
Mettre à jour le Modèle de Domaine (Domain Model)
-
Persister tous les changements
Chaque cas d’usage devrait réussir ou échouer comme une unité atomique. Vous pourriez avoir besoin d’appeler un cas d’usage depuis un autre. C’est OK ; notez-le simplement, et essayez d’éviter les transactions de base de données de longue durée.
| Un des plus gros problèmes que nous avions était que les méthodes manager appelaient d’autres méthodes manager, et l’accès aux données pouvait se produire depuis les objets du modèle eux-mêmes. Il était difficile de comprendre ce que chaque opération faisait sans partir à la chasse au trésor à travers la base de code. Mettre toute la logique dans une seule méthode, et utiliser une UoW pour contrôler nos transactions, a rendu le système plus facile à raisonner. |
| C’est bien si vous avez de la duplication dans les fonctions de cas d’usage. Nous n’essayons pas d’écrire du code parfait ; nous essayons juste d’extraire quelques couches significatives. Il est préférable de dupliquer du code à quelques endroits plutôt que d’avoir des fonctions de cas d’usage s’appelant les unes les autres dans une longue chaîne. |
C’est une bonne opportunité pour retirer tout code d’accès aux données ou d’orchestration du modèle de domaine et le mettre dans les cas d’usage. Nous devrions également essayer de retirer les préoccupations d’I/O (par ex., envoyer des emails, écrire des fichiers) du modèle de domaine et les faire monter dans les fonctions de cas d’usage. Nous appliquons les techniques du Une Brève Digression : Sur le Couplage et les Abstractions sur les Abstractions (Abstractions) pour garder nos gestionnaires testables unitairement même quand ils effectuent des I/O.
Ces fonctions de cas d’usage seront principalement sur la journalisation, l’accès aux données et la gestion des erreurs. Une fois que vous avez fait cette étape, vous aurez une compréhension de ce que votre programme fait réellement, et un moyen de vous assurer que chaque opération a un début et une fin clairement définis. Nous aurons fait un pas vers la construction d’un modèle de domaine pur.
Lisez Working Effectively with Legacy Code par Michael C. Feathers (Prentice Hall) pour des conseils sur comment mettre le code hérité sous test et commencer à séparer les responsabilités.
Identifier les Agrégats et Contextes Délimités
Une partie du problème avec la base de code dans notre étude de cas était que le graphe d’objets était hautement connecté. Chaque compte avait plusieurs espaces de travail, et chaque espace de travail avait plusieurs membres, qui avaient tous leurs propres comptes. Chaque espace de travail contenait plusieurs documents, qui avaient plusieurs versions.
Vous ne pouvez pas exprimer toute l’horreur de la chose dans un diagramme de classes. D’une part, il n’y avait pas vraiment un seul compte lié à un utilisateur. Au lieu de cela, il y avait une règle bizarre vous obligeant à énumérer tous les comptes associés à l’utilisateur via les espaces de travail et à prendre celui avec la date de création la plus ancienne.
Chaque objet dans le système faisait partie d’une hiérarchie d’héritage qui incluait
SecureObject et Version. Cette hiérarchie d’héritage était reflétée directement
dans le schéma de base de données, de sorte que chaque requête devait joindre 10 tables différentes
et regarder une colonne discriminante juste pour savoir quel type d’objets
vous manipuliez.
La base de code rendait facile de "pointer" votre chemin à travers ces objets comme ceci :
user.account.workspaces[0].documents.versions[1].owner.account.settings[0];Construire un système de cette façon avec Django ORM ou SQLAlchemy est facile mais doit être évité. Bien que ce soit pratique, cela rend très difficile de raisonner sur la performance parce que chaque propriété pourrait déclencher une recherche dans la base de données.
| Les Agrégats (Aggregates) sont une limite de cohérence. En général, chaque cas d’usage devrait mettre à jour un seul Agrégat (Aggregate) à la fois. Un Gestionnaire (Handler) récupère un Agrégat (Aggregate) depuis un Dépôt (Repository), modifie son état, et lève tous les Événements (Events) qui se produisent en conséquence. Si vous avez besoin de données d’une autre partie du système, c’est totalement correct d’utiliser un modèle de lecture, mais évitez de mettre à jour plusieurs Agrégats (Aggregates) dans une seule transaction. Quand nous choisissons de séparer le code en différents Agrégats (Aggregates), nous choisissons explicitement de les rendre éventuellement cohérents l’un avec l’autre. |
Un tas d’opérations nous obligeaient à boucler sur des objets de cette façon—par exemple :
# Lock a user's workspaces for nonpayment
def lock_account(user):
for workspace in user.account.workspaces:
workspace.archive()Ou même récurser sur des collections de dossiers et documents :
def lock_documents_in_folder(folder):
for doc in folder.documents:
doc.archive()
for child in folder.children:
lock_documents_in_folder(child)Ces opérations tuaient la performance, mais les corriger signifiait abandonner notre graphe d’objets unique. Au lieu de cela, nous avons commencé à identifier les Agrégats (Aggregates) et à casser les liens directs entre objets.
Nous avons parlé du fameux problème SELECT N+1 dans CQRS (Command Query Responsibility Segregation/Ségrégation des Responsabilités Commande-Requête), et comment
nous pourrions choisir d’utiliser différentes techniques lors de la lecture de données pour les requêtes versus
la lecture de données pour les commandes.
|
Principalement, nous avons fait cela en remplaçant les références directes par des identifiants.
Avant les Agrégats (Aggregates) :
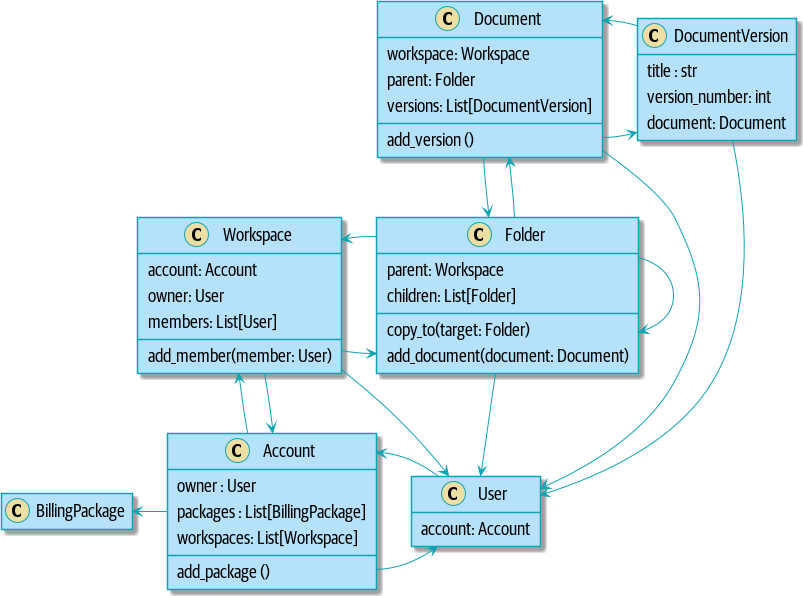
[plantuml, apwp_ep02, config=plantuml.cfg]
@startuml
scale 4
hide empty members
together {
class Document {
add_version()
workspace: Workspace
parent: Folder
versions: List[DocumentVersion]
}
class DocumentVersion {
title : str
version_number: int
document: Document
}
class Folder {
parent: Workspace
children: List[Folder]
copy_to(target: Folder)
add_document(document: Document)
}
}
together {
class User {
account: Account
}
class Account {
add_package()
owner : User
packages : List[BillingPackage]
workspaces: List[Workspace]
}
}
class BillingPackage {
}
class Workspace {
add_member(member: User)
account: Account
owner: User
members: List[User]
}
Account --> Workspace
Account -left-> BillingPackage
Account -right-> User
Workspace --> User
Workspace --> Folder
Workspace --> Account
Folder --> Folder
Folder --> Document
Folder --> Workspace
Folder --> User
Document -right-> DocumentVersion
Document --> Folder
Document --> User
DocumentVersion -right-> Document
DocumentVersion --> User
User -left-> Account
@enduml
Après modélisation avec les Agrégats (Aggregates) :
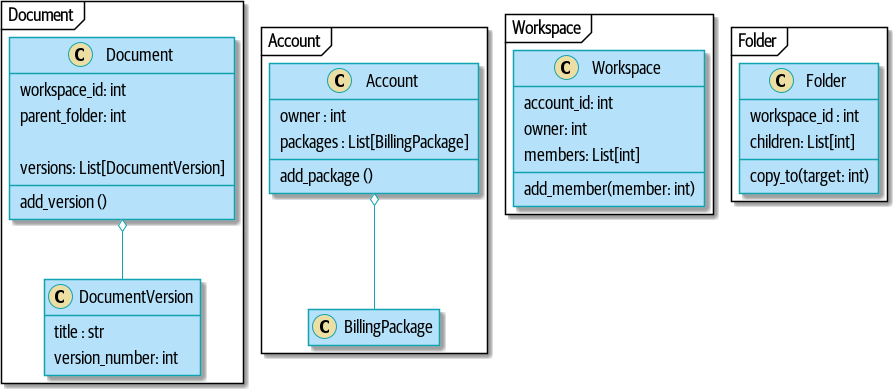
[plantuml, apwp_ep03, config=plantuml.cfg]
@startuml
scale 4
hide empty members
frame Document {
class Document {
add_version()
workspace_id: int
parent_folder: int
versions: List[DocumentVersion]
}
class DocumentVersion {
title : str
version_number: int
}
}
frame Account {
class Account {
add_package()
owner : int
packages : List[BillingPackage]
}
class BillingPackage {
}
}
frame Workspace {
class Workspace {
add_member(member: int)
account_id: int
owner: int
members: List[int]
}
}
frame Folder {
class Folder {
workspace_id : int
children: List[int]
copy_to(target: int)
}
}
Document o-- DocumentVersion
Account o-- BillingPackage
@enduml
Les liens bidirectionnels sont souvent un signe que vos Agrégats (Aggregates) ne sont pas corrects.
Dans notre code original, un Document connaissait son Folder conteneur, et le
Folder avait une collection de Documents. Cela rend facile de traverser le
graphe d’objets mais nous empêche de penser correctement aux limites de
cohérence dont nous avons besoin. Nous cassons les Agrégats (Aggregates) en utilisant des références à la place.
Dans le nouveau modèle, un Document avait une référence à son parent_folder mais n’avait aucun moyen
d’accéder directement au Folder.
|
Si nous avions besoin de lire des données, nous évitions d’écrire des boucles et transformations complexes et essayions de les remplacer par du SQL simple. Par exemple, un de nos écrans était une vue arborescente de dossiers et documents.
Cet écran était incroyablement lourd sur la base de données, parce qu’il reposait sur des
boucles for imbriquées qui déclenchaient un ORM à chargement paresseux.
| Nous utilisons cette même technique dans CQRS (Command Query Responsibility Segregation/Ségrégation des Responsabilités Commande-Requête), où nous remplaçons une boucle imbriquée sur des objets ORM par une simple requête SQL. C’est la première étape dans une approche CQRS (Command Query Responsibility Segregation). |
Après beaucoup de réflexion, nous avons remplacé le code ORM par une grosse et laide procédure stockée.
Le code avait l’air horrible, mais il était beaucoup plus rapide et a aidé
à casser les liens entre Folder et Document.
Quand nous avions besoin d'écrire des données, nous changions un seul Agrégat (Aggregate) à la fois, et nous
avons introduit un Bus de Messages (Message Bus) pour gérer les Événements (Events). Par exemple, dans le nouveau modèle, quand
nous verrouillions un compte, nous pouvions d’abord faire une requête pour tous les espaces de travail affectés via
SELECT id FROM workspace WHERE account_id = ?.
Nous pouvions alors lever une nouvelle Commande (Command) pour chaque espace de travail :
for workspace_id in workspaces:
bus.handle(LockWorkspace(workspace_id))Une Approche Événementielle pour Passer aux Microservices via le Pattern Strangler
Le pattern Strangler Fig implique de créer un nouveau système autour des bords d’un ancien système, tout en le gardant en fonctionnement. Des morceaux de l’ancienne fonctionnalité sont progressivement interceptés et remplacés, jusqu’à ce que l’ancien système ne fasse plus rien du tout et puisse être éteint.
Lors de la construction du service de disponibilité, nous avons utilisé une technique appelée interception d’événements pour déplacer la fonctionnalité d’un endroit à un autre. C’est un processus en trois étapes :
-
Lever des Événements (Events) pour représenter les changements se produisant dans un système que vous voulez remplacer.
-
Construire un deuxième système qui consomme ces Événements (Events) et les utilise pour construire son propre modèle de domaine.
-
Remplacer l’ancien système par le nouveau.
Nous avons utilisé l’interception d’événements pour passer de Avant : couplage fort et bidirectionnel basé sur XML-RPC…

[plantuml, apwp_ep04, config=plantuml.cfg] @startuml Ecommerce Context !include images/C4_Context.puml LAYOUT_LEFT_RIGHT scale 2 Person_Ext(customer, "Customer", "Wants to buy furniture") System(fulfillment, "Fulfillment System", "Manages order fulfillment and logistics") System(ecom, "Ecommerce website", "Allows customers to buy furniture") Rel(customer, ecom, "Uses") Rel(fulfillment, ecom, "Updates stock and orders", "xml-rpc") Rel(ecom, fulfillment, "Sends orders", "xml-rpc") @enduml
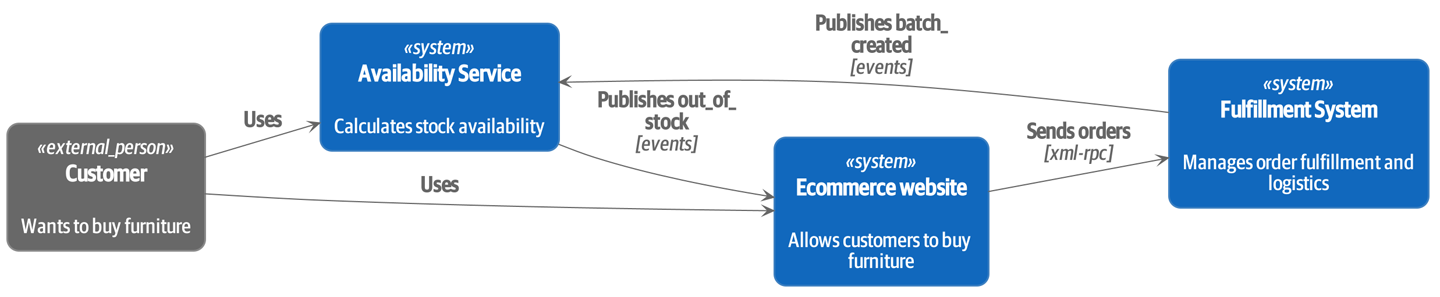
[plantuml, apwp_ep05, config=plantuml.cfg] @startuml Ecommerce Context !include images/C4_Context.puml LAYOUT_LEFT_RIGHT scale 2 Person_Ext(customer, "Customer", "Wants to buy furniture") System(av, "Availability Service", "Calculates stock availability") System(fulfillment, "Fulfillment System", "Manages order fulfillment and logistics") System(ecom, "Ecommerce website", "Allows customers to buy furniture") Rel(customer, ecom, "Uses") Rel(customer, av, "Uses") Rel(fulfillment, av, "Publishes batch_created", "events") Rel(av, ecom, "Publishes out_of_stock", "events") Rel(ecom, fulfillment, "Sends orders", "xml-rpc") @enduml
Pratiquement, c’était un projet de plusieurs mois. Notre première étape était d’écrire un modèle de domaine qui pouvait représenter des lots, des expéditions et des produits. Nous avons utilisé le TDD pour construire un système jouet qui pouvait répondre à une seule question : "Si je veux N unités de HAZARDOUS_RUG, combien de temps prendront-elles pour être livrées ?"
| Lors du déploiement d’un système événementiel, commencez par un "squelette marchant". Déployer un système qui ne fait que journaliser ses entrées nous force à aborder toutes les questions infrastructurelles et à commencer à travailler en production. |
Une fois que nous avions un modèle de domaine fonctionnel, nous sommes passés à la construction de quelques
pièces infrastructurelles. Notre premier déploiement en production était un petit système qui
pouvait recevoir un Événement (Event) batch_created et journaliser sa représentation JSON. C’est
le "Hello World" de l’architecture événementielle. Cela nous a forcés à déployer un Bus de Messages (Message Bus),
connecter un producteur et un consommateur, construire un pipeline de déploiement, et écrire un
simple Gestionnaire (Handler) de message.
Étant donné un pipeline de déploiement, l’infrastructure dont nous avions besoin, et un modèle de domaine de base, nous étions partis. Quelques mois plus tard, nous étions en production et servions de vrais clients.
Convaincre Vos Parties Prenantes d’Essayer Quelque Chose de Nouveau
Si vous pensez à découper un nouveau système depuis une grosse boule de boue, vous souffrez probablement de problèmes de fiabilité, de performance, de maintenabilité, ou des trois simultanément. Des problèmes profonds et insolubles appellent des mesures drastiques !
Nous recommandons la modélisation de domaine comme première étape. Dans de nombreux systèmes envahis, les ingénieurs, les propriétaires de produits et les clients ne parlent plus le même langage. Les parties prenantes métier parlent du système en termes abstraits, axés sur les processus, tandis que les développeurs sont forcés de parler du système tel qu’il existe physiquement dans son état sauvage et chaotique.
Comprendre comment modéliser votre domaine est une tâche complexe qui est le sujet de nombreux livres décents en soi. Nous aimons utiliser des techniques interactives comme l’Event Storming et la modélisation CRC, parce que les humains sont bons pour collaborer à travers le jeu. La modélisation d’événements est une autre technique qui rassemble les ingénieurs et les propriétaires de produits pour comprendre un système en termes de Commandes (Commands), requêtes et Événements (Events).
| Consultez www.eventmodeling.org et www.eventstorming.com pour d’excellents guides de modélisation visuelle de systèmes avec des Événements (Events). |
L’objectif est de pouvoir parler du système en utilisant le même langage ubiquitaire, de sorte que vous puissiez vous mettre d’accord sur où réside la complexité.
Nous avons trouvé beaucoup de valeur à traiter les problèmes de domaine comme des kata TDD. Par exemple, le premier code que nous avons écrit pour le service de disponibilité était le modèle de lot et de ligne de commande. Vous pouvez traiter cela comme un atelier à l’heure du déjeuner, ou comme une exploration au début d’un projet. Une fois que vous pouvez démontrer la valeur de la modélisation, il est plus facile de faire l’argument pour structurer le projet afin d’optimiser pour la modélisation.
Questions Que Nos Réviseurs Techniques Ont Posées Que Nous N’avons Pas Pu Intégrer en Prose
Voici quelques questions que nous avons entendues pendant la rédaction que nous n’avons pas pu trouver un bon endroit pour aborder ailleurs dans le livre :
- Dois-je faire tout cela d’un coup ? Puis-je juste faire un peu à la fois ?
-
Non, vous pouvez absolument adopter ces techniques petit à petit. Si vous avez un système existant, nous recommandons de construire une Couche de Service (Service Layer) pour essayer de garder l’orchestration en un seul endroit. Une fois que vous avez cela, il est beaucoup plus facile de pousser la logique dans le modèle et de pousser les préoccupations de bord comme la validation ou la gestion des erreurs aux points d’entrée.
Cela vaut la peine d’avoir une Couche de Service (Service Layer) même si vous avez encore un gros et désordonné ORM Django parce que c’est un moyen de commencer à comprendre les limites des opérations.
- Extraire les cas d’usage cassera beaucoup de mon code existant ; c’est trop enchevêtré
-
Copiez et collez simplement. C’est OK de causer plus de duplication à court terme. Pensez à cela comme un processus en plusieurs étapes. Votre code est dans un mauvais état maintenant, donc copiez et collez-le dans un nouvel endroit et ensuite rendez ce nouveau code propre et ordonné.
Une fois que vous avez fait cela, vous pouvez remplacer les utilisations de l’ancien code par des appels à votre nouveau code et finalement supprimer le désordre. Réparer de grandes bases de code est un processus désordonné et douloureux. Ne vous attendez pas à ce que les choses s’améliorent instantanément, et ne vous inquiétez pas si certaines parties de votre application restent désordonnées.
- Dois-je faire du CQRS (Command Query Responsibility Segregation) ? Ça sonne bizarre. Ne puis-je pas juste utiliser des Dépôts (Repositories) ?
-
Bien sûr que vous pouvez ! Les techniques que nous présentons dans ce livre sont destinées à rendre votre vie plus facile. Ce n’est pas une sorte de discipline ascétique avec laquelle vous punir.
Dans le système d’étude de cas espace de travail/documents, nous avions beaucoup d’objets View Builder qui utilisaient des Dépôts (Repositories) pour récupérer des données et effectuaient ensuite quelques transformations pour retourner des modèles de lecture muets. L’avantage est que quand vous rencontrez un problème de performance, il est facile de réécrire un view builder pour utiliser des requêtes personnalisées ou du SQL brut.
- Comment les cas d’usage devraient-ils interagir à travers un système plus large ? Est-ce un problème pour l’un d’appeler un autre ?
-
Cela pourrait être une étape intermédiaire. Encore une fois, dans l’étude de cas documents, nous avions des Gestionnaires (Handlers) qui auraient besoin d’invoquer d’autres Gestionnaires (Handlers). Cela devient vraiment désordonné, cependant, et il est beaucoup mieux de passer à l’utilisation d’un Bus de Messages (Message Bus) pour séparer ces préoccupations.
Généralement, votre système aura une seule implémentation de Bus de Messages (Message Bus) et un tas de sous-domaines qui se centrent sur un Agrégat (Aggregate) particulier ou un ensemble d’Agrégats (Aggregates). Quand votre cas d’usage est terminé, il peut lever un Événement (Event), et un Gestionnaire (Handler) ailleurs peut s’exécuter.
- Est-ce une odeur de code pour un cas d’usage d’utiliser plusieurs Dépôts (Repositories)/Agrégats (Aggregates), et si oui, pourquoi ?
-
Un Agrégat (Aggregate) est une limite de cohérence, donc si votre cas d’usage doit mettre à jour deux Agrégats (Aggregates) atomiquement (dans la même transaction), alors votre limite de cohérence est incorrecte, strictement parlant. Idéalement vous devriez penser à passer à un nouvel Agrégat (Aggregate) qui enveloppe toutes les choses que vous voulez changer en même temps.
Si vous mettez à jour réellement seulement un Agrégat (Aggregate) et utilisez l’autre (les autres) pour l’accès en lecture seule, alors c’est bien, bien que vous pourriez considérer construire un modèle de lecture/vue pour obtenir ces données à la place—cela rend les choses plus propres si chaque cas d’usage a seulement un Agrégat (Aggregate).
Si vous avez besoin de modifier deux Agrégats (Aggregates), mais les deux opérations n’ont pas besoin d’être dans la même transaction/UoW, alors considérez diviser le travail en deux Gestionnaires (Handlers) différents et utiliser un Événement de Domaine (Domain Event) pour transporter l’information entre les deux. Vous pouvez en lire plus dans ces articles sur la conception d’Agrégats (Aggregates) par Vaughn Vernon.
- Que faire si j’ai un système en lecture seule mais lourd en logique métier ?
-
Les modèles de vue peuvent avoir une logique complexe en eux. Dans ce livre, nous vous avons encouragé à séparer vos modèles de lecture et d’écriture parce qu’ils ont des exigences de cohérence et de débit différentes. Principalement, nous pouvons utiliser une logique plus simple pour les lectures, mais ce n’est pas toujours vrai. En particulier, les modèles de permissions et d’autorisation peuvent ajouter beaucoup de complexité à notre côté lecture.
Nous avons écrit des systèmes dans lesquels les modèles de vue nécessitaient des tests unitaires extensifs. Dans ces systèmes, nous avons divisé un view builder d’un view fetcher, comme dans Un view builder et view fetcher (vous pouvez trouver une version haute résolution de ce diagramme sur cosmicpython.com).
[plantuml, apwp_ep06, config=plantuml.cfg] @startuml View Fetcher Component Diagram !include images/C4_Component.puml ComponentDb(db, "Database", "RDBMS") Component(fetch, "View Fetcher", "Reads data from db, returning list of tuples or dicts") Component(build, "View Builder", "Filters and maps tuples") Component(api, "API", "Handles HTTP and serialization concerns") Rel(api, build, "Invokes") Rel_R(build, fetch, "Invokes") Rel_D(fetch, db, "Reads data from") @enduml
+ Cela rend facile de tester le view builder en lui donnant des données mockées (par ex., une liste de dicts). "Le CQRS (Command Query Responsibility Segregation) sophistiqué" avec des Gestionnaires (Handlers) d’événements est vraiment une façon d’exécuter notre logique de vue complexe chaque fois que nous écrivons afin que nous puissions éviter de l’exécuter quand nous lisons.
- Dois-je construire des microservices pour faire ces choses ?
-
Bon sang, non ! Ces techniques précèdent les microservices d’une décennie environ. Les Agrégats (Aggregates), les Événements de Domaine (Domain Events) et l’Inversion de Dépendances (Dependency Inversion) sont des façons de contrôler la complexité dans les grands systèmes. Il se trouve que quand vous avez construit un ensemble de cas d’usage et un modèle pour un processus métier, le déplacer vers son propre service est relativement facile, mais ce n’est pas une exigence.
- J’utilise Django. Puis-je encore faire cela ?
-
Nous avons une annexe entière juste pour vous : Motifs Dépôt (Repository) et Unité de Travail (Unit of Work) avec Django !
Pièges
OK, donc nous vous avons donné tout un tas de nouveaux jouets avec lesquels jouer. Voici les petits caractères. Harry et Bob ne recommandent pas que vous copiez et colliez notre code dans un système de production et reconstruisiez votre plateforme de trading automatisé sur Redis pub/sub. Pour des raisons de brièveté et de simplicité, nous avons esquivé beaucoup de sujets délicats. Voici une liste de choses que nous pensons que vous devriez savoir avant d’essayer cela pour de vrai.
- La messagerie fiable est difficile
-
Redis pub/sub n’est pas fiable et ne devrait pas être utilisé comme un outil de messagerie à usage général. Nous l’avons choisi parce qu’il est familier et facile à exécuter. Chez MADE, nous exécutons Event Store comme notre outil de messagerie, mais nous avons eu de l’expérience avec RabbitMQ et Amazon EventBridge.
Tyler Treat a d’excellents articles de blog sur son site bravenewgeek.com ; vous devriez au moins lire "You Cannot Have Exactly-Once Delivery" et "What You Want Is What You Don’t: Understanding Trade-Offs in Distributed Messaging".
- Nous choisissons explicitement des transactions petites et ciblées qui peuvent échouer indépendamment
-
Dans Événements et Bus de Messages (Events and the Message Bus), nous mettons à jour notre processus de sorte que désallouer une ligne de commande et réallouer la ligne se produisent dans deux Unités de Travail (Units of Work) séparées. Vous aurez besoin de surveillance pour savoir quand ces transactions échouent, et d’outils pour rejouer les Événements (Events). Une partie de cela est rendue plus facile en utilisant un journal de transaction comme votre courtier de messages (par ex., Kafka ou EventStore). Vous pourriez aussi regarder le pattern Outbox.
- Nous ne discutons pas de l’idempotence
-
Nous n’avons pas vraiment réfléchi à ce qui se passe quand les Gestionnaires (Handlers) sont réessayés. En pratique vous voudrez rendre les Gestionnaires (Handlers) idempotents afin que les appeler de manière répétée avec le même message ne fasse pas de changements répétés à l’état. C’est une technique clé pour construire la fiabilité, parce qu’elle nous permet de réessayer en toute sécurité les Événements (Events) quand ils échouent.
Il y a beaucoup de bon matériel sur la gestion de messages idempotente, essayez de commencer avec "How to Ensure Idempotency in an Eventual Consistent DDD/CQRS Application" et "(Un)Reliability in Messaging".
- Vos Événements (Events) auront besoin de changer leur schéma au fil du temps
-
Vous devrez trouver un moyen de documenter vos Événements (Events) et de partager le schéma avec les consommateurs. Nous aimons utiliser le schéma JSON et le markdown parce que c’est simple mais il y a d’autres pratiques antérieures. Greg Young a écrit un livre entier sur la gestion des systèmes événementiels au fil du temps : Versioning in an Event Sourced System (Leanpub).
Plus de Lectures Requises
Quelques livres de plus que nous aimerions recommander pour vous aider sur votre chemin :
-
Clean Architectures in Python par Leonardo Giordani (Leanpub), qui est sorti en 2019, est l’un des rares livres précédents sur l’architecture d’application en Python.
-
Enterprise Integration Patterns par Gregor Hohpe et Bobby Woolf (Addison-Wesley Professional) est un assez bon début pour les patterns de messagerie.
-
Monolith to Microservices par Sam Newman (O’Reilly), et le premier livre de Newman, Building Microservices (O’Reilly). Le pattern Strangler Fig est mentionné comme un favori, parmi beaucoup d’autres. Ceux-ci sont bons à consulter si vous pensez à passer aux microservices, et ils sont aussi bons sur les patterns d’intégration et les considérations d'intégration basée sur la messagerie asynchrone.
Conclusion
Ouf ! C’est beaucoup d’avertissements et de suggestions de lecture ; nous espérons que nous ne vous avons pas complètement effrayé. Notre objectif avec ce livre est de vous donner juste assez de connaissances et d’intuition pour que vous commenciez à construire une partie de cela par vous-même. Nous aimerions entendre comment vous vous en sortez et quels problèmes vous rencontrez avec les techniques dans vos propres systèmes, alors pourquoi ne pas entrer en contact avec nous sur www.cosmicpython.com ?
Appendix B: Diagramme de Synthèse et Tableau
Voici à quoi ressemble notre architecture à la fin du livre :
Les composants de notre architecture et ce qu’ils font récapitule chaque patron et ce qu’il fait.
| Couche | Composant | Description |
|---|---|---|
Domaine Définit la logique métier. |
Entité (Entity) |
Un objet de domaine dont les attributs peuvent changer mais qui a une identité reconnaissable au fil du temps. |
Objet Valeur (Value Object) |
Un objet de domaine immuable dont les attributs le définissent entièrement. Il est interchangeable avec d’autres objets identiques. |
|
Agrégat (Aggregate) |
Groupe d’objets associés que nous traitons comme une unité dans le but de modifier des données. Définit et impose une limite de cohérence. |
|
Événement (Event) |
Représente quelque chose qui s’est produit. |
|
Commande (Command) |
Représente un travail que le système doit effectuer. |
|
Couche de Service (Service Layer) Définit les tâches que le système doit effectuer et orchestre les différents composants. |
Gestionnaire (Handler) |
Reçoit une commande ou un événement et effectue ce qui doit se passer. |
Unité de Travail (Unit of Work) |
Abstraction autour de l’intégrité des données. Chaque unité de travail représente une mise à jour atomique. Rend les dépôts disponibles. Suit les nouveaux événements sur les agrégats récupérés. |
|
Bus de Messages (Message Bus) interne |
Gère les commandes et les événements en les acheminant vers le gestionnaire approprié. |
|
Adaptateurs (Adapters) (Secondaires) Implémentations concrètes d’une interface qui va de notre système vers le monde extérieur (I/O). |
Dépôt (Repository) |
Abstraction autour du stockage persistant. Chaque agrégat a son propre dépôt. |
Éditeur d’Événements (Event Publisher) |
Pousse les événements sur le bus de messages externe. |
|
Points d’Entrée (Entrypoints) (Adaptateurs Primaires) Traduisent les entrées externes en appels vers la couche de service. |
Web |
Reçoit les requêtes web et les traduit en commandes, en les transmettant au bus de messages interne. |
Consommateur d’Événements (Event Consumer) |
Lit les événements du bus de messages externe et les traduit en commandes, en les transmettant au bus de messages interne. |
|
N/A |
Bus de Messages Externe (Message Broker) |
Un élément d’infrastructure que différents services utilisent pour intercommuniquer, via des événements. |
Appendix C: Une Structure de Projet Modèle
Aux alentours du Notre Premier Cas d’Usage (Use Case) : API Flask et Couche de Service (Service Layer), nous sommes passés d’une situation où tout était dans un seul dossier à une arborescence plus structurée, et nous avons pensé qu’il pourrait être intéressant de décrire les différentes parties.
|
Le code pour cet appendice se trouve dans la branche appendix_project_structure sur GitHub: git clone https://github.com/cosmicpython/code.git cd code git checkout appendix_project_structure |
La structure de dossiers de base ressemble à ceci:
.
├── Dockerfile (1)
├── Makefile (2)
├── README.md
├── docker-compose.yml (1)
├── license.txt
├── mypy.ini
├── requirements.txt
├── src (3)
│ ├── allocation
│ │ ├── __init__.py
│ │ ├── adapters
│ │ │ ├── __init__.py
│ │ │ ├── orm.py
│ │ │ └── repository.py
│ │ ├── config.py
│ │ ├── domain
│ │ │ ├── __init__.py
│ │ │ └── model.py
│ │ ├── entrypoints
│ │ │ ├── __init__.py
│ │ │ └── flask_app.py
│ │ └── service_layer
│ │ ├── __init__.py
│ │ └── services.py
│ └── setup.py (3)
└── tests (4)
├── conftest.py (4)
├── e2e
│ └── test_api.py
├── integration
│ ├── test_orm.py
│ └── test_repository.py
├── pytest.ini (4)
└── unit
├── test_allocate.py
├── test_batches.py
└── test_services.py| 1 | Notre docker-compose.yml et notre Dockerfile sont les principaux éléments de configuration pour les conteneurs qui exécutent notre application, et ils peuvent également exécuter les tests (pour la CI). Un projet plus complexe pourrait avoir plusieurs Dockerfiles, bien que nous ayons constaté que minimiser le nombre d’images est généralement une bonne idée.[35] |
| 2 | Un Makefile fournit le point d’entrée pour toutes les commandes typiques qu’un développeur
(ou un serveur CI) pourrait vouloir exécuter pendant son flux de travail normal: make
build, make test, et ainsi de suite.[36] Ceci est optionnel. Vous pourriez simplement utiliser
docker-compose et pytest directement, mais au minimum, c’est agréable d'
avoir toutes les "commandes courantes" dans une liste quelque part, et contrairement à
la documentation, un Makefile est du code donc il a moins tendance à devenir obsolète. |
| 3 | Tout le code source de notre application, y compris le modèle de domaine (domain model), l'
application Flask, et le code d’infrastructure, vit dans un package Python à l’intérieur de
src,[37]
que nous installons en utilisant pip install -e et le fichier setup.py. Cela rend
les imports faciles. Actuellement, la structure à l’intérieur de ce module est totalement plate,
mais pour un projet plus complexe, vous vous attendriez à développer une hiérarchie de dossiers
qui inclurait domain_model/, infrastructure/, services/, et api/. |
| 4 | Les tests vivent dans leur propre dossier. Les sous-dossiers distinguent différents types de tests et vous permettent de les exécuter séparément. Nous pouvons conserver les fixtures partagées (conftest.py) dans le dossier principal des tests et imbriquer des plus spécifiques si nous le souhaitons. C’est également l’endroit pour conserver pytest.ini. |
| La documentation pytest est vraiment bonne sur la disposition des tests et l’importabilité. |
Examinons quelques-uns de ces fichiers et concepts plus en détail.
C.1. Variables d’Environnement, 12-Factor, et Configuration, À l’Intérieur et À l’Extérieur des Conteneurs
Le problème de base que nous essayons de résoudre ici est que nous avons besoin de différents paramètres de configuration pour les cas suivants:
-
Exécuter du code ou des tests directement depuis votre propre machine de développement, peut-être en communiquant avec des ports mappés depuis des conteneurs Docker
-
Exécuter sur les conteneurs eux-mêmes, avec des ports et noms d’hôtes "réels"
-
Différents environnements de conteneurs (dev, staging, prod, etc.)
La configuration via des variables d’environnement comme suggéré par le manifeste 12-factor résoudra ce problème, mais concrètement, comment l’implémentons-nous dans notre code et nos conteneurs?
C.2. Config.py
Chaque fois que notre code applicatif a besoin d’accéder à une configuration, il va l’obtenir depuis un fichier appelé config.py. Voici quelques exemples de notre application:
import os
def get_postgres_uri(): (1)
host = os.environ.get("DB_HOST", "localhost") (2)
port = 54321 if host == "localhost" else 5432
password = os.environ.get("DB_PASSWORD", "abc123")
user, db_name = "allocation", "allocation"
return f"postgresql://{user}:{password}@{host}:{port}/{db_name}"
def get_api_url():
host = os.environ.get("API_HOST", "localhost")
port = 5005 if host == "localhost" else 80
return f"http://{host}:{port}"| 1 | Nous utilisons des fonctions pour obtenir la configuration actuelle, plutôt que des constantes
disponibles au moment de l’import, car cela permet au code client de modifier
os.environ si nécessaire. |
| 2 | config.py définit également certains paramètres par défaut, conçus pour fonctionner lors de l’exécution du code depuis la machine locale du développeur.[38] |
Un package Python élégant appelé environ-config mérite d’être examiné si vous êtes fatigué de créer manuellement vos propres fonctions de configuration basées sur l’environnement.
| Ne laissez pas ce module de configuration devenir un dépotoir rempli de choses seulement vaguement liées à la configuration et qui est ensuite importé partout. Gardez les choses immuables et modifiez-les uniquement via des variables d’environnement. Si vous décidez d’utiliser un script d’amorçage (bootstrap), vous pouvez en faire le seul endroit (autre que les tests) où la configuration est importée. |
C.3. Docker-Compose et Configuration des Conteneurs
Nous utilisons un outil léger d’orchestration de conteneurs Docker appelé docker-compose. Sa configuration principale se fait via un fichier YAML (soupir):[39]
version: "3"
services:
app: (1)
build:
context: .
dockerfile: Dockerfile
depends_on:
- postgres
environment: (3)
- DB_HOST=postgres (4)
- DB_PASSWORD=abc123
- API_HOST=app
- PYTHONDONTWRITEBYTECODE=1 (5)
volumes: (6)
- ./src:/src
- ./tests:/tests
ports:
- "5005:80" (7)
postgres:
image: postgres:9.6 (2)
environment:
- POSTGRES_USER=allocation
- POSTGRES_PASSWORD=abc123
ports:
- "54321:5432"| 1 | Dans le fichier docker-compose, nous définissons les différents services (conteneurs) dont nous avons besoin pour notre application. Habituellement, une image principale contient tout notre code, et nous pouvons l’utiliser pour exécuter notre API, nos tests, ou tout autre service qui nécessite un accès au modèle de domaine. |
| 2 | Vous aurez probablement d’autres services d’infrastructure, y compris une base de données. En production, vous pourriez ne pas utiliser de conteneurs pour cela; vous pourriez avoir un fournisseur cloud à la place, mais docker-compose nous donne un moyen de produire un service similaire pour le développement ou la CI. |
| 3 | La section environment vous permet de définir les variables d’environnement pour vos
conteneurs, les noms d’hôtes et ports tels qu’ils sont vus depuis l’intérieur du cluster Docker.
Si vous avez suffisamment de conteneurs pour que les informations commencent à être dupliquées dans
ces sections, vous pouvez utiliser environment_file à la place. Nous appelons généralement
le nôtre container.env. |
| 4 | À l’intérieur d’un cluster, docker-compose configure le réseau de sorte que les conteneurs soient disponibles les uns pour les autres via des noms d’hôtes nommés d’après leur nom de service. |
| 5 | Astuce pro: si vous montez des volumes pour partager des dossiers sources entre votre
machine de développement locale et le conteneur, la variable d’environnement PYTHONDONTWRITEBYTECODE
indique à Python de ne pas écrire de fichiers .pyc, et cela vous évitera d'
avoir des millions de fichiers appartenant à root dispersés partout dans votre système de fichiers local,
qui sont tous ennuyeux à supprimer et causent en plus des erreurs bizarres du compilateur Python. |
| 6 | Monter notre code source et de test en tant que volumes signifie que nous n’avons pas besoin de reconstruire
nos conteneurs à chaque fois que nous faisons un changement de code. |
| 7 | La section ports nous permet d’exposer les ports de l’intérieur des conteneurs
vers le monde extérieur[40]—ceux-ci correspondent aux ports par défaut que nous définissons
dans config.py. |
À l’intérieur de Docker, les autres conteneurs sont disponibles via des noms d’hôtes nommés d’après
leur nom de service. À l’extérieur de Docker, ils sont disponibles sur localhost, au
port défini dans la section ports.
|
C.4. Installer Votre Source en Tant que Package
Tout notre code applicatif (tout sauf les tests, en réalité) vit à l’intérieur d’un dossier src:
├── src
│ ├── allocation (1)
│ │ ├── config.py
│ │ └── ...
│ └── setup.py (2)| 1 | Les sous-dossiers définissent les noms de modules de niveau supérieur. Vous pouvez en avoir plusieurs si vous le souhaitez. |
| 2 | Et setup.py est le fichier dont vous avez besoin pour le rendre installable avec pip, montré ci-dessous. |
from setuptools import setup
setup(
name="allocation", version="0.1", packages=["allocation"],
)C’est tout ce dont vous avez besoin. packages= spécifie les noms des sous-dossiers que vous
voulez installer en tant que modules de niveau supérieur. L’entrée name est juste cosmétique, mais
elle est requise. Pour un package qui ne va jamais vraiment arriver sur PyPI, cela
suffira.[41]
C.5. Dockerfile
Les Dockerfiles vont être très spécifiques au projet, mais voici quelques étapes clés auxquelles vous vous attendez à voir:
FROM python:3.9-slim-buster
(1)
# RUN apt install gcc libpq (plus nécessaire car nous utilisons psycopg2-binary)
(2)
COPY requirements.txt /tmp/
RUN pip install -r /tmp/requirements.txt
(3)
RUN mkdir -p /src
COPY src/ /src/
RUN pip install -e /src
COPY tests/ /tests/
(4)
WORKDIR /src
ENV FLASK_APP=allocation/entrypoints/flask_app.py FLASK_DEBUG=1 PYTHONUNBUFFERED=1
CMD flask run --host=0.0.0.0 --port=80| 1 | Installation des dépendances au niveau système |
| 2 | Installation de nos dépendances Python (vous voudrez peut-être séparer vos dépendances de développement de celles de production; nous ne l’avons pas fait ici, par souci de simplicité) |
| 3 | Copie et installation de notre source |
| 4 | Configuration optionnelle d’une commande de démarrage par défaut (vous la remplacerez probablement beaucoup depuis la ligne de commande) |
| Une chose à noter est que nous installons les choses dans l’ordre de leur fréquence de changement probable. Cela nous permet de maximiser la réutilisation du cache de construction Docker. Je ne peux pas vous dire combien de douleur et de frustration sous-tend cette leçon. Pour cela et bien d’autres conseils d’amélioration de Dockerfile Python, consultez "Production-Ready Docker Packaging". |
C.6. Tests
Nos tests sont conservés à côté de tout le reste, comme montré ici:
└── tests
├── conftest.py
├── e2e
│ └── test_api.py
├── integration
│ ├── test_orm.py
│ └── test_repository.py
├── pytest.ini
└── unit
├── test_allocate.py
├── test_batches.py
└── test_services.pyRien de particulièrement ingénieux ici, juste une certaine séparation des différents types de tests que vous voudrez probablement exécuter séparément, et quelques fichiers pour les fixtures communes, la configuration, et ainsi de suite.
Il n’y a pas de dossier src ou setup.py dans les dossiers de tests car nous n’avons généralement pas eu besoin de rendre les tests installables avec pip, mais si vous avez des difficultés avec les chemins d’import, vous pourriez constater que cela aide.
C.7. Récapitulatif
Voici nos blocs de construction de base:
-
Code source dans un dossier src, installable avec pip en utilisant setup.py
-
Une configuration Docker pour créer un cluster local qui reflète la production autant que possible
-
Configuration via des variables d’environnement, centralisée dans un fichier Python appelé config.py, avec des défauts permettant aux choses de s’exécuter en dehors des conteneurs
-
Un Makefile pour des commandes utiles en ligne de commande, euh, des commandes
Nous doutons que quiconque finisse avec exactement les mêmes solutions que nous, mais nous espérons que vous trouverez ici une certaine inspiration.
Appendix D: Remplacer l’Infrastructure : Tout Faire avec des CSVs
Cette annexe est destinée à illustrer les bénéfices des patterns Repository, Unit of Work et Service Layer. Elle est prévue pour faire suite au Motif Unité de Travail (Unit of Work Pattern).
Juste au moment où nous finissons de construire notre API Flask et de la préparer pour la mise en production, l’équipe métier vient nous voir avec des excuses, disant qu’ils ne sont pas prêts à utiliser notre API et nous demandant si nous pourrions construire quelque chose qui lit simplement les lots et les commandes depuis quelques CSVs et produit un troisième CSV avec les allocations.
Normalement, c’est le genre de chose qui pourrait faire jurer et cracher une
équipe en prenant des notes pour ses mémoires. Mais pas nous ! Oh non, nous
avons assuré que nos préoccupations d’infrastructure sont bien découplées de
notre modèle de domaine et de notre couche de service. Passer aux CSVs sera
une simple question d’écrire quelques nouvelles classes Repository et
UnitOfWork, et ensuite nous pourrons réutiliser toute notre logique de
la couche domaine et de la couche de service.
Voici un test E2E pour vous montrer comment les CSVs entrent et sortent :
def test_cli_app_reads_csvs_with_batches_and_orders_and_outputs_allocations(make_csv):
sku1, sku2 = random_ref("s1"), random_ref("s2")
batch1, batch2, batch3 = random_ref("b1"), random_ref("b2"), random_ref("b3")
order_ref = random_ref("o")
make_csv("batches.csv", [
["ref", "sku", "qty", "eta"],
[batch1, sku1, 100, ""],
[batch2, sku2, 100, "2011-01-01"],
[batch3, sku2, 100, "2011-01-02"],
])
orders_csv = make_csv("orders.csv", [
["orderid", "sku", "qty"],
[order_ref, sku1, 3],
[order_ref, sku2, 12],
])
run_cli_script(orders_csv.parent)
expected_output_csv = orders_csv.parent / "allocations.csv"
with open(expected_output_csv) as f:
rows = list(csv.reader(f))
assert rows == [
["orderid", "sku", "qty", "batchref"],
[order_ref, sku1, "3", batch1],
[order_ref, sku2, "12", batch2],
]En se lançant et en implémentant sans penser aux dépôts et à tout ce jazz, vous pourriez commencer avec quelque chose comme ça :
#!/usr/bin/env python
import csv
import sys
from datetime import datetime
from pathlib import Path
from allocation.domain import model
def load_batches(batches_path):
# Charge les lots depuis le fichier CSV
batches = []
with batches_path.open() as inf:
reader = csv.DictReader(inf)
for row in reader:
if row["eta"]:
eta = datetime.strptime(row["eta"], "%Y-%m-%d").date()
else:
eta = None
batches.append(
model.Batch(
ref=row["ref"], sku=row["sku"], qty=int(row["qty"]), eta=eta
)
)
return batches
def main(folder):
batches_path = Path(folder) / "batches.csv"
orders_path = Path(folder) / "orders.csv"
allocations_path = Path(folder) / "allocations.csv"
batches = load_batches(batches_path)
with orders_path.open() as inf, allocations_path.open("w") as outf:
reader = csv.DictReader(inf)
writer = csv.writer(outf)
writer.writerow(["orderid", "sku", "batchref"])
for row in reader:
orderid, sku = row["orderid"], row["sku"]
qty = int(row["qty"])
line = model.OrderLine(orderid, sku, qty)
batchref = model.allocate(line, batches)
writer.writerow([line.orderid, line.sku, batchref])
if __name__ == "__main__":
main(sys.argv[1])Ça n’a pas l’air trop mal ! Et nous réutilisons nos objets du modèle de domaine et notre service de domaine.
Mais ça ne va pas fonctionner. Les allocations existantes doivent également faire partie de notre stockage CSV permanent. Nous pouvons écrire un second test pour nous forcer à améliorer les choses :
def test_cli_app_also_reads_existing_allocations_and_can_append_to_them(make_csv):
sku = random_ref("s")
batch1, batch2 = random_ref("b1"), random_ref("b2")
old_order, new_order = random_ref("o1"), random_ref("o2")
make_csv("batches.csv", [
["ref", "sku", "qty", "eta"],
[batch1, sku, 10, "2011-01-01"],
[batch2, sku, 10, "2011-01-02"],
])
make_csv("allocations.csv", [
["orderid", "sku", "qty", "batchref"],
[old_order, sku, 10, batch1],
])
orders_csv = make_csv("orders.csv", [
["orderid", "sku", "qty"],
[new_order, sku, 7],
])
run_cli_script(orders_csv.parent)
expected_output_csv = orders_csv.parent / "allocations.csv"
with open(expected_output_csv) as f:
rows = list(csv.reader(f))
assert rows == [
["orderid", "sku", "qty", "batchref"],
[old_order, sku, "10", batch1],
[new_order, sku, "7", batch2],
]Et nous pourrions continuer à bricoler et ajouter des lignes supplémentaires à
cette fonction load_batches, et une sorte de moyen de suivre et de sauvegarder
les nouvelles allocations—mais nous avons déjà un modèle pour faire ça ! Il
s’appelle nos patterns Repository et Unit of Work.
Tout ce que nous devons faire ("tout ce que nous devons faire") c’est réimplémenter ces mêmes abstractions, mais avec des CSVs en dessous au lieu d’une base de données. Et comme vous le verrez, c’est vraiment relativement simple.
D.1. Implémenter un Repository et une Unit of Work pour les CSVs
Voici à quoi pourrait ressembler un dépôt (repository) basé sur CSV. Il abstrait
toute la logique de lecture des CSVs depuis le disque, y compris le fait qu’il
doit lire deux CSVs différents (un pour les lots et un pour les allocations),
et il nous donne juste l’API familière .list(), qui fournit l’illusion d’une
collection en mémoire d’objets de domaine :
class CsvRepository(repository.AbstractRepository):
def __init__(self, folder):
self._batches_path = Path(folder) / "batches.csv"
self._allocations_path = Path(folder) / "allocations.csv"
self._batches = {} # type: Dict[str, model.Batch]
self._load()
def get(self, reference):
return self._batches.get(reference)
def add(self, batch):
self._batches[batch.reference] = batch
def _load(self):
# Charge les lots depuis le CSV
with self._batches_path.open() as f:
reader = csv.DictReader(f)
for row in reader:
ref, sku = row["ref"], row["sku"]
qty = int(row["qty"])
if row["eta"]:
eta = datetime.strptime(row["eta"], "%Y-%m-%d").date()
else:
eta = None
self._batches[ref] = model.Batch(ref=ref, sku=sku, qty=qty, eta=eta)
if self._allocations_path.exists() is False:
return
# Charge les allocations existantes depuis le CSV
with self._allocations_path.open() as f:
reader = csv.DictReader(f)
for row in reader:
batchref, orderid, sku = row["batchref"], row["orderid"], row["sku"]
qty = int(row["qty"])
line = model.OrderLine(orderid, sku, qty)
batch = self._batches[batchref]
batch._allocations.add(line)
def list(self):
return list(self._batches.values())Et voici à quoi ressemblerait une UoW pour les CSVs :
class CsvUnitOfWork(unit_of_work.AbstractUnitOfWork):
def __init__(self, folder):
self.batches = CsvRepository(folder)
def commit(self):
# Écrit toutes les allocations dans le CSV
with self.batches._allocations_path.open("w") as f:
writer = csv.writer(f)
writer.writerow(["orderid", "sku", "qty", "batchref"])
for batch in self.batches.list():
for line in batch._allocations:
writer.writerow(
[line.orderid, line.sku, line.qty, batch.reference]
)
def rollback(self):
passEt une fois que nous avons ça, notre application CLI pour lire et écrire les lots et allocations vers CSV est réduite à ce qu’elle devrait être—un peu de code pour lire les lignes de commande, et un peu de code qui invoque notre couche de service existante :
def main(folder):
orders_path = Path(folder) / "orders.csv"
uow = csv_uow.CsvUnitOfWork(folder)
with orders_path.open() as f:
reader = csv.DictReader(f)
for row in reader:
orderid, sku = row["orderid"], row["sku"]
qty = int(row["qty"])
services.allocate(orderid, sku, qty, uow)Ta-da ! Maintenant êtes-vous impressionnés ou quoi ?
Avec tout notre amour,
Bob et Harry
Appendix E: Motifs Dépôt (Repository) et Unité de Travail (Unit of Work) avec Django
Supposons que vous vouliez utiliser Django au lieu de SQLAlchemy et Flask. À quoi ressembleraient les choses ? La première chose est de choisir où l’installer. Nous le mettons dans un package séparé à côté de notre code principal d’allocation :
├── src
│ ├── allocation
│ │ ├── __init__.py
│ │ ├── adapters
│ │ │ ├── __init__.py
...
│ ├── djangoproject
│ │ ├── alloc
│ │ │ ├── __init__.py
│ │ │ ├── apps.py
│ │ │ ├── migrations
│ │ │ │ ├── 0001_initial.py
│ │ │ │ └── __init__.py
│ │ │ ├── models.py
│ │ │ └── views.py
│ │ ├── django_project
│ │ │ ├── __init__.py
│ │ │ ├── settings.py
│ │ │ ├── urls.py
│ │ │ └── wsgi.py
│ │ └── manage.py
│ └── setup.py
└── tests
├── conftest.py
├── e2e
│ └── test_api.py
├── integration
│ ├── test_repository.py
...|
Le code pour cet appendice se trouve dans la branche appendix_django sur GitHub : git clone https://github.com/cosmicpython/code.git cd code git checkout appendix_django Les exemples de code font suite à la fin du Motif Unité de Travail (Unit of Work Pattern). |
E.1. Motif Dépôt (Repository) avec Django
Nous avons utilisé un plugin appelé
pytest-django pour aider à la gestion
de la base de données de test.
Réécrire le premier test de dépôt (repository) a été un changement minimal—juste réécrire un peu de SQL brut avec un appel au langage ORM/QuerySet de Django :
from djangoproject.alloc import models as django_models
@pytest.mark.django_db
def test_repository_can_save_a_batch():
batch = model.Batch("batch1", "RUSTY-SOAPDISH", 100, eta=date(2011, 12, 25))
repo = repository.DjangoRepository()
repo.add(batch)
[saved_batch] = django_models.Batch.objects.all()
assert saved_batch.reference == batch.reference
assert saved_batch.sku == batch.sku
assert saved_batch.qty == batch._purchased_quantity
assert saved_batch.eta == batch.etaLe deuxième test est un peu plus impliqué car il a des allocations, mais il est toujours composé de code Django d’apparence familière :
@pytest.mark.django_db
def test_repository_can_retrieve_a_batch_with_allocations():
sku = "PONY-STATUE"
d_line = django_models.OrderLine.objects.create(orderid="order1", sku=sku, qty=12)
d_batch1 = django_models.Batch.objects.create(
reference="batch1", sku=sku, qty=100, eta=None
)
d_batch2 = django_models.Batch.objects.create(
reference="batch2", sku=sku, qty=100, eta=None
)
django_models.Allocation.objects.create(line=d_line, batch=d_batch1)
repo = repository.DjangoRepository()
retrieved = repo.get("batch1")
expected = model.Batch("batch1", sku, 100, eta=None)
assert retrieved == expected # Batch.__eq__ compare uniquement la référence
assert retrieved.sku == expected.sku
assert retrieved._purchased_quantity == expected._purchased_quantity
assert retrieved._allocations == {
model.OrderLine("order1", sku, 12),
}Voici à quoi ressemble finalement le dépôt (repository) réel :
class DjangoRepository(AbstractRepository):
def add(self, batch):
super().add(batch)
self.update(batch)
def update(self, batch):
django_models.Batch.update_from_domain(batch)
def _get(self, reference):
return (
django_models.Batch.objects.filter(reference=reference)
.first()
.to_domain()
)
def list(self):
return [b.to_domain() for b in django_models.Batch.objects.all()]Vous pouvez voir que l’implémentation repose sur les modèles Django ayant des méthodes personnalisées pour traduire vers et depuis notre modèle de domaine (domain model).[42]
E.1.1. Méthodes personnalisées sur les classes ORM Django pour traduire vers/depuis notre Modèle de Domaine (Domain Model)
Ces méthodes personnalisées ressemblent à quelque chose comme ceci :
from django.db import models
from allocation.domain import model as domain_model
class Batch(models.Model):
reference = models.CharField(max_length=255)
sku = models.CharField(max_length=255)
qty = models.IntegerField()
eta = models.DateField(blank=True, null=True)
@staticmethod
def update_from_domain(batch: domain_model.Batch):
try:
b = Batch.objects.get(reference=batch.reference) (1)
except Batch.DoesNotExist:
b = Batch(reference=batch.reference) (1)
b.sku = batch.sku
b.qty = batch._purchased_quantity
b.eta = batch.eta (2)
b.save()
b.allocation_set.set(
Allocation.from_domain(l, b) (3)
for l in batch._allocations
)
def to_domain(self) -> domain_model.Batch:
b = domain_model.Batch(
ref=self.reference, sku=self.sku, qty=self.qty, eta=self.eta
)
b._allocations = set(
a.line.to_domain()
for a in self.allocation_set.all()
)
return b
class OrderLine(models.Model):
#...| 1 | Pour les objets valeur (value objects), objects.get_or_create peut fonctionner, mais pour les entités,
vous avez probablement besoin d’un try-get/except explicite pour gérer l’upsert.[43] |
| 2 | Nous avons montré l’exemple le plus complexe ici. Si vous décidez de faire cela, soyez conscient qu’il y aura du code passe-partout (boilerplate) ! Heureusement ce n’est pas un code passe-partout très complexe. |
| 3 | Les relations nécessitent également une gestion personnalisée soignée. |
| Comme dans Pattern Repository (Dépôt), nous utilisons l’inversion de dépendances (dependency inversion). L’ORM (Django) dépend du modèle et non l’inverse. |
E.2. Motif Unité de Travail (Unit of Work) avec Django
Les tests ne changent pas trop :
def insert_batch(ref, sku, qty, eta): (1)
django_models.Batch.objects.create(reference=ref, sku=sku, qty=qty, eta=eta)
def get_allocated_batch_ref(orderid, sku): (1)
return django_models.Allocation.objects.get(
line__orderid=orderid, line__sku=sku
).batch.reference
@pytest.mark.django_db(transaction=True)
def test_uow_can_retrieve_a_batch_and_allocate_to_it():
insert_batch("batch1", "HIPSTER-WORKBENCH", 100, None)
uow = unit_of_work.DjangoUnitOfWork()
with uow:
batch = uow.batches.get(reference="batch1")
line = model.OrderLine("o1", "HIPSTER-WORKBENCH", 10)
batch.allocate(line)
uow.commit()
batchref = get_allocated_batch_ref("o1", "HIPSTER-WORKBENCH")
assert batchref == "batch1"
@pytest.mark.django_db(transaction=True) (2)
def test_rolls_back_uncommitted_work_by_default():
...
@pytest.mark.django_db(transaction=True) (2)
def test_rolls_back_on_error():
...| 1 | Parce que nous avions de petites fonctions d’aide dans ces tests, les corps principaux réels des tests sont à peu près les mêmes qu’ils étaient avec SQLAlchemy. |
| 2 | Le pytest-django mark.django_db(transaction=True) est requis pour
tester nos comportements personnalisés de transaction/rollback. |
Et l’implémentation est assez simple, bien qu’il m’ait fallu quelques essais pour trouver quelle invocation de la magie de transaction de Django fonctionnerait :
class DjangoUnitOfWork(AbstractUnitOfWork):
def __enter__(self):
self.batches = repository.DjangoRepository()
transaction.set_autocommit(False) (1)
return super().__enter__()
def __exit__(self, *args):
super().__exit__(*args)
transaction.set_autocommit(True)
def commit(self):
for batch in self.batches.seen: (3)
self.batches.update(batch) (3)
transaction.commit() (2)
def rollback(self):
transaction.rollback() (2)| 1 | set_autocommit(False) était la meilleure façon de dire à Django d’arrêter
de valider automatiquement chaque opération ORM immédiatement, et de
commencer une transaction. |
| 2 | Ensuite nous utilisons les rollback et commits explicites. |
| 3 | Une difficulté : parce que, contrairement à SQLAlchemy, nous n’instrumentons pas
les instances du modèle de domaine elles-mêmes, la
commande commit() doit explicitement parcourir tous les
objets qui ont été touchés par chaque dépôt (repository) et les
mettre à jour manuellement vers l’ORM.
|
E.3. API : les vues Django sont des adaptateurs
Le fichier views.py de Django finit par être presque identique à l’ancien flask_app.py, car notre architecture signifie que c’est une enveloppe très fine autour de notre couche de service (service layer) (qui n’a d’ailleurs pas changé du tout) :
os.environ["DJANGO_SETTINGS_MODULE"] = "djangoproject.django_project.settings"
django.setup()
@csrf_exempt
def add_batch(request):
data = json.loads(request.body)
eta = data["eta"]
if eta is not None:
eta = datetime.fromisoformat(eta).date()
services.add_batch(
data["ref"], data["sku"], data["qty"], eta,
unit_of_work.DjangoUnitOfWork(),
)
return HttpResponse("OK", status=201)
@csrf_exempt
def allocate(request):
data = json.loads(request.body)
try:
batchref = services.allocate(
data["orderid"],
data["sku"],
data["qty"],
unit_of_work.DjangoUnitOfWork(),
)
except (model.OutOfStock, services.InvalidSku) as e:
return JsonResponse({"message": str(e)}, status=400)
return JsonResponse({"batchref": batchref}, status=201)E.4. Pourquoi était-ce si difficile ?
OK, ça fonctionne, mais on a vraiment l’impression que c’est plus d’effort que Flask/SQLAlchemy. Pourquoi est-ce le cas ?
La raison principale à un bas niveau est que l’ORM de Django ne fonctionne pas de la même
manière. Nous n’avons pas d’équivalent du mapper classique SQLAlchemy, donc notre
ActiveRecord et notre modèle de domaine (domain model) ne peuvent pas être le même objet. Au lieu de cela, nous devons
construire une couche de traduction manuelle derrière le dépôt (repository). C’est plus
de travail (bien qu’une fois que c’est fait, le fardeau de maintenance continu ne devrait pas être trop
élevé).
Parce que Django est si étroitement couplé à la base de données, vous devez utiliser des utilitaires
comme pytest-django et réfléchir attentivement aux bases de données de test, dès
la toute première ligne de code, d’une manière que nous n’avions pas à faire lorsque nous avons commencé
avec notre modèle de domaine pur.
Mais à un niveau plus élevé, la raison entière pour laquelle Django est si génial est qu’il est conçu autour du point idéal qui consiste à faciliter la construction d’applications CRUD avec un minimum de code passe-partout (boilerplate). Mais toute l’orientation de notre livre est de savoir quoi faire quand votre application n’est plus une simple application CRUD.
À ce stade, Django commence à gêner plus qu’il n’aide. Des choses comme l’admin Django, qui sont si impressionnantes quand vous commencez, deviennent activement dangereuses si tout le but de votre application est de construire un ensemble complexe de règles et de modélisation autour du flux de travail des changements d’état. L’admin Django contourne tout cela.
E.5. Que faire si vous avez déjà Django
Alors que devriez-vous faire si vous voulez appliquer certains des motifs de ce livre à une application Django ? Nous dirions ce qui suit :
-
Les motifs Dépôt (Repository) et Unité de Travail (Unit of Work) vont représenter pas mal de travail. La principale chose qu’ils vous apporteront à court terme est des tests unitaires plus rapides, donc évaluez si cet avantage vous semble valoir la peine dans votre cas. À plus long terme, ils découplent votre application de Django et de la base de données, donc si vous prévoyez de vouloir migrer de l’un ou l’autre, Repository et UoW sont une bonne idée.
-
Le motif Couche de Service (Service Layer) pourrait être intéressant si vous voyez beaucoup de duplication dans votre views.py. Cela peut être une bonne façon de penser à vos cas d’usage (use cases) séparément de vos points de terminaison web.
-
Vous pouvez toujours théoriquement faire du DDD et de la modélisation de domaine avec les modèles Django, aussi étroitement couplés qu’ils soient à la base de données ; vous pouvez être ralenti par les migrations, mais cela ne devrait pas être fatal. Donc tant que votre application n’est pas trop complexe et vos tests pas trop lents, vous pourrez peut-être obtenir quelque chose de l’approche modèles gros (fat models) : poussez autant de logique que possible vers vos modèles, et appliquez des motifs comme Entité (Entity), Objet Valeur (Value Object), et Agrégat (Aggregate). Cependant, voir la mise en garde suivante.
Cela dit, dans la communauté Django on constate que les gens trouvent que l’approche des modèles gros (fat models) rencontre ses propres problèmes d’évolutivité, particulièrement autour de la gestion des interdépendances entre applications. Dans ces cas, il y a beaucoup à dire pour extraire une couche de logique métier ou de domaine pour se situer entre vos vues et formulaires et votre models.py, que vous pouvez ensuite garder aussi minimal que possible.
E.6. Étapes en cours de route
Supposons que vous travailliez sur un projet Django dont vous n’êtes pas sûr qu’il va devenir assez complexe pour justifier les motifs que nous recommandons, mais vous voulez quand même mettre en place quelques étapes pour vous faciliter la vie, à la fois à moyen terme et si vous voulez migrer vers certains de nos motifs plus tard. Considérez ce qui suit :
-
Un conseil que nous avons entendu est de mettre un logic.py dans chaque application Django dès le premier jour. Cela vous donne un endroit où mettre la logique métier, et garder vos formulaires, vues et modèles exempts de logique métier. Cela peut devenir un tremplin pour passer à un modèle de domaine (domain model) entièrement découplé et/ou une couche de service (service layer) plus tard.
-
Une couche de logique métier pourrait commencer par travailler avec des objets de modèle Django et seulement plus tard devenir entièrement découplée du framework et travailler sur des structures de données Python simples.
-
Pour le côté lecture, vous pouvez obtenir certains des avantages du CQRS en mettant les lectures dans un seul endroit, évitant les appels ORM éparpillés partout.
-
Lorsque vous séparez les modules pour les lectures et les modules pour la logique de domaine, il peut être intéressant de vous découpler de la hiérarchie des applications Django. Les préoccupations métier vont les traverser.
| Nous aimerions remercier David Seddon et Ashia Zawaduk pour avoir discuté de certaines des idées de cet appendice. Ils ont fait de leur mieux pour nous empêcher de dire quelque chose de vraiment stupide sur un sujet dont nous n’avons vraiment pas assez d’expérience personnelle, mais ils ont peut-être échoué. |
Pour plus de réflexions et d’expérience vécue concrète sur la gestion d’applications existantes, référez-vous à l'épilogue.
Appendix F: Validation
Chaque fois que nous enseignons et parlons de ces techniques, une question qui revient sans cesse est "Où devrais-je faire la validation (validation) ? Cela appartient-il à ma logique métier dans le Modèle de Domaine (Domain Model), ou est-ce une préoccupation d’infrastructure ?"
Comme pour toute question architecturale, la réponse est : ça dépend !
La considération la plus importante est que nous voulons garder notre code bien séparé afin que chaque partie du système soit simple. Nous ne voulons pas encombrer notre code avec des détails non pertinents.
F.1. Qu’est-ce que la Validation, de toute façon ?
Lorsque les gens utilisent le mot validation, ils désignent généralement un processus par lequel ils testent les entrées d’une opération pour s’assurer qu’elles correspondent à certains critères. Les entrées qui correspondent aux critères sont considérées comme valides, et celles qui ne correspondent pas sont invalides.
Si l’entrée est invalide, l’opération ne peut pas continuer mais doit se terminer avec une sorte d’erreur. En d’autres termes, la validation consiste à créer des préconditions. Nous trouvons utile de séparer nos préconditions en trois sous-types : syntaxe, sémantique et pragmatique.
F.2. Validation de la Syntaxe
En linguistique, la syntaxe d’une langue est l’ensemble des règles qui régissent la
structure des phrases grammaticales. Par exemple, en français, la phrase
"Allouer trois unités de TASTELESS-LAMP à la commande vingt-sept" est grammaticalement
correcte, tandis que la phrase "chapeau chapeau chapeau chapeau chapeau chapeau baragouin" ne l’est pas. Nous pouvons décrire
les phrases grammaticalement correctes comme bien formées.
Comment cela se traduit-il dans notre application ? Voici quelques exemples de règles syntaxiques :
-
Une Commande (Command)
Allocatedoit avoir un ID de commande, un SKU et une quantité. -
Une quantité est un entier positif.
-
Un SKU est une chaîne de caractères.
Ce sont des règles concernant la forme et la structure des données entrantes. Une Commande Allocate
sans SKU ou sans ID de commande n’est pas un message valide. C’est l’équivalent
de la phrase "Allouer trois à."
Nous avons tendance à valider ces règles à la périphérie du système. Notre règle générale est qu’un Gestionnaire (Handler) de messages devrait toujours recevoir uniquement un message bien formé et contenant toutes les informations requises.
Une option consiste à mettre votre logique de validation sur le type de message lui-même :
from schema import And, Schema, Use
@dataclass
class Allocate(Command):
_schema = Schema({ (1)
'orderid': int,
sku: str,
qty: And(Use(int), lambda n: n > 0)
}, ignore_extra_keys=True)
orderid: str
sku: str
qty: int
@classmethod
def from_json(cls, data): (2)
data = json.loads(data)
return cls(**_schema.validate(data))| 1 | La bibliothèque schema nous permet de décrire la structure et la validation de nos messages d’une manière déclarative agréable. |
| 2 | La méthode from_json lit une chaîne en tant que JSON et la transforme en notre type
de message. |
Cela peut devenir répétitif, cependant, puisque nous devons spécifier nos champs deux fois, donc nous pourrions vouloir introduire une bibliothèque d’aide qui peut unifier la validation et la déclaration de nos types de messages :
def command(name, **fields): (1)
schema = Schema(And(Use(json.loads), fields), ignore_extra_keys=True)
cls = make_dataclass(name, fields.keys()) (2)
cls.from_json = lambda s: cls(**schema.validate(s)) (3)
return cls
def greater_than_zero(x):
return x > 0
quantity = And(Use(int), greater_than_zero) (4)
Allocate = command( (5)
orderid=int,
sku=str,
qty=quantity
)
AddStock = command(
sku=str,
qty=quantity| 1 | La fonction command prend un nom de message, plus des kwargs pour les champs de
la charge utile du message, où le nom du kwarg est le nom du champ et
la valeur est l’analyseur. |
| 2 | Nous utilisons la fonction make_dataclass du module dataclass pour créer dynamiquement
notre type de message. |
| 3 | Nous patchons la méthode from_json sur notre dataclass dynamique. |
| 4 | Nous pouvons créer des analyseurs réutilisables pour la quantité, le SKU, etc. pour garder les choses DRY. |
| 5 | Déclarer un type de message devient une ligne unique. |
Cela se fait au prix de la perte des types sur votre dataclass, donc gardez ce compromis à l’esprit.
F.3. Loi de Postel et le Patron du Lecteur Tolérant
La loi de Postel, ou le principe de robustesse, nous dit : "Soyez libéral dans ce que vous acceptez, et conservateur dans ce que vous émettez." Nous pensons que cela s’applique particulièrement bien dans le contexte de l’intégration avec nos autres systèmes. L’idée ici est que nous devrions être stricts chaque fois que nous envoyons des messages à d’autres systèmes, mais aussi indulgents que possible lorsque nous recevons des messages des autres.
Par exemple, notre système pourrait valider le format d’un SKU. Nous avons utilisé
des SKU inventés comme UNFORGIVING-CUSHION et MISBEGOTTEN-POUFFE. Ceux-ci suivent
un modèle simple : deux mots, séparés par des tirets, où le deuxième mot est le
type de produit et le premier mot est un adjectif.
Les développeurs adorent valider ce genre de chose dans leurs messages, et rejeter
tout ce qui ressemble à un SKU invalide. Cela cause d’horribles problèmes plus tard
lorsqu’un anarchiste lance un produit nommé COMFY-CHAISE-LONGUE ou lorsqu’un
cafouillage chez le fournisseur entraîne une livraison de CHEAP-CARPET-2.
Vraiment, en tant que système d’allocation, ce n’est pas nos affaires quel est le format d' un SKU. Tout ce dont nous avons besoin est un identifiant, donc nous pouvons simplement le décrire comme une chaîne de caractères. Cela signifie que le système d’approvisionnement peut changer le format quand il le souhaite, et nous n’en aurons cure.
Ce même principe s’applique aux numéros de commande, numéros de téléphone des clients, et bien plus encore. Pour la plupart, nous pouvons ignorer la structure interne des chaînes.
De même, les développeurs adorent valider les messages entrants avec des outils comme JSON Schema, ou construire des bibliothèques qui valident les messages entrants et les partagent entre les systèmes. Cela échoue également au test de robustesse.
Imaginons, par exemple, que le système d’approvisionnement ajoute de nouveaux champs au
message ChangeBatchQuantity qui enregistrent la raison du changement et l'
email de l’utilisateur responsable du changement.
Puisque ces champs n’importent pas au service d’allocation, nous devrions simplement
les ignorer. Nous pouvons le faire dans la bibliothèque schema en passant l’argument mot-clé
ignore_extra_keys=True.
Ce modèle, par lequel nous extrayons uniquement les champs qui nous intéressent et effectuons une validation minimale sur eux, est le Patron du Lecteur Tolérant (Tolerant Reader pattern).
| Validez aussi peu que possible. Lisez uniquement les champs dont vous avez besoin, et ne sur-spécifiez pas leur contenu. Cela aidera votre système à rester robuste lorsque d’autres systèmes changent au fil du temps. Résistez à la tentation de partager des définitions de messages entre les systèmes : au lieu de cela, facilitez la définition des données dont vous dépendez. Pour plus d’informations, consultez l’article de Martin Fowler sur le Patron du Lecteur Tolérant. |
F.4. Validation à la Périphérie
Plus tôt, nous avons dit que nous voulons éviter d’encombrer notre code avec des détails non pertinents. En particulier, nous ne voulons pas coder défensivement à l’intérieur de notre Modèle de Domaine. Au lieu de cela, nous voulons nous assurer que les requêtes sont connues pour être valides avant que notre Modèle de Domaine ou nos Gestionnaires de Cas d’Usage (Use Case) ne les voient. Cela aide notre code à rester propre et maintenable à long terme. Nous appelons parfois cela valider à la périphérie du système.
En plus de garder votre code propre et exempt de vérifications et d’assertions sans fin, gardez à l’esprit que des données invalides errant dans votre système sont une bombe à retardement ; plus elles vont profondément, plus elles peuvent causer de dégâts, et moins vous avez d’outils pour y répondre.
De retour dans Événements et Bus de Messages (Events and the Message Bus), nous avons dit que le Bus de Messages (Message Bus) était un excellent endroit pour mettre des préoccupations transversales, et la validation est un exemple parfait de cela. Voici comment nous pourrions modifier notre bus pour effectuer la validation pour nous :
class MessageBus:
def handle_message(self, name: str, body: str):
try:
message_type = next(mt for mt in EVENT_HANDLERS if mt.__name__ == name)
message = message_type.from_json(body)
self.handle([message])
except StopIteration:
raise KeyError(f"Unknown message name {name}")
except ValidationError as e:
logging.error(
f'invalid message of type {name}\n'
f'{body}\n'
f'{e}'
)
raise eVoici comment nous pourrions utiliser cette méthode depuis notre point de terminaison de l’API Flask :
@app.route("/change_quantity", methods=['POST'])
def change_batch_quantity():
try:
bus.handle_message('ChangeBatchQuantity', request.body)
except ValidationError as e:
return bad_request(e)
except exceptions.InvalidSku as e:
return jsonify({'message': str(e)}), 400
def bad_request(e: ValidationError):
return e.code, 400Et voici comment nous pourrions le brancher à notre processeur de messages asynchrone :
def handle_change_batch_quantity(m, bus: messagebus.MessageBus):
try:
bus.handle_message('ChangeBatchQuantity', m)
except ValidationError:
print('Skipping invalid message')
except exceptions.InvalidSku as e:
print(f'Unable to change stock for missing sku {e}')Remarquez que nos points d’entrée se concentrent uniquement sur la façon d’obtenir un message du monde extérieur et comment signaler le succès ou l’échec. Notre Bus de Messages prend soin de valider nos requêtes et de les acheminer vers le bon Gestionnaire, et nos Gestionnaires se concentrent exclusivement sur la logique de notre Cas d’Usage.
| Lorsque vous recevez un message invalide, il y a généralement peu de choses que vous pouvez faire sauf journaliser l’erreur et continuer. Chez MADE, nous utilisons des métriques pour compter le nombre de messages qu’un système reçoit, et combien d’entre eux sont traités avec succès, ignorés ou invalides. Nos outils de surveillance nous alerteront si nous voyons des pics dans les nombres de mauvais messages. |
F.5. Validation de la Sémantique
Alors que la syntaxe concerne la structure des messages, la sémantique est l’étude de la signification dans les messages. La phrase "Annuler pas de chiens de points de suspension quatre" est syntaxiquement valide et a la même structure que la phrase "Allouer une théière à la commande cinq," mais elle est dénuée de sens.
Nous pouvons lire ce blob JSON comme une Commande Allocate mais ne pouvons pas l'
exécuter avec succès, car c’est du non-sens :
{
"orderid": "superman",
"sku": "zygote",
"qty": -1
}Nous avons tendance à valider les préoccupations sémantiques au niveau du Gestionnaire de messages avec une sorte de programmation basée sur les contrats :
"""
Ce module contient les préconditions que nous appliquons à nos gestionnaires.
"""
class MessageUnprocessable(Exception): (1)
def __init__(self, message):
self.message = message
class ProductNotFound(MessageUnprocessable): (2)
""""
Cette exception est levée lorsque nous essayons d'effectuer une action sur un produit
qui n'existe pas dans notre base de données.
""""
def __init__(self, message):
super().__init__(message)
self.sku = message.sku
def product_exists(event, uow): (3)
product = uow.products.get(event.sku)
if product is None:
raise ProductNotFound(event)| 1 | Nous utilisons une classe de base commune pour les erreurs qui signifient qu’un message est invalide. |
| 2 | L’utilisation d’un type d’erreur spécifique pour ce problème facilite le signalement et
la gestion de l’erreur. Par exemple, il est facile de mapper ProductNotFound à un 404
dans Flask. |
| 3 | product_exists est une précondition. Si la condition est False, nous levons une
erreur. |
Cela garde le flux principal de notre logique dans la Couche de Service (Service Layer) propre et déclaratif :
# services.py
from allocation import ensure
def allocate(event, uow):
line = model.OrderLine(event.orderid, event.sku, event.qty)
with uow:
ensure.product_exists(event, uow)
product = uow.products.get(line.sku)
product.allocate(line)
uow.commit()Nous pouvons étendre cette technique pour nous assurer que nous appliquons les messages de manière idempotente. Par exemple, nous voulons nous assurer que nous n’insérons pas un lot de stock plus d’une fois.
Si on nous demande de créer un lot qui existe déjà, nous enregistrerons un avertissement et continuerons au message suivant :
class SkipMessage (Exception):
""""
Cette exception est levée lorsqu'un message ne peut pas être traité, mais qu'il n'y a pas de
comportement incorrect. Par exemple, nous pourrions recevoir le même message plusieurs
fois, ou nous pourrions recevoir un message qui est maintenant obsolète.
""""
def __init__(self, reason):
self.reason = reason
def batch_is_new(self, event, uow):
batch = uow.batches.get(event.batchid)
if batch is not None:
raise SkipMessage(f"Batch with id {event.batchid} already exists")L’introduction d’une exception SkipMessage nous permet de gérer ces cas de manière générique
dans notre Bus de Messages :
class MessageBus:
def handle_message(self, message):
try:
...
except SkipMessage as e:
logging.warn(f"Skipping message {message.id} because {e.reason}")Il y a quelques pièges à connaître ici. Premièrement, nous devons nous assurer que nous utilisons la même Unité de Travail (Unit of Work) que celle que nous utilisons pour la logique principale de notre Cas d’Usage. Sinon, nous nous exposons à des bugs de concurrence irritants.
Deuxièmement, nous devrions essayer d’éviter de mettre toute notre logique métier dans ces vérifications de préconditions. En règle générale, si une règle peut être testée à l’intérieur de notre Modèle de Domaine, alors elle devrait être testée dans le Modèle de Domaine.
F.6. Validation de la Pragmatique
La pragmatique est l’étude de la façon dont nous comprenons le langage en contexte. Après avoir analysé un message et saisi sa signification, nous devons encore le traiter dans un contexte. Par exemple, si vous recevez un commentaire sur une pull request disant : "Je pense que c’est très courageux," cela peut signifier que le réviseur admire votre courage—sauf s’il est britannique, auquel cas, il essaie de vous dire que ce que vous faites est follement risqué, et que seul un fou tenterait cela. Le contexte est tout.
| Une fois que vous avez validé la syntaxe et la sémantique de vos commandes aux bords de votre système, le domaine est l’endroit pour le reste de votre validation. La validation de la pragmatique est souvent une partie essentielle de vos règles métier. |
En termes logiciels, la pragmatique d’une opération est généralement gérée par le
Modèle de Domaine. Lorsque nous recevons un message comme "allouer trois millions d’unités de
SCARCE-CLOCK à la commande 76543," le message est syntaxiquement valide et
sémantiquement valide, mais nous sommes incapables de nous conformer car nous n’avons pas le stock
disponible.